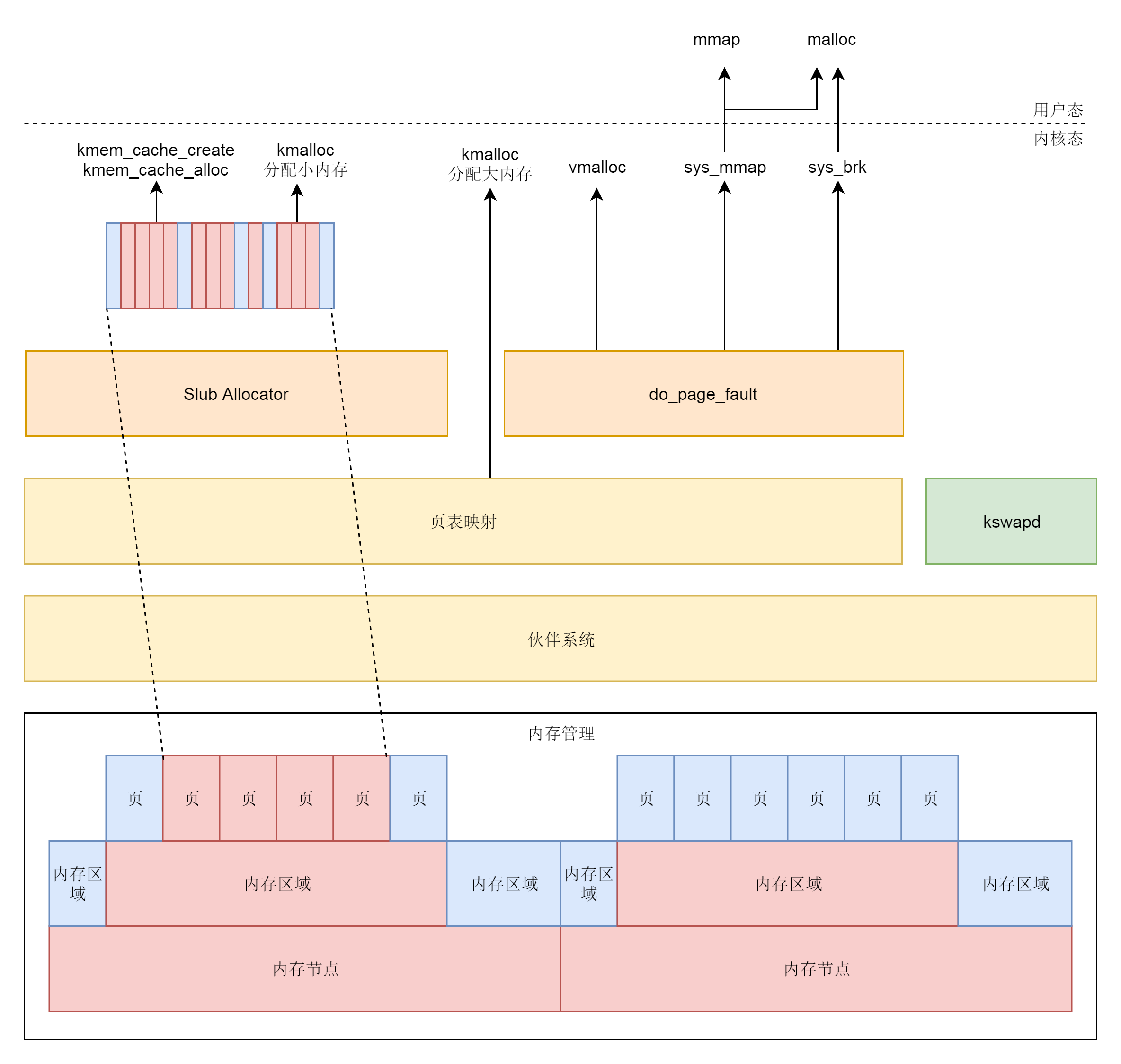
Linux内存管理模块分析
概述
内存管理主要分为三个方面:
- 管理物理内存:只有内核中负责内存管理的模块可以使用
- 管理虚拟内存:每个进程看到的都是独立且互不干扰的虚拟空间
- 物理内存和虚拟内存的转换:上述两者的映射关系
无论是内核态程序还是用户态程序,都使用虚拟内存,虚拟内存空间布局如下:
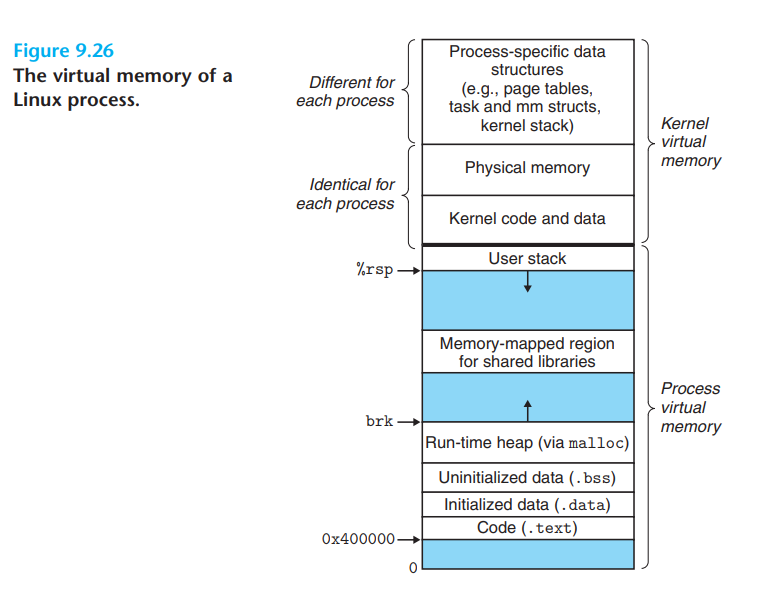
- 内核空间部分:存放内核进程的程序
- 用户空间部分:存放用户进程的程序,从最低位开始,逐个段如下:
- Text Segment:存放二进制可执行代码的位置
- Data Segment:存放静态常量
- BSS Segment:存放未初始化的静态变量
- Heap:动态分配内存的区域,malloc在这个空间分配
- Memory Mapping Segment:用来把文件映射到内存的区域,如果可执行文件依赖某个动态链接库,so文件就映射在这。
- Stack:进程的函数调用栈,由一个个frame(相当于函数实体)构成,内部存放局部变量、返回地址等信息,frame结构如下图所示:
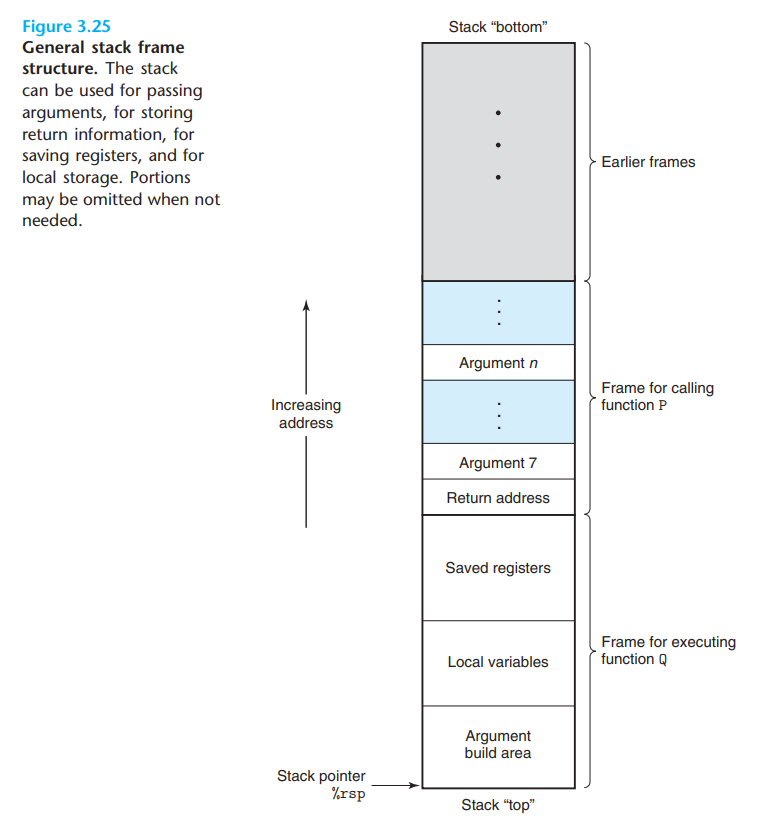
可以通过pmap pid展示进程的地址空间相关信息。
基本概念
分段机制
分段机制如下图所示:
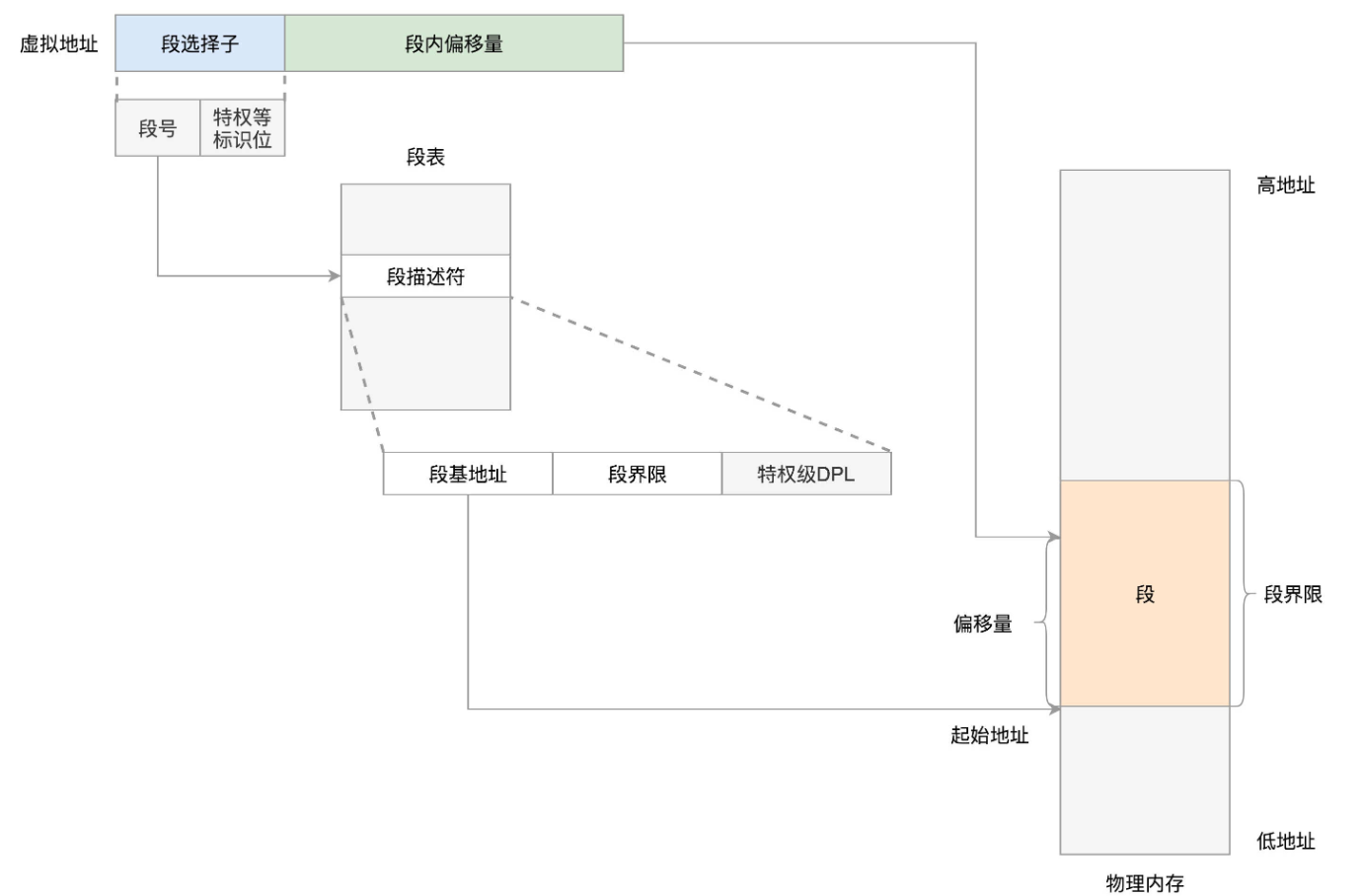
