Linux进程管理模块分析
二进制程序执行
编译过程
源代码文件会经过以下的步骤生成可执行文件(CSAPP):
- 预处理:预处理过程会将头文件嵌入代码中,定义宏展开,生成
.i文件 - 编译:编译生成汇编语言程序,生成
.s文件 - 汇编:汇编器as将汇编语言翻译成机器指令,打包成
.o文件,这被称为Relocatable File - 链接:链接器ld将链接库和重定位文件合并,生成可执行文件
编译
process.c内容如下:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
extern int create_process (char* program, char** arg_list);
int create_process (char* program, char** arg_list)
{
pid_t child_pid;
child_pid = fork ();
if (child_pid != 0)
return child_pid;
else {
execvp (program, arg_list);
abort ();
}createprocess.c内容如下:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
extern int create_process (char* program, char** arg_list);
int main ()
{
char* arg_list[] = {
"ls",
"-l",
"/opt/",
NULL
};
create_process ("ls", arg_list);
return 0;
}编译上面两个文件,生成.o文件
gcc -c -fPIC process.c
gcc -c -fPIC createprocess.c
drwxr-xr-x 2 root root 4096 Jul 12 18:29 ./
drwxr-xr-x 3 root root 4096 Jul 12 18:25 ../
-rw-r--r-- 1 root root 289 Jul 12 18:27 createprocess.c
-rw-r--r-- 1 root root 1888 Jul 12 18:29 createprocess.o
-rw-r--r-- 1 root root 373 Jul 12 18:28 process.c
-rw-r--r-- 1 root root 1712 Jul 12 18:28 process.oLinux中的二进制文件格式为ELF(Executeable and
Linkable
Format),上面的.o文件是ELF文件中的Relocatable File,其各部分与其功能如下所示:
- ELF
Header:描述整个文件,文件格式在kernel中定义,64位由
struct elf64_hdr定义 - .text:编译好的二进制可执行代码
- .data:初始化好的全局变量
- .rodata:只读数据,const声明的变量、字符串常量
- .bss:未初始化的全局变量,运行时置为0
- .symtab:符号表,记录的是函数和变量名
- .strtab:字符串表,字符串常量和变量名
- Section Header Table:存储section的元数据
- .rel.*:重定位表,记录重定位项
链接
需要让create_process能被重用,需要形成链接库文件,使用下面的命令完成静态链接生成:
ar cr libstaticprocess.a process.o将两者连接起来生成二进制执行文件staticcreateprocess:
gcc -o staticcreateprocess createprocess.o -L. -lstaticprocess上面生成的二进制执行文件可以直接在Linux运行,这也是ELF文件,格式和对象文件十分类似,是由多个.o文件合并而成,各部分如下:
- 代码段
- .text
- .rodata
- 数据段
- .data
- .bss
- 不加载到内存的部分:ELF header、.symtab、.strtab、Section Header
Table
- Segment Header
Table:代码中定义为
struct elf64_phdr,主要是对段的描述, - ELF Header中的
e_entry字段存储程序入口的虚拟地址
- Segment Header
Table:代码中定义为
动态链接
动态链接库是多个对象文件的组合,可以被多个程序共享。
gcc -shared -fPIC -o libdynamicprocess.so process.o
gcc -o dynamiccreateprocess createprocess.o -L. -ldynamicprocess
//默认去/lib、/usr/lib 寻找动态链接库,修改为当前路径
export LD_LIBRARY_PATH=.动态链接也是ELF格式文件,多了.interp的segment,里面是ld-linux.so,这是做动态链接的工具。
新增的section如下:
- .plt(Procedure Linkage Table):过程链接表,entry存储地址,跳转到GOT的entry
- .got.plt(Global Offset Table
GOT):全局偏移量表,这里的entry存储函数的实际内存虚拟地址
- 初始化时GOT如何找到函数的内存地址:回调到PLT,PLT触发
ld-linux.so去找地址,并将地址存储在GOT
- 初始化时GOT如何找到函数的内存地址:回调到PLT,PLT触发
ELF注册机制
Linux
kernel对支持的可执行文件类型都有linux_binfmt的结构,定义在include/linux/binfmts.h中
下面的struct定义了加载二进制文件的方法:
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
} __randomize_layout;
//ELF文件的实现
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};其中的函数与含义如下:
- load_binary:读取可执行文件并为当前进程创建一个新的执行环境。
- load_shlib:动态的把一个共享库捆绑到在运行的进程。
- core_dump:在名称为core的文件中,存放当前进程的上下文,这个文件是进程收到
dump信号时被创建的
Linux中的linux_binfmt都存储在链表中,执行可执行文件时,kernel会遍历list找到指定的linux_binfmt,并调用load_binary来加载程序。
Q:ELF文件在什么时间段完成
linux_binfmt的注册?
