1. Intro
《The Google File System》(GFS)是Google于2003年在ACM SOSP(Symposium on Operating Systems Principles)上发表的一篇论文。它首次系统性地介绍了Google内部为应对大规模数据处理而设计的分布式文件系统架构。
在21世纪初,随着互联网的爆发式发展,Google需要存储并处理海量的网页、图片等数据,传统File System无论在性能、容错性、可靠性等方面都无法满足需求,因此Google设计了GFS以解决大规模文件存储和管理的需求。
2. 设计概览
2.1. 设计目标
GFS的主要设计目标包括:
- 性能
- 可用性
- 可伸缩性
需要满足的需求:
- 系统由大量廉价的存储介质构成,需要考虑监控、容错、快速回复能力
- 需要解决大量文件存储和管理。
- 读取场景:大规模的顺序读,小规模的随机读
- 写入场景:大规模的顺序写,极少数的小规模随机写
- 并发支持:支持多Client并发写入同一个文件的场景
2.2. 集群概览
GFS集群从架构上看,节点分成两个类型:
- Master:整个集群的Master节点,负责以下职责:
- 维护所有Chunk Server节点的metadata
- 回收废弃chunk
- Chunk Server之间chunk迁移
- 与Chunk Server进行HeartBeat
- Chunk Server:文件会被切分成chunk存储到节点中,每个chunk存在三个备份。
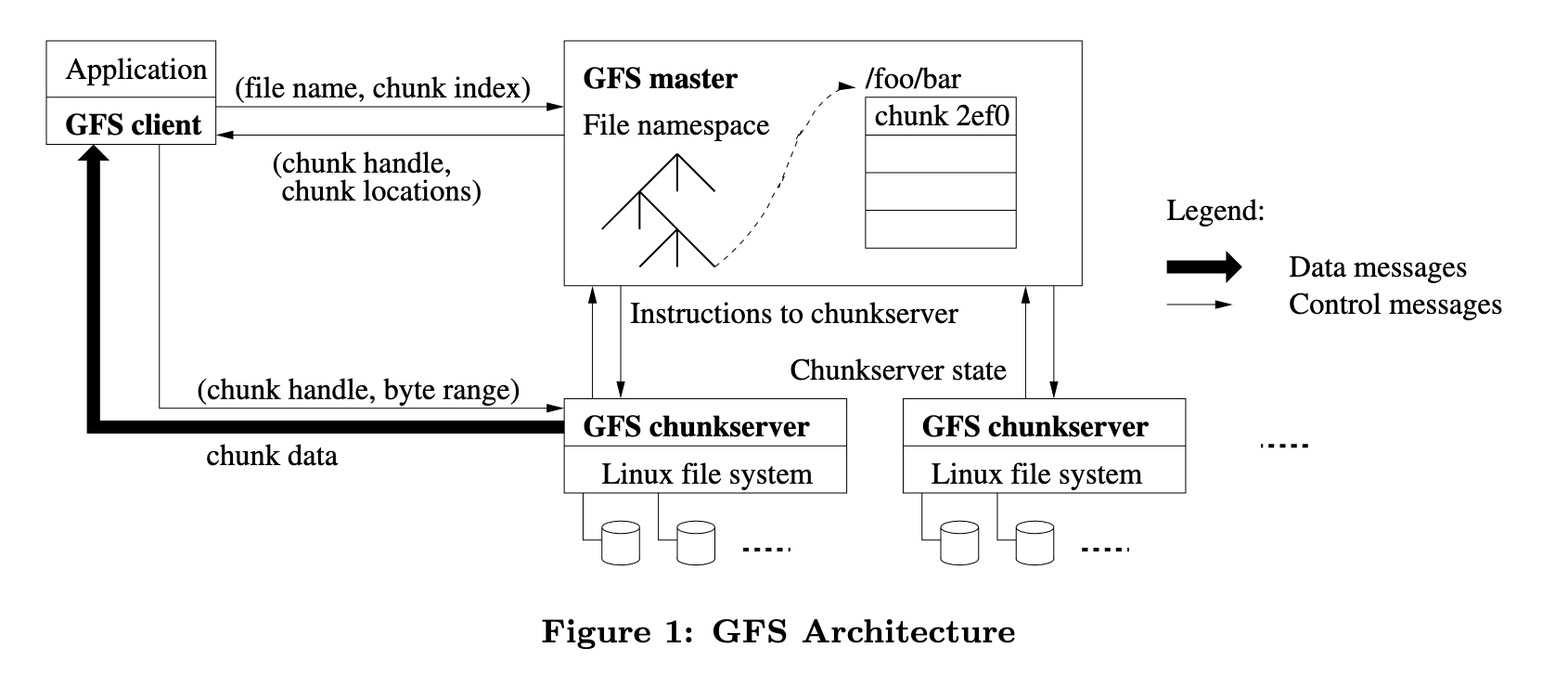
存储文件时,GFS会将文件切分成若干个固定大小的Chunk块并存储,Master会为每个Chunk块分配一个唯一Hash key(论文中成为handle),并将它们交由Chunk Server存储,Chunk Server以普通文件的形式将每个Chunk存储在本地磁盘上,并存储多Replica以保证数据可靠性。
Client从GFS读取文件的步骤划分为:
- Client在本地通过文件名和byte offset转换为chunk index
- Client向Master发送携带filename和chunk index的请求,以获取chunk的唯一标识chunk handle和chunk replica所在的Chunk Server地址
- Client向最近的Chunk Server请求chunk数据
2.3. Chunk Size
Chunk Size是分布式文件存储系统中一个重要的性能指标,在参数选择上需要取舍以下因素:
| 因素 | Chunk 越大 | Chunk 越小 |
|---|---|---|
| 元数据压力 | 减少 | 增加 |
| 随机访问延迟 | 增加(加载较大 chunk耗时) | 降低 |
| 顺序访问吞吐 | 更高 | 更低 |
| 负载均衡灵活性 | 降低(数据倾斜) | 更好 |
| 容错恢复代价 | 更大(单个 chunk 损坏数据多) | 更小 |