在Linux中,段表被称为段描述符表,放在全局描述符表 GDT中,一个段表项由段基址base,界限limit,还有一些标识符组成:
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
#ifdef CONFIG_X86_64
[GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),
#else
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
......
#endif
} };
EXPORT_PER_CPU_SYMBOL_GPL(gdt_page);
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS*8)
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8)
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8 + 3)
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8 + 3)分段机制在Linux中,可以做权限审核,用户态试图访问内核态,权限不足会禁止访问。
分页机制
Linux使用的更多的是分页机制,将物理内存分成一块块相同大小的page,其机制如下图所示:
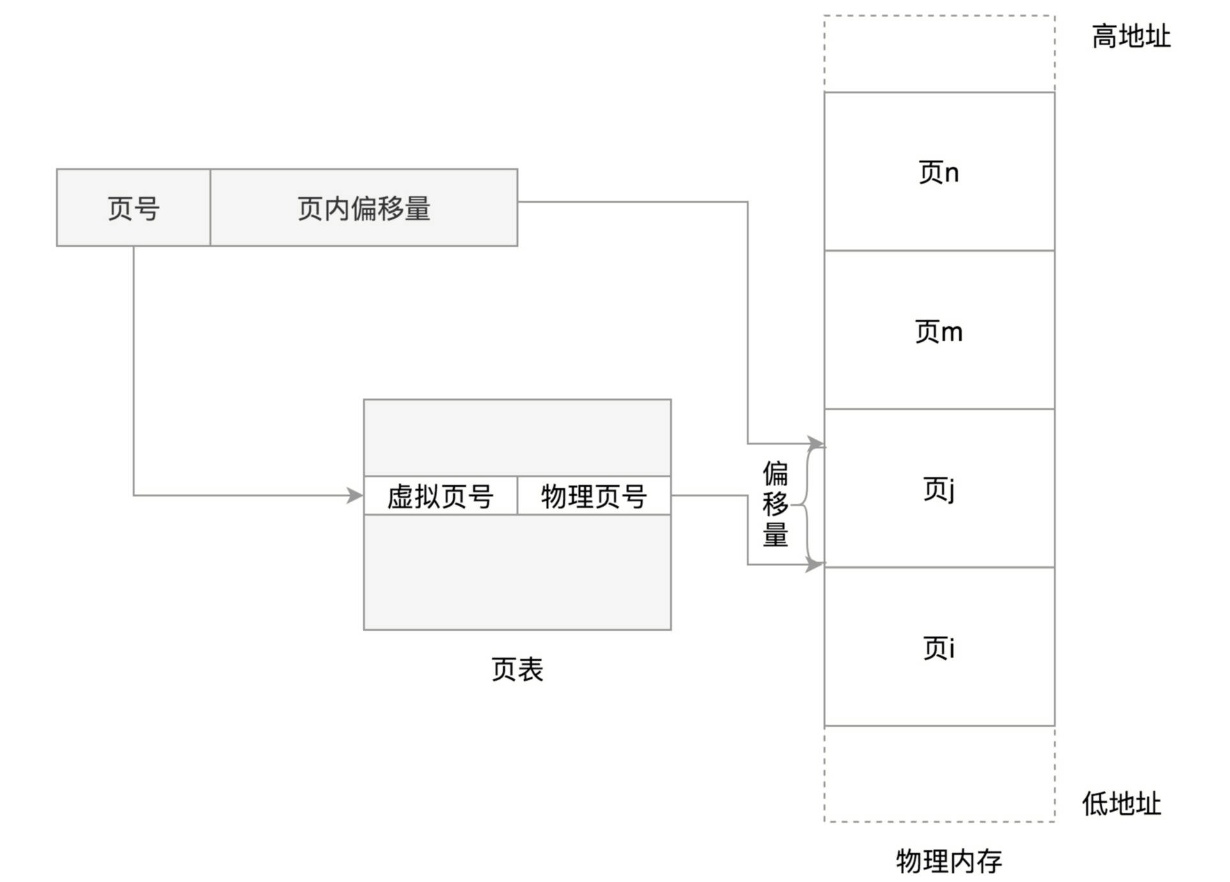
多级页表的好处:
- 减少页表占用的内存空间
- 增加地址映射空间
Linux的64位系统使用四级页表,其结构如下所示:
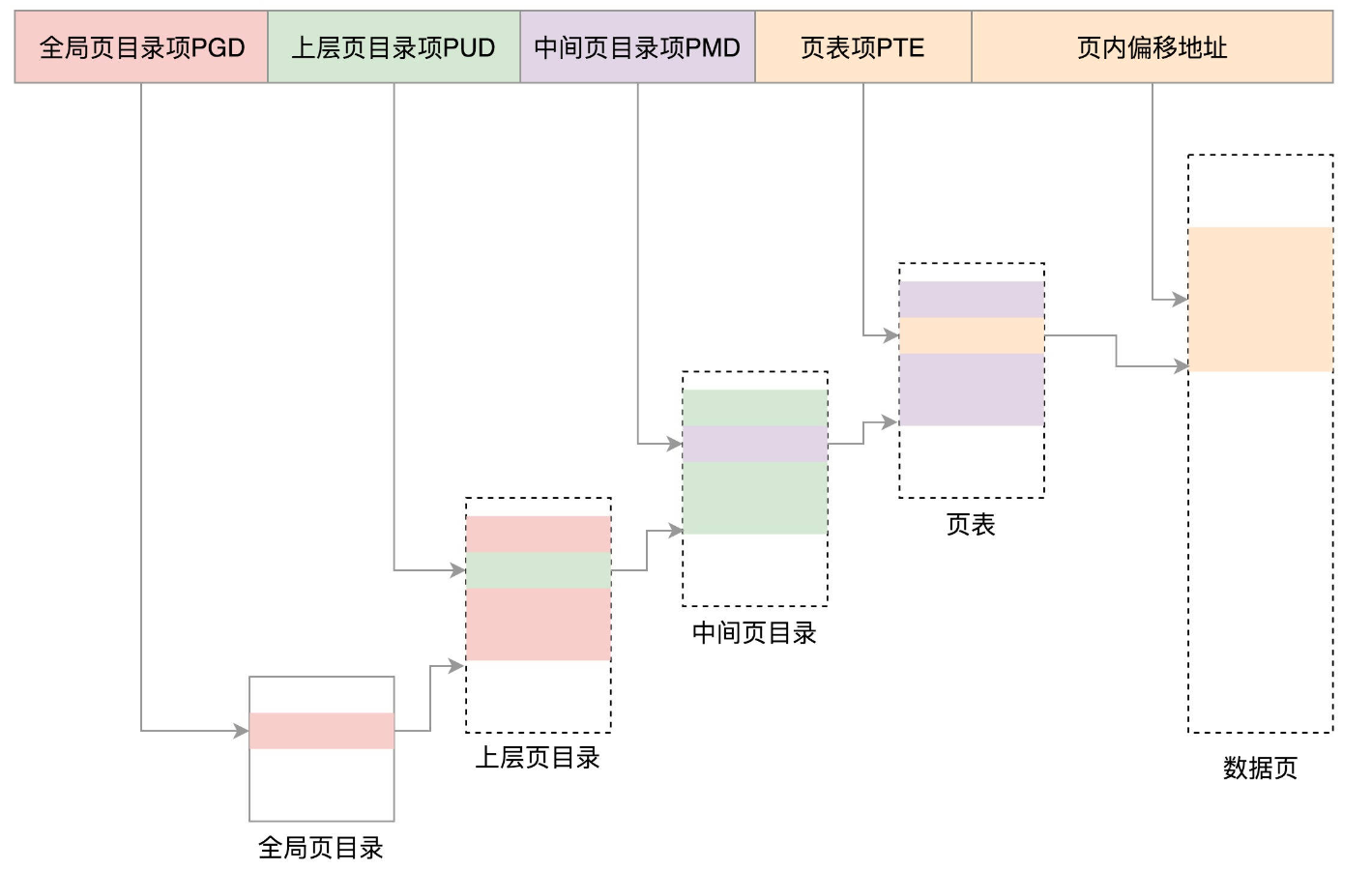
进程空间管理
进程的task_struct中对进程地址存储了mm_struct,整个虚拟内存空间分为用户态空间和内核态空间,两者分界线由mm_struct->task_size决定。
32位最大寻址空间为\(2^{32} =4G\),其中内核态占用顶部1G,用户态占用底部3G
64为系统虚拟地址只使用了48位,内核态和用户态各使用128T
用户态空间
mm_struct中关于用户态空间的信息如下:
unsigned long mmap_base; /* base of mmap area */
unsigned long total_vm; //总共映射的页数量
unsigned long locked_vm; //被锁定不能换出到磁盘的页数量
unsigned long pinned_vm; //不能换出也不能移动的页数量
unsigned long data_vm; //存放数据的页数量
unsigned long exec_vm; //存放可执行文件的页数量
unsigned long stack_vm; //栈所占的页数量