Linux中使用线程
普通线程的创建和运行过程:
- 声明线程函数:定义一个工作函数
- 声明线程对象:
pthread_t thread; - 设置线程属性:
pthread_attr_t、pthread_attr_init、pthread_attr_setdetachstate - 创建线程:
pthread_create - 销毁线程属性:
pthread_attr_destroy - 等待线程结束:
pthread_join - 主线程结束:
pthread_exit
线程能访问的数据分为以下几种:
- 线程stack上的本地数据:函数执行过程中的局部变量
- stack大小可以通过
ulimit -a查看 - stack大小可以通过
ulimit -s修改,或者pthread_attr_setstacksize函数修改。
- stack大小可以通过
- 进程共享的全局数据:全局变量,需要使用
mutex等方案保证线程安全。 - 线程私有数据:线程内部各个函数传递信息,线程外的函数无法访问到这些数据
- 通过
pthread_key_create创建key pthread_setspecific设置key对应的valuepthread_getspecific获取key对应的value
- 通过
task_struct结构
在OS理论课程中的PCB,在Linux中实现就是task_struct,该结构体通过链表进行连接,无论是进程还是线程,在内核中都被称为task,并使用上述结构体存储metadata。
进程Id
线程组id用于区分线程和进程(线程拥有tgid),同一进程中的所有线程具有同一个tgid,tgid等于第一个主线程的pid。
pid_t pid;//进程ID
pid_t tgid;//线程组ID
struct task_struct *group_leader; c运行状态
- state:进程运行状态
- exit_state:任务终止状态
- flags:进程状态的信息,用于kernel识别进程当前状态
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
int exit_state;
unsigned int flags;
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_STATE_MAX 1024
················
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)Linux中的睡眠状态:
- TASK_INTERRUPTIBLE:可中断睡眠
- TASK_UNINTERRUPTIBLE:不可中断睡眠,不可被信号唤醒
- TASK_KILLABLE:可终止的新睡眠状态,只能接受致命信号
其他状态:
TASK_RUNNING:要么正在执行,要么准备被调度
TASK_STOPPED :进程接收到了SIGSTOP、SIGTTIN、SIGTSTP、SIGTTOU信号后进入该状态。
TASK_TRACED :进程正在被debug进程监视
EXIT_ZOMBIE :进程结束进入的状态,若父进程没有用
wait()等syscall获取它的终止信息,该进程变成僵尸进程。EXIT_DEAD:进程执行完的最终状态
flags取值如下:
/*
* Per process flags
*/
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
#define PF_VCPU 0x00000010 /* I'm a virtual CPU */
#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */
#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
#define PF_USED_ASYNC 0x00004000 /* used async_schedule*(), used by module init */
#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
#define PF_FROZEN 0x00010000 /* frozen for system suspend */
#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
#define PF_KSWAPD 0x00040000 /* I am kswapd */
#define PF_MEMALLOC_NOIO 0x00080000 /* Allocating memory without IO involved */
#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
#define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */
#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */
#define PF_SUSPEND_TASK 0x80000000 /* this thread called freeze_processes and should not be frozen */信号处理
信号处理函数默认使用用户态的函数栈,也可以开辟新的栈用于信号处理。这里定义了那些信号被阻塞暂不处理(blocked)、哪些信号尚待处理(pending)、哪些正在通过信号处理函数处理(sighand)
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;运行情况
各字段含义如下:
u64 utime;// 用户态消耗的 CPU 时间
u64 stime;// 内核态消耗的 CPU 时间
unsigned long nvcsw;// 自愿 (voluntary) 上下文切换计数
unsigned long nivcsw;// 非自愿 (involuntary) 上下文切换计数
u64 start_time;// 进程启动时间,不包含睡眠时间
u64 real_start_time;// 进程启动时间,包含睡眠时间父子进程关系
若在bash使用某进程创建进程,此时real_parent为bash,parent为某进程id,其他情况两者相同。
struct task_struct __rcu *real_parent; //指向父进程
struct task_struct __rcu *parent; //指向父进程
struct list_head children; //指向子进程的链表头部
struct list_head sibling; //指向兄弟进程进程拥有权限
- Objective:当前进程能操作的对象
- Subjective:能操作当前进程的对象
定义的取值是用户和用户所属的用户组信息。
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred; //谁能操作当前进程
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred; //当前进程能操作的
struct cred {
......