| 网络带宽利用效率 | 更高 | 更低(小文件碎片化) |
GFS的chunk size选取为64MB,论文中提到选取大chunk的原因如下:
- 适配当时Google内部应用场景:大规模顺序读
- 减少Client/Chunk Server间的TCP连接次数
- 减少了metadata存储空间
另一方面,论文中也提到了大chunk的缺点:数百个Client同时读取一个小文件,由于只有一个chunk,会使得该Chunk Server的负载瞬间提升。Google选取的解决方案是增加该chunk的Replica数量。
2.4. Metadata
Master存储的metadata数据类型包括:文件namespace、file-to-chunk映射关系、每个chunk replica的位置,前两种类型metadata的变更记录会被存储到本地磁盘并创建replica存储到远程机器上(snapshot),用以提升Master节点的可靠性。chunk replica location由每个Chunk Server加入集群时主动上报给Master。
Master并没有将metadata存储在硬盘中,而是将metadata存储在内存中,并使用定期线程扫描废弃chunk并GC、还需要完成Chunk Server之间的数据迁移。
2.4.1. Operation Log
GFS Master节点会将metadata变更记录存储到operation log中,它将被存储在磁盘上,用于提升数据可靠性,当Log达到一定大小时,会将当前当前metadata持久化到磁盘中,这被称为checkpoint,并且Master节点会在启动时读取checkpoint,这会提升Master在启动或故障恢复时metadata载入速度,checkpoint是一个压缩B-Tree,可以直接被加载到内存而不需要额外的解析流程。
3. 详细设计
3.1. 数据一致性
Mutation是指对chunk内容或metadata的修改操作,多Replica场景也就引出了分布式场景中数据一致性问题,GFS采用了宽松的一致性模型来支持其简单高效的分布式实现,对于追加写入操作,GFS也只是作出了至少一次(At Least Once)这样宽松的保障。
从以下几个方面来分析一致性实现:
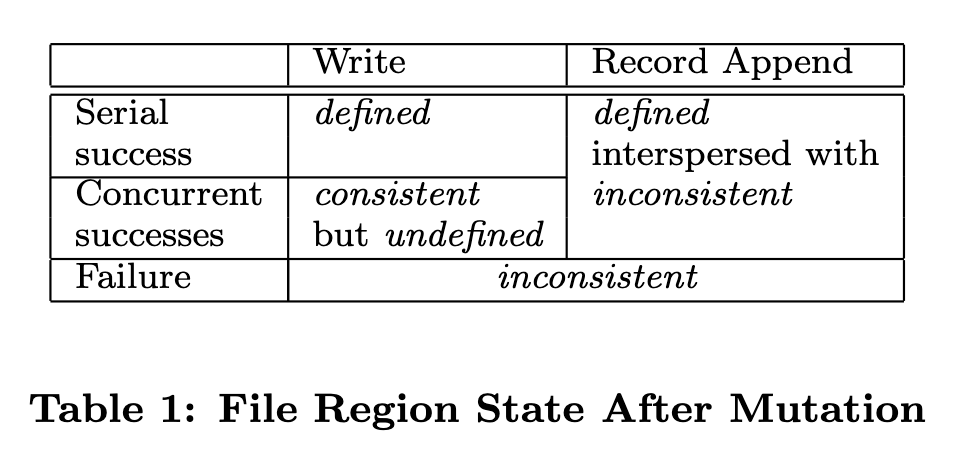
首先metadata中namespace变更在Master节点上的操作都是原子性,因此不存在一致性问题,而文件chunk修改较为复杂,如果不同的客户端并发写入同一个文件chunk,这块chunk可能会存在数据不一致的情况,因此在chunk mutation完成后,可能发生以下三种场景:
- consistent:Client读取不同replica时可能读取到不同数据
- inconsistent:Client无论同时读取哪个replica都会读取到相同数据
- defined:Client能确认上次修改前的所有数据,并且这部分数据是一致的
chunk在操作后对应的状态表:
前文提到一个文件Chunk同时存三个Replica以提升数据完整性,因此每个replica需要合理分布到集群的不同位置。chunk replica分开存放的目的主要有两个:
- 最大限度提升数据可靠性和可用性
- 最大限度提升网络带宽利用率
GFS在设计上考虑到现实情况中,不同的机器可能同时存在于一台机架上,因此在分布策略中,还要讲Replica均匀分布到各个机架,可以确保当某个机架离线时,仍有其他replica可用,同时也能确保流量平均打到各个机架带宽中。
为了保证数据完整,Chunk Server会将每个Chunk Replica切分为若干个block,并为每个block计算32位的checksum,以防止该Chunk Replica损坏,block的checksum会存储在Chunk Server的内存中,当接收到读请求时,Chunk Server会使用checksum检查数据是否完整,如果数据损坏则返回错误信息并上报Master,使得Client向另一个Replica发起读请求,并且Master会利用其他有效Replica来恢复损坏Replica。
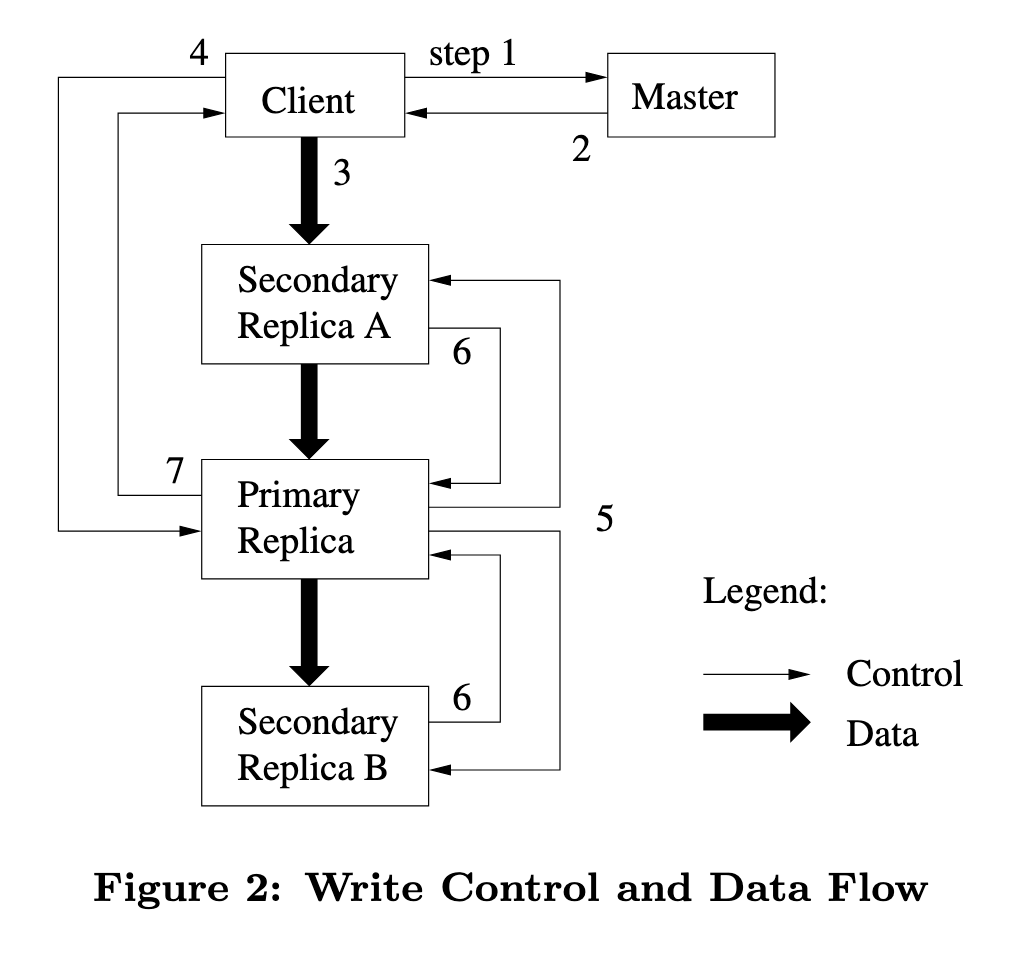
3.1.1. Lease机制
由于GFS中每个Chunk都存在多个Replica,因此需要确保这些Replica在进行修改时的顺序一致,因此Master使用Lease来保证多Replica的数据一致性,Master将Lease授予其中一个Replica,这个Replica会被称为Primary Replica,Primary Replica会给其他Replica分配一个序列号(serial order),然后其他Replica按照相同的顺序完成更新
下图是多Replica Chunk数据的更新步骤:
- Client向Master获取持有当前lease的Primary Replica和其他Replica所在的Chunk Server,如果没有lease,Master会将lease授予其中一个Replica。
- Master返回给Client所需的Replica情况,Client缓存该信息。
- Client将数据推送给所有Replica,每个Chunk Server会将数据存储在内部的LRU Buffer中,直到数据被使用或超时。
- 当所有Replica写入缓存成功后,Client会给Primary Replica发送写入请求,请求包含所有推送的Replica信息,Primary Replica接收到请求后为mutatiomutation分配序列号。
- Primary Replica将写入请求转发给其他所有replicas,每个Replica按照序列号完成本地数据更新。
- 所有Replica完成数据更新后,需要向Primary Replica发送响应信息表明完成。
- Primary Replica向Client发送响应,任何错误都需要回传给Client,由Client进行重试直到全部写入成功。