//可执行代码开始位置、结束位置,已初始化数据开始位置、结束位置
unsigned long start_code, end_code, start_data, end_data;
//堆开始位置、结束位置、栈开始位置
unsigned long start_brk, brk, start_stack;
//参数列表的开始结束位置,环境变量的开始结束位置,这两者都位于栈的最顶部
unsigned long arg_start, arg_end, env_start, env_end;
//描述内存区域
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;vm_area_struct是一个单链表,将进程拥有的内存区域串接起来
(根据地址串起来),并使用红黑树存储,方便快速查询。
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; //区域开始位置
unsigned long vm_end; //区域结束位置
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb; //红黑树存储节点
struct mm_struct *vm_mm; /* The address space we belong to. */
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops; //可以操作的动作
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
} __randomize_layout;Q:什么时候将
vm_area_struct和上面的内存区域关联起来?
load_elf_binary除了解析ELF格式外,还需要建立内存映射:
static int load_elf_binary(struct linux_binprm *bprm)
{
......
//设置内存映射区mmap_base
setup_new_exec(bprm);
......
//设置栈的vm_area_struct的args等参数
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
......
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
......
//设置堆的参数
retval = set_brk(elf_bss, elf_brk, bss_prot);
......
//依赖的so文件映射到内存中的内存映射区域。
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
......
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
......