kuid_t uid; //启动当前进程的进程id
kgid_t gid; //同上
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; //操作消息队列 共享内存 信号量比较的权限
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; //文件系统操作比较的权限
kgid_t fsgid; /* GID for VFS ops */
......
kernel_cap_t cap_inheritable; //继承的权限集合
kernel_cap_t cap_permitted; //当前进程能够使用的权限
kernel_cap_t cap_effective; //实际能使用的权限
kernel_cap_t cap_bset; //系统中所有进程允许保留的权限
kernel_cap_t cap_ambient; /* Ambient capability set */
......
} __randomize_layout;除了以用户和用户组控制权限,Linux还用capabilities机制控制。用bitmap来表示权限,capability.h可以找到定义的权限。
#define CAP_CHOWN 0
#define CAP_KILL 5
#define CAP_NET_BIND_SERVICE 10
#define CAP_NET_RAW 13
#define CAP_SYS_MODULE 16
#define CAP_SYS_RAWIO 17
#define CAP_SYS_BOOT 22
#define CAP_SYS_TIME 25
#define CAP_AUDIT_READ 37
#define CAP_LAST_CAP CAP_AUDIT_READ函数栈
进程中的函数调用都是通过函数栈来实现的,每个函数都是一个栈帧,函数开始运行入栈,结束运行出栈。
struct thread_info thread_info; //存放对task_struct的补充信息(针对其他体系结构)
void *stack; //内核栈
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
struct thread_info {
unsigned long flags; /* low level flags */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
int preempt_count; /* 0 => preemptable, <0 => bug */
int cpu; /* cpu */
};普通函数存储在用户态函数栈,当发生系统调用,从进程空间转换到内核空间时,使用内核态函数栈存储栈帧。
内核栈在x86架构64bit中,定义在arch/x86/include/asm/page_64_types.h文件中,内核栈大小为PAGE_SIZE右移两位(16K),起始地址必须是8192的整数倍。
#ifdef CONFIG_KASAN
#define KASAN_STACK_ORDER 1
#else
#define KASAN_STACK_ORDER 0
#endif
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)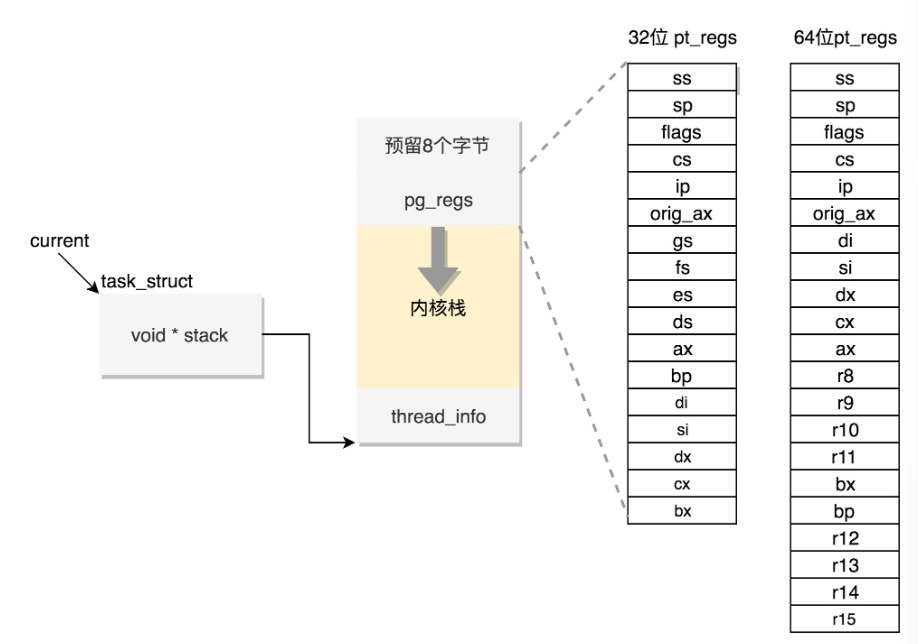
stack指向的地址空间最顶端是pt_regs(存储用户态上下文),当发生用户态转内核态时,存储用户态的CPU上下文信息,定义如下:
struct pt_regs {
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long bp;
unsigned long bx;
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long orig_ax;
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
/* top of stack page */
};内存管理
struct mm_struct *mm;
struct mm_struct *active_mm;文件系统
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;进程调度
有关进程调度的字段如下:
// 是否在运行队列上
int on_rq;
// 优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
// 调度器类,调度策略执行的逻辑
const struct sched_class *sched_class;
// 调度实体
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
// 调度策略
unsigned int policy;
// 可以使用哪些 CPU
int nr_cpus_allowed;
