Flink入门 Anonymous published on 2024-10-11 included in Big Data简介 Apache Flink是一个用于有状态的并行数据流的分布式计算系统,同时支持流式处理和批量处理。
JVM内存问题排查流程 Anonymous published on 2024-03-03 included in Java JVM确认问题现象 可以通过服务状态,监控面板、日志信息、监控工具(VisualVM)等,确认问题类型:
OSDI'10 《Finding a Needle in Haystack Facebook’s Photo Storage》 Anonymous published on 2023-12-08 included in Paper Reading业务量级 FaceBook存储超过2600亿张图片,20PB,一周存储10亿张,峰值每秒100W图片。一次性写、不修改、很少删除的图片数据。
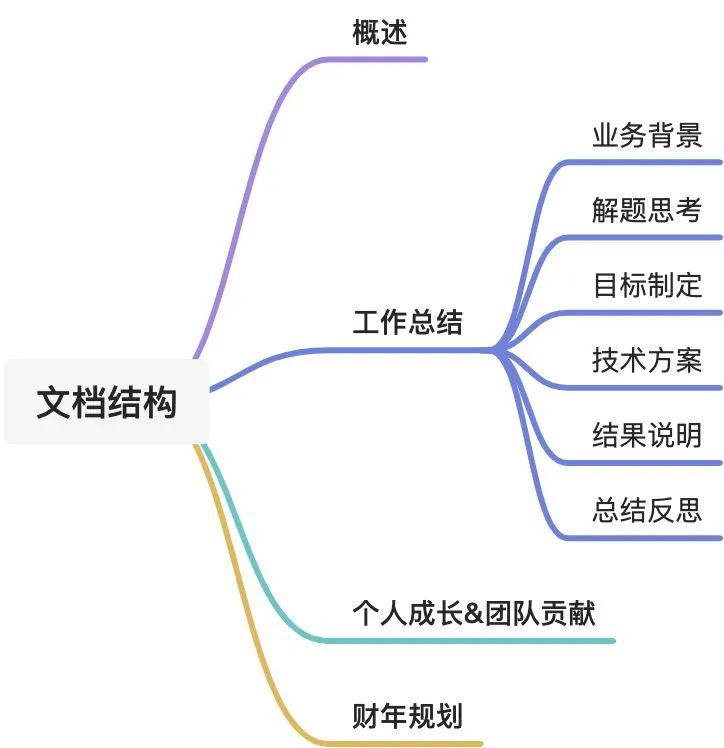
述职报告要点小记 Anonymous published on 2023-05-07 included in 随笔述职目的 企业:掌握员工的具体工作情况与表现。 个人:对自己的阶段性总结、反思、阶段规划 文档结构