}内核态空间
32位系统的内核态空间布局如下所示:

- 直接映射区:这部分与物理地址的前896MB进行映射。
- 系统启动时,使用物理内存的前1M加载内核代码段等,可以查看
/proc/iomem - 如果系统调用创建进程,进程
task_struct会存放在这,相应的页表项也会被创建。 - 内核栈分也被分配在该区域。
- 系统启动时,使用物理内存的前1M加载内核代码段等,可以查看
- 内核动态映射空间(vmalloc):类似于用户态的堆区,内核态使用
vmalloc申请内存 - 持久内核映射:可以调用
kmap将高端内存页到该区域 - 固定内核映射:满足特殊需求。
物理内存管理
平坦内存模型(Flat Memory
Model):物理内存中页是连续的,对于任何物理地址,只需要除以页大小,就可以算出具体的页面地址,每个页通过struct page表示。
- SMP(Symmetric multiprocessing):多处理器通过一个总线同时访问内存。
- 总线称为性能瓶颈
- NUMA(Non-uniform memory
access):非一致内存访问,每个CPU拥有自己的本地内存,这块内存称为一个NUMA节点,本地内存不足时可以申请另外的NUMA节点。
- 此时内存被分为一个个内存节点,节点再划分一个个页面,此时页号需要保证全局唯一
- NUMA是非连续内存模型
物理内存管理整体分为以下的流程:
- 物理内存分为NUMA节点,分别管理。
- 每个NUMA节点分为多个内存区域
- 每个内存区域分为多个物理页面
- Buddy System将多个连续的页面作为一个大内存块分配给需求进程
- kswapd内核进程负责物理页的换入换出
- slab机制将从伙伴系统申请的大内存块划分成小块,并将热点结构
task_struct等做缓存块,提供需求方使用。
节点
对于NUMA方式,首先需要一个结构来表示NUMA节点,Linux中使用下面的结构体来表示,各字段注释如下:
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; //每个节点划分一个个zone,放在该数组中
struct zonelist node_zonelists[MAX_ZONELISTS]; //备用节点和内存区域的情况
int nr_zones; //当前节点的zone数量
struct page *node_mem_map; //该节点的struct page数组
unsigned long node_start_pfn; //节点的起始页号
unsigned long node_present_pages; //真正可用的物理页面数
unsigned long node_spanned_pages; //节点中包含不连续的物理内存地址的页面数
int node_id; //节点
......
} pg_data_t;zone
表示zone的数据结构定义如下:
struct zone {
......
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset; //区分冷热页面
unsigned long zone_start_pfn; //zone的第一个页
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
*/
unsigned long managed_pages; //被伙伴系统管理的所有page数量
unsigned long spanned_pages; //spanned_pages = zone_end_pfn - zone_start_pfn;
unsigned long present_pages; //真实的page数量
const char *name;
......
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
......
} ____cacheline_internodealigned_in_
//zone的类型
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
__MAX_NR_ZONES
};zone的类型分别如下:
- ZONE_DMA:用作DMA的内存结构
- ZONE_NORMAL:直接映射区
- ZONE_HIGHMEM:高端内存区
- ZONE_MOVABLE:可移动区域,通过将内存划分为可移动区域和不可移动区域,来避免内存碎片。
冷热页面:页面是否被加载到CPU
cache中,若在cache中则是Hot Page,CPU读取非常快。
struct per_cpu_pages {
int count; // number of pages in the list
int high; // high watermark, emptying needed
int batch; // chunk size for buddy add/remove
// Lists of pages, one per migrate type stored on the pcp-lists
//每个CPU在每个zone上都有MIGRATE_PCPTYPES个冷热页链表(根据迁移类型划分)
struct list_head lists[MIGRATE_PCPTYPES];
};page
page是组成物理内存的基本单位,内部有很多union结构,物理页面若直接使用一整页的内存,page直接和虚拟地址空间建立映射关系,则被称为匿名页,若page用于关联一个文件,再和虚拟地址空间建立映射关系,这种文件则被称为内存映射文件。
第一种模式,使用以下字段存储元数据:
- struct address_space *mapping:用于内存映射
- pgoff_t index:映射区的偏移量
- atomic_t _mapcount:记录指向该页的页表项
- struct list_head lru:如果页面被换出,就在换出页的链表中
第二种模式,仅需要分配小块内存,例如一个task_struct结构只需要一小块内存。Linux使用slab allocator分配称为slab的一小块内存,其基本原理是:申请一整块内存页,然后划分成多个小块的内存存储池,并使用复杂的队列来维护状态。,由于队列的维护操作过于复杂,后来使用slub allocator分配,此方式不使用队列。可以看成前者的另一种的实现。
page整页分配
对于分配较大的内存(分配页级别的),可以使用Buddy System来分配。Linux中内存页大小默认为4KB,将所有的空闲页分组为11个页块链表,页块大小分别是1、2、4、8、16、32、64、128、256、512、1024个连续页,最大可以申请1024个连续页(共4MB),其结构如下所示:
当向内核请求分配$(2^{i-1}, 2^i] $个页块时,按照\(2 ^ i\)个请求处理,如果该页块链表中没有足够的空闲页快,就去更大一级的链表中申请,并且会将更大一级的页块分裂,并返回所需页块大小给请求进程。
slab机制
首先slab分配器是基于Buddy System的,slab需要从buddy分配器获取连续的物理页,然后将其内部划分为一个个小的slab。Linux内核从2.6起提供了slab和slub两种方案,两者差异上面已经记录。
分配流程
slab机制主要针对一些经常被分配并释放的对象,这些对象一般比较小,使用buddy分配器会造成大量的内存碎片,并且处理速度慢,slab分配器基于对象进行管理,相同类型分为一类,每次申请时,slab分配器就从列表中分配一个该类型的对象,当要释放时,将其重新保存在该类型的列表中,而不是返回给buddy分配器,避免了重复初始化等开销。slab对象类型主要有:task_struct、mm_struct、fs_struct等。
创建进程时,需要创建task_struct并复制父进程数据,需要先调用alloc_task_struct_node分配,其执行流程如下:
static struct kmem_cache *task_struct_cachep;
//task_struct_cachep被kmem_cache_create创建,大小为arch_task_struct_size
task_struct_cachep = kmem_cache_create("task_struct",
arch_task_struct_size, align,
SLAB_PANIC|SLAB_NOTRACK|SLAB_ACCOUNT, NULL);
static inline struct task_struct *alloc_task_struct_node(int node)
{
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
static inline void free_task_struct(struct task_struct *tsk)
{
kmem_cache_free(task_struct_cachep, tsk);
}task_struct_cachep被用作分配task_struct的缓存,每次创建该结构时,都会先查看缓存是否有直接可用的,而不用直接去内存里面分配。当进程结束后,task_struct不会被直接销毁,而是放回到缓存中。SLAB缓存结构信息如下:
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; //包含指针的大小
int object_size; //纯对象的大小
int offset; //下一个空闲对象指针的offset
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
......