cpumask_t cpus_allowed;
struct sched_info sched_info;policy是调度策略,其取值如下:
- 实时调度策略:调度实施进程,需要尽快返回结果的。
- SCHED_FIFO:按照FIFO调度
- SCHED_RR:时间片轮转调度策略,高优先级任务可以抢占低优先级的任务。
- SCHED_DEADLINE:按照任务deadline进行调度,DL调度器选择deadline距离当前时间点最近的任务
- 普通调度策略:调度普通进程
- SCHED_NORMAL:调度普通进程
- SCHED_BATCH:调度后台进程,不需要和前端交互
- SCHED_IDLE:空闲时跑的进程
sched_class的具体实现:
stop_sched_class:优先级最高的任务会使用这种策略,会中断所有其他线程,且不会被其他任务打断;dl_sched_class:就对应上面的 deadline 调度策略;rt_sched_class: 就对应 RR 算法或者 FIFO 算法的调度策略,具体调度策略由进程的 task_struct->policy 指定;fair_sched_class: 就是普通进程的调度策略;idle_sched_class: 就是空闲进程的调度策略。
完全公平调度算法
Linux中实现了基于CFS(Completely Fair Scheduling)调度算法,其原理如下:
根据各个进程的权重分配运行时间,分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
公平体现在:给每个进程安排一个虚拟运行时间
vruntime,vruntime = 实际运行时间 * 1024 / 进程权重,vruntime小的进程运行时间不公平,CFS会优先调度这类进程。CFS使用红黑树将调度实体
sched_entity组织起来,vruntime是红黑树的key,树中key最小的节点就是CFS下一个调度的进程
主动调度
主动调度是指进程主动触发以下情况,转入内核态,最后调用schedule():
- 进程发起需要等待的IO,read/write
- 进程主动调用schedule
- 进程等待信号量或mutex,spin lock不会触发调度
进程调度的具体实现如下:
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
}
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can call that function directly, but only if the @prev task wasn't of a higher scheduling class, because otherwise those loose the opportunity to pull in more work from other CPUs.
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
//这里是依次调用调度类
again:
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
}逻辑如下:
- 在当前CPU取出任务队列rq
- prev指向rq上面正在运行的进程curr,因为curr要被切换下来
- 调用
pick_next_task选择下一个任务,该函数遍历所有的sched_class,如果rq -> nr_running == rq -> cfs.h_nr_running即队列进程数量== CFS调度器进程数量,CFS调度器则调用fair_sched_class.pick_next_task - CFS调度器会调用以下三个函数实现调度:
- update_curr:更新当前进程的vruntime,然后更新红黑树节点和
cfs_rq -> min_vruntime - pick_next_entity:选择红黑树的最左侧节点,比较和当前进程是否相同,不同则执行context_switch
- context_switch:上下文切换主要做两件事:
- 切换进程空间(虚拟内存)
- 切换寄存器和CPU上下文(内核栈切换)
- update_curr:更新当前进程的vruntime,然后更新红黑树节点和
上下文切换
上下文切换的核心代码如下:
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
......
mm = next->mm;
oldmm = prev->active_mm;
......
//切换内存地址空间
switch_mm_irqs_off(oldmm, mm, next);
......
/* Here we just switch the register state and the stack. */
//切换寄存器堆栈
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
//switch_to实现了栈和寄存器的切换
ENTRY(__switch_to_asm)
......
