1. Intro
在此之前的分布式计算框架,例如 MapReduce,缺乏对分布式内存的复用能力。在 MapReduce 中,每一轮 Map 和 Reduce 任务之间的中间结果都会被写入磁盘,随后再从磁盘中读取用于下一阶段的计算。这种设计带来了大量的磁盘 I/O、数据复制和对象序列化/反序列化的开销,从而在许多迭代式或交互式的大数据应用中成为性能瓶颈,占据了绝大部分的执行时间。
为了解决上述问题,Spark 引入了弹性分布式数据集(Resilient Distributed Dataset,RDD)的抽象。RDD 是一个只读的分布式对象集合,可以并行操作,支持在内存中缓存中间计算结果,从而显著减少了 I/O 和序列化成本。RDD 提供了丰富的转换操作符(如 map、filter、reduceByKey、collect 等),使得开发人员能够以函数式编程方式,在大规模集群上构建高效、容错的内存计算任务。与此同时,RDD 通过血缘(lineage)信息来实现容错机制,即使节点失败也能基于操作链自动恢复数据,无需数据复制带来的额外存储成本。
2. RDD模型设计
RDD是一个只读,可分区、支持并行计算的数据集,可以通过操作符将RDD转换成新的RDD,并且两个RDD之间存在血缘关联。
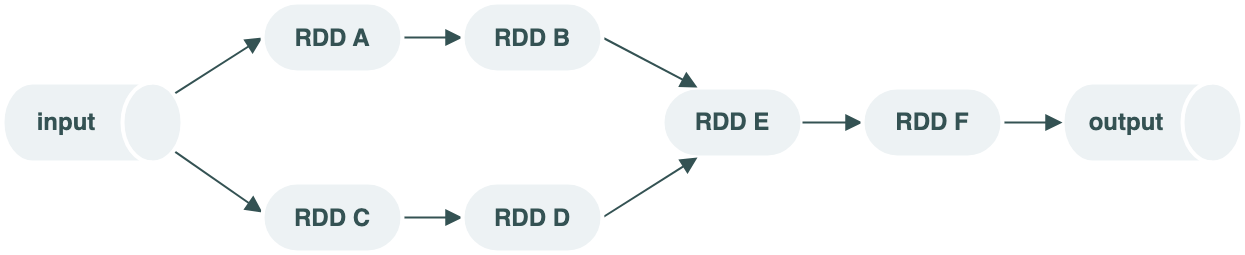
RDD的弹性体现在:
- 存储:内存不足时可以和磁盘进行数据交换
- 计算:计算出错时支持重试
- 容错:数据丢失可以自动恢复
- 分区:支持重新分区
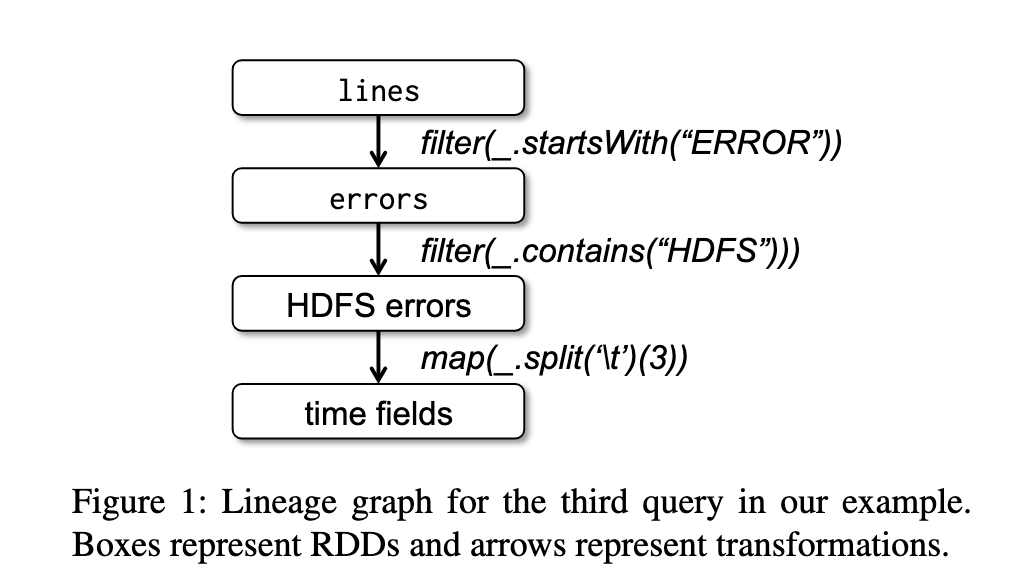
下面是一个从HDFS读取文本文件,并执行计算的案例:
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
// Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS"))
.map(_.split(’\t’)(3))
.collect()
下图是上述案例中RDD血缘关系图,不同的RDD之间通过转换操作符进行连接。
2.1. Spark编程接口
Spark提供了以下转换操作:

在对RDD进行转换时,会产生血缘依赖关系,不同的转换操作可能产生不同的依赖关系,例如map、filter、union等操作会产生窄依赖关系,join、group by操作会导致宽依赖关系
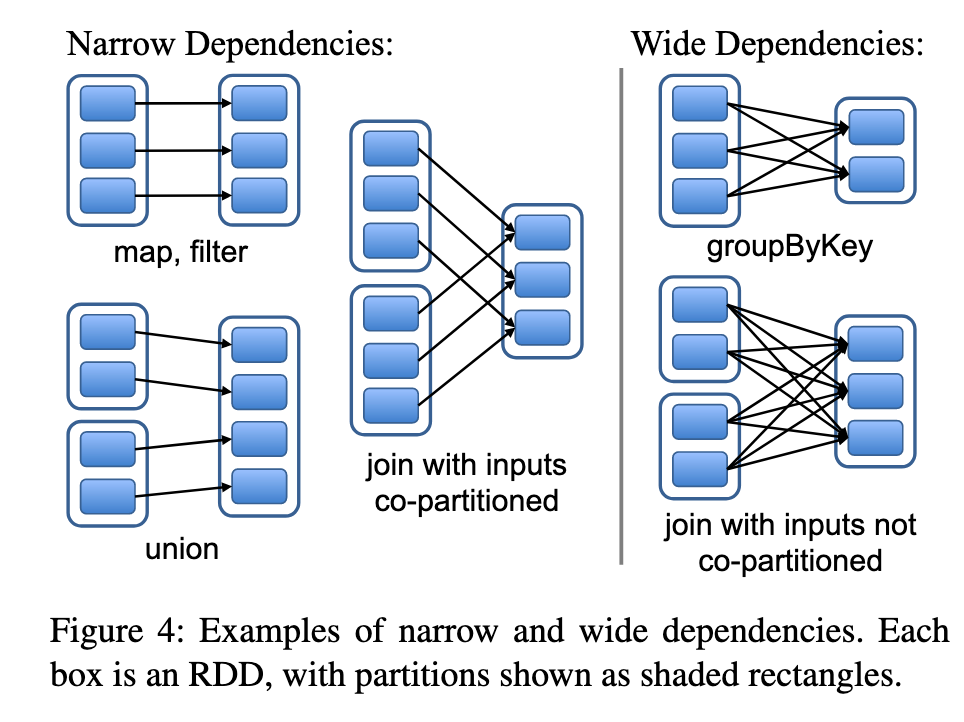
上述提到的宽窄关系,主要影响以下几个方面:
| 影响方面 | 窄依赖 | 宽依赖 |
|---|---|---|
| 调度 | 可以