3.2. Snapshot
snapshot机制用于快速地创建文件或目录树的时间点Replica,不会影响原文件的可用性,也无需大规模的数据复制。GFS采用copy-on-write来实现snapshot机制,当Master接收到snapshot请求后,执行步骤如下:
- Master首先会撤销所有在chunk上未执行的所有lease写入请求,以确保创建的snapshot数据是一致的。
- 将操作写入Master的Operation Log
- Master为对应目录或文件的metadata创建一份拷贝,并指向同一份chunk
- 如果在 snapshot 之后,客户端尝试修改源文件(F)中的某个 chunk(比如 C):
- master 会为此写操作分配一个新的 chunk handle(C′)
- 并要求当前持有 C Replica的 chunkserver 创建一个 C′ 的Replica(内容复制自 C)
- 然后将写请求定向到 C′,而不是原 chunk C
GFS 中的 Snapshot 能够实现快速、一致和持久的时间点拷贝,其本质是一种命名空间的轻量级变更操作。借助于 master 对 namespace 的内存管理、操作日志持久化机制以及树形路径加锁策略,Snapshot 不仅具有极高的执行效率,也确保了系统的一致性和可靠性。
3.3. 集群操作
3.3.1. Chunk Creation
当Client请求写入新文件时,Master需要考虑以下三点:
- 哪些 Chunk Server 负责保存该 chunk 的初始Replica;
- 通常选多个机器,以满足Replica数(例如 3 个);
- 避免热点,平衡负载和磁盘利用率。
选取原则:
- 将新Replica存在在磁盘空间利用率较低的 Chunk Server 中,使得每个服务器磁盘空间利用率趋于平衡
- 对 Chunk Server 创建数量进行限流,防止大批写入请求同时打入同一台服务器
3.3.2. Re-replication
部分系统错误会使得Replica数量降低,这时Master需要将该Replica标记为丢失,并从剩余Replica中挑选优先级最高的作为源 Chunk Server,并将其克隆到新的 Chunk Server,Master会限制各个节点的克隆次数,防止克隆流量影响Client正常请求。
3.3.3. Rebalance
Master会定期重新检查当前Replica的分布状况,并将Replica移动到更合适的 Chunk Server,Rebalance操作会逐渐填满新加入集群的 Chunk Server。
3.3.4. Garbage Collection
Client发起文件删除请求后,Master只是将其重命名为一个包含删除时间戳的隐藏文件名,GFS不会立刻回收物理存储空间,它会在GC定期检查过程中判断时此类隐藏文件名中时间戳,是否超过配置时间(默认3天),若超过则删除其metadata和原始chunk数据。
异步延迟删除存在几个优点:
- 在分布式系统中简单可靠,提供了一个统一可靠的方式来做删除动作
- 存储回收异步执行,可以在系统相对空闲时进行调度
- 延迟删除可以在意外删除时做数据恢复
该方案同时存在缺点,无法立刻使用被删除文件的所占空间。
3.3.5. Stale Replica Detection
如果 Chunk Server 发生故障,并在宕机期间发生过数据变更,那么该节点的 Replica 与其它新Replica不一致,被称为Stale Replica,Master节点会在每个Chunk 维护一个version字段来区分,Master会在Chunk Server重启后通过HeartBeat请求获取到该节点中的Chunk Set相关信息,此时可以检查出其中的Stale Replica。并且Master会在GC中定期删除Stale Replica。
3.4. 高可用设计
3.4.1. Master
GFS 使用一个单个 Master负责管理集群的metadata(如命名空间、chunk 映射、访问控制等),但为了实现高可用性,它引入了Shadow Master,Shadow Master 是 Master 的“备份节点,以只读方式服务于Client请求,但不会处理修改类请求。如果主 Master 挂掉,虽然 Shadow Master 不自动接管,但它可以提供读取支持,降低系统可用性风险。
Master节点首先使用Operation Log对metadata持久化到磁盘中,并且Operation Log会被备份到其他机器上避免单点损坏,当Master节点崩溃会快速恢复,启动时会从最近的Checkpoint中读取metadata,再回放Operation Log以重建完整的metadata信息。
3.4.2. Chunk Server
GFS通过多Replica、故障检测与自动修复机制实现 Chunk Server 的高可用。每个 Chunk 默认拥有 3 个Replica,分布在不同的 Chunk Server 和机架中,避免单点或局部故障造成数据不可用。Master 节点通过周期性心跳与块报告监控 Chunk Server 状态,当发现Replica丢失或机器宕机时,会自动安排健康Replica做Re-replication。Chunk 使用版本号和 CRC 校验码确保数据一致性与完整性。写入过程由 Primary Replica协调,客户端支持从多个Replica中读写,增强了容错能力。此外,GFS 采用延迟删除与故障恢复自注册机制,支持 Chunk Server 恢复后的自动接入,进一步提升了系统整体的稳定性与可用性。
4. 总结
GFS的核心目标是容忍频繁的硬件故障、支持高吞吐和批量处理,在该需求背景下,GFS舍弃了强一致性指标,而是选择了高性能和简洁架构。Apache Hadoop生态中的HDFS是GFS架构的开源实现,采用相同 Master-DataNode 架构,GFS也和MapReduce、BigTable并称为Google三驾马车,这三篇论文基本上确定了业界大规模分布式存储系统的理论基础。