const char *name; /* Name (only for display!) */
struct list_head list; //slab的缓存链表
......
struct kmem_cache_node *node[MAX_NUMNODES];
};缓存块分为以下两种:
- kmem_cache_cpu:CPU slab块,快速通道
- kmem_cache_node:Node slab块,普通通道
分配时首先从快速通道分配,若里面没有空闲块,再到普通通道分配,如果还是没有空闲块,才去Buddy System分配新的页。
kmem_cache_cpu结构如下:
struct kmem_cache_cpu {
void **freelist; //指向大内存块的第一个空闲的项,形成空闲链表
unsigned long tid; /* Globally unique transaction id */
struct page *page; //指向内存块的第一个页,缓存块从里面分配
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; //部分空闲的slab缓存块
#endif
......
};kmem_cache_node 结构如下:
struct kmem_cache_node {
spinlock_t list_lock;
......
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial; //存放部分空闲的slab块
......
#endif
};kmem_cache_alloc_node会调用slab_alloc_node,流程如下:
/*
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
* have the fastpath folded into their functions. So no function call
* overhead for requests that can be satisfied on the fastpath.
*
* The fastpath works by first checking if the lockless freelist can be used.
* If not then __slab_alloc is called for slow processing.
*
* Otherwise we can simply pick the next object from the lockless free list.
*/
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
......
tid = this_cpu_read(s->cpu_slab->tid);
//取出cpu slab缓存
c = raw_cpu_ptr(s->cpu_slab);
......
//取出freelist,这是第一个空闲的项
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
//若没有空闲的cpu slab,调用__slab_alloc进入普通通道。
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
......
return object;
}
//__slab_alloc进入普通通道
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
......
redo:
......
/* must check again c->freelist in case of cpu migration or IRQ */
//再次尝试cpu slab,万一有其他进程释放
freelist = c->freelist;
if (freelist)
goto load_freelist;
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
//如果还是没有,调用new_slab
goto new_slab;
}
load_freelist:
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;
new_slab:
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
//调用new_slab_objects
freelist = new_slab_objects(s, gfpflags, node, &c);
......
return freelist
//创建slab块
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
///根据node_id,找到对应的kmem_cache_node,然后调用get_partial_node
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
page = new_slab(s, flags, node);
if (page) {
c = raw_cpu_ptr(s->cpu_slab);
if (c->page)
flush_slab(s, c);
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
*pc = c;
} else
freelist = NULL;
return freelist
/*
* Try to allocate a partial slab from a specific node.
*/
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
struct page *page, *page2;
void *object = NULL;
int available = 0;
int objects;
......
list_for_each_entry_safe(page, page2, &n->partial, lru) {
void *t;
//acquire_slab从普通node的partial链表中取下一大块内存,并将freelist第一块空闲内存赋给t
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)
break;
available += objects;
if (!object) {
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
break;
}
......
return object;页面换出
进程拥有的虚拟内存空间往往非常大,但是物理内存没有足够的空间,只有页面被使用时,才会放在物理内存中,如果一段时间不使用且用户进程没有释放,物理内存管理模块需要将这些页面换出到磁盘中,将空出的物理内存交给其他进程使用。
例如,当分配内存时,发现没有足够的内存时,会试图进行回收,函数调用链为:get_page_from_freelist->node_reclaim->__node_reclaim->shrink_node。当然也有内核线程kswapd主动检查内存是否需要换出。
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int classzone_idx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
for ( ; ; ) {
......
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
classzone_idx);
......
reclaim_order = balance_pgdat(pgdat, alloc_order, classzone_idx);
......
}
}
shrink_node调用shrink_node_memcg:
/*
* This is a basic per-node page freer. Used by both kswapd and direct reclaim.
*/
static void shrink_node_memcg(struct pglist_data *pgdat, struct mem_cgroup *memcg,
struct scan_control *sc, unsigned long *lru_pages)
{
......
unsigned long nr[NR_LRU_LISTS];
enum lru_list lru;
......