/* switch stack 切换rsp指针(栈顶指针) */
movq %rsp, TASK_threadsp(%rdi)
movq TASK_threadsp(%rsi), %rsp
......
jmp __switch_to //__switch_to
END(__switch_to_asm)
__visible __notrace_funcgraph struct task_struct *
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread;
struct thread_struct *next = &next_p->thread;
......
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(cpu_tss, cpu);
......
load_TLS(next, cpu);
......
this_cpu_write(current_task, next_p);
/* Reload esp0 and ss1. This changes current_thread_info(). */
load_sp0(tss, next);
......
return prev_p;
}X86结构提供了TSS(Task State Segment),这是以硬件的方式进行进程切换的结构,其中有X86所有的寄存器,但是这种切换的开销较大,需要保存所有寄存器数据。
Linux使用软切换方案,初始化时将每个CPU绑定一个TSS,tr指针永远指向这个tss_struct。使用thread_struct来保存上下文。当需要切换进程时,将thread_struct里面寄存器的值写入tr指向的tss_struct。两个结构如下:
struct tss_struct {
/*
* The hardware state:
*/
struct x86_hw_tss x86_tss;
unsigned long io_bitmap[IO_BITMAP_LONGS + 1];
}
struct thread_struct {
unsigned long rsp0;
unsigned long rsp;
unsigned long userrsp; /* Copy from PDA */
unsigned long fs;
unsigned long gs;
unsigned short es, ds, fsindex, gsindex;
/* Hardware debugging registers */
....
/* fault info */
unsigned long cr2, trap_no, error_code;
/* floating point info */
union i387_union i387 __attribute__((aligned(16)));
/* IO permissions. the bitmap could be moved into the GDT, that would make
switch faster for a limited number of ioperm using tasks. -AK */
int ioperm;
unsigned long *io_bitmap_ptr;
unsigned io_bitmap_max;
/* cached TLS descriptors. */
u64 tls_array[GDT_ENTRY_TLS_ENTRIES];
} __attribute__((aligned(16)));在Linux中可以通过以下操作查看进程的上下文切换:
vmstat
pidstat
cat /proc/interrupts被动调度(抢占式调度)
一般也被称为抢占式调度,发生时机:
- CPU时钟中断
- fork出新进程,CFS算法检查到CPU当前进程vruntime不是最小
- 进程等待IO完成后,进程被唤醒,如果优先级高于CPU当前进程,则会触发抢占。
时钟中断会调用scheduler_tick:
- 首先取出当前cpu运行队列rq
- 取到当前正在运行线程的task_struct
- 调用这个task的task_tick函数来处理时钟事件
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
......
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
......
}普通进程使用的公平调度器,对应函数为task_tick_fair
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
//找到对应的调度实体和cfs队列,调用entity_tick
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
......
}
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
//更新当前进程的vruntime
update_curr(cfs_rq);
update_load_avg(curr, UPDATE_TG);
update_cfs_shares(curr);
.....
if (cfs_rq->nr_running > 1)
//检查是否需要被抢占,内部检查进程运行时间等信息
check_preempt_tick(cfs_rq, curr);
}
static void check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
//计算runtime
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
return;
}
......