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
unsigned long nr_anon, nr_file, percentage;
unsigned long nr_scanned;
//从LRU中检查
for_each_evictable_lru(lru) {
if (nr[lru]) {
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);
nr[lru] -= nr_to_scan;
nr_reclaimed += shrink_list(lru, nr_to_scan,
lruvec, memcg, sc);
}
}
......
}
......所有页面都挂在LRU列表上,页面划分为匿名页和内存映射页两种,并且都存在active和inactive两种状态的LRU列表,如果要换出内存,找出不活跃列表中最不活跃的,换出到硬盘。
mmap用户态内存映射
mmap是一个系统调用,本质是一个用户态进程的虚拟内存映射方法,基本作用如下:
- 将文件映射到进程的虚拟内存空间
- 可以通过文件实现进程间通信、IO优化(零拷贝)等
- 进程申请内存时,例如堆内存,mmap将内存空间映射到物理内存。
mmap系统调用如下:
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
......
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
......
}
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
......
file = fget(fd);
......
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
return retval;
}如果映射到文件,fd传入一个文件描述符,通过mmap_pgoff->fget根据fd获取struct_file,接下来调用vm_mmap_pgoff->do_mmap_pgoff->do_mmap,这里主要调用了两个方法:
- get_unmapped_area:找到一个没有映射的内存区域
- mmap_region:映射到这个内存区域
get_unmapped_area流程如下:
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
......
//如果是匿名页,直接调用mm->get_unmapped_area找到vm_area_struct红黑树上对应的位置
get_area = current->mm->get_unmapped_area;
//如果是映射到文件,找到file_operations并调用get_unmapped_area
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
}
......
}mmap_region流程如下:
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
/*
* Can we just expand an old mapping?
*/
//首先看是否能和前一个vm_area_struct合并
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
//不能则调用kmem_cache_zalloc在slab里面创建一个vm_area_struct
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
//如果是文件,则设置vm_file为目标文件,调用call_mmap
if (file) {
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
}
......
//vma_link将创建的vm_area_struct存放在mm_struct里面的红黑树上面
vma_link将创建的(mm, vma, prev, rb_link, rb_parent);
return addr;
.....vma_link将内存到文件的映射关系建立后,文件到内存的映射通过struct file里面成员指向struct address_space,这个结构中有一个红黑树,内存区域vm_area_struct挂在这棵树上。
缺页异常
上述流程仍然在虚拟内存中进行操作,只有真正使用时,才回去分配物理内存,当进程开始访问虚拟内存中某个地址,如果没有找到对应的物理页,就会触发缺页中断,调用do_page_fault,页表存储在mm_struct中。
dotraplinkage void notrace
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address = read_cr2(); /* Get the faulting address */
......
__do_page_fault(regs, error_code, address);
......
}
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
//首先判断终端是否发生在内核中
if (unlikely(fault_in_kernel_space(address))) {
//内核中断调用vmalloc_fault
if (vmalloc_fault(address) >= 0)
return;
}
......
//若是用户态中断,查找地址所在的vm_area_struct
vma = find_vma(mm, address);
......
//调用handle_mm_fault完成映射
fault = handle_mm_fault(vma, address, flags);
......
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
//设置四级页表
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
......
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
......
}总结
内存管理的体系可以总结为:
- 物理内存根据NUMA架构分节点,节点内部再分区域,区域内再分页
- 物理页面通过buddy system进行分配,物理页面可以映射到虚拟内存空间,内核进程kswapd根据物理页面使用情况,按照LRU等缓存算法对页面进行换入换出。
- 内核态内存分配
- 大内存块的情况:kmalloc分配大内存时,以及vmalloc分配不连续物理页,直接用buddy
system,分配后转为虚拟地址,访问时通过内核页表进行地址映射。
- 该部分会被换出,当访问发生缺页时,通过调用
dp_page_fault处理缺页中断。
- 该部分会被换出,当访问发生缺页时,通过调用
- 小内存块的情况:对于 kmem_cache 以及 kmalloc
分配小内存时,使用slab分配器,当slab缓存块不足时,从buddy
system申请大块内存,然后切分成小块进行分配。
- 该部分不会被换出,因为slab保存的是常用且关键的struct。
- 大内存块的情况:kmalloc分配大内存时,以及vmalloc分配不连续物理页,直接用buddy
system,分配后转为虚拟地址,访问时通过内核页表进行地址映射。
- 用户态内存分配:调用mmap系统调用或brk系统调用,用户态内存都会被换出,缺页时使用中断调入内存。
- 申请内存小于128k时,调用
brk()完成,通过sys_brk系统调用实现。 - 申请内存大于128k时,调用
mmap()在堆栈之间的映射区分配。
- 申请内存小于128k时,调用