//取出红黑树最左侧,比较vruntime
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
//调用该方法标记该进程可被抢占
resched_curr(rq_of(cfs_rq));
}抢占时机
上面的流程仅仅将当前进程标记为可抢占,但是真正的调度流程还未执行。需要正在运行的进程调用__schedule(),这个调用可以在用户态和内核态发生。
用户态时,从系统调用中返回的时刻可以执行。exit_to_usermode_loop执行
内核态时,preempt_enable进行调度判断。
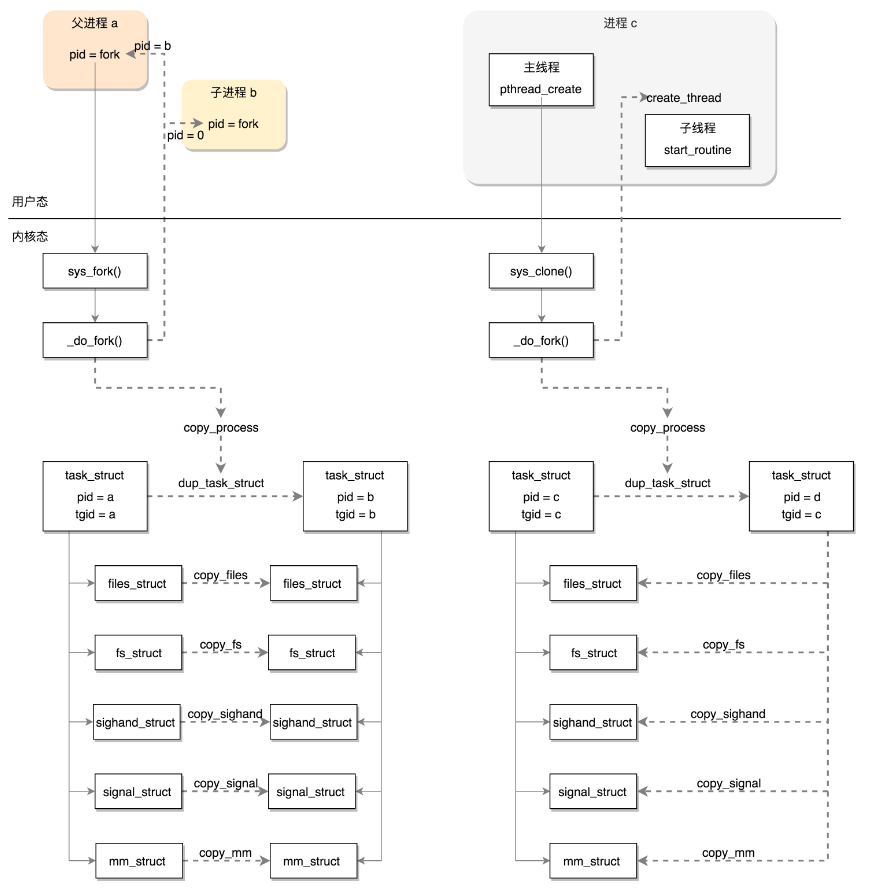
fork创建进程
fork是Linux中创建进程的一种方法,主要通过复制当前进程的方式来创建子进程
拷贝task_struct
fork是一个系统调用,它的调用流程最终会执行sys_fork,其定义如下:
SYSCALL_DEFINE0(fork)
{
......
return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
}
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
......
//复制父进程task_struct
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
......
if (!IS_ERR(p)) {
struct pid *pid;
//
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
......
wake_up_new_task(p);
......
put_pid(pid);
}
//copy_process实现
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
int retval;
struct task_struct *p;
......
//
p = dup_task_struct(current, node);
//执行调度器相关设置,将该task分配给一某个CPU
retval = sched_fork(clone_flags, p);
retval = perf_event_init_task(p);
retval = audit_alloc(p);
//拷贝进程的所有信息
shm_init_task(p);
retval = copy_semundo(clone_flags, p);
//拷贝进程打开的文件信息
retval = copy_files(clone_flags, p);
//拷贝进程的目录信息
retval = copy_fs(clone_flags, p);
//拷贝信号处理函数
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
//复制内存空间
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
retval = copy_io(clone_flags, p);
retval = copy_thread_tls(clone_flags, stack_start, stack_size, p, tls);dup_task_struct完成了对进程结构的初始化,具体实现了:调用
alloc_task_struct_node分配task_struct的内存结构调用
alloc_thread_stack_node创建task_struct->stack调用
arch_dup_task_struct完成task_struct的复制调用
setup_thread_stack设置thread_info
sched_fork主要对调度所需的变量进行初始化:调用
__sched_fork,对调度变量初始化,比如vruntime等设置进程优先级
设置调度类,并调用调度函数
task_fork(CFS调度是task_fork_fair)
fork主要做了以下的操作:
- 完成
task_struct的拷贝,通过copy_process实现 - 完成权限的拷贝,通过
copy_creds实现 - 调用
sched_fork进行调度
唤醒子进程
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
......
//设置进程状态
p->state = TASK_RUNNING;
......
//调用enqueue_task,CFS调度会执行对应的enqueue_task_fair
activate_task(rq, p, ENQUEUE_NOCLOCK);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
//检查是否能抢占当前进程
check_preempt_curr(rq, p, WF_FORK);
......
}
上述的enqueue_task_fair实现以下功能:
- 取出rq,调用
enqueue_entity将进程节点加入红黑树 - 更新队列上运行的进程数量
创建线程
Linux中创建线程调用的是pthread_create,其调用的也是_do_fork实现线程数据复制功能,与进程创建流程的流程图差异如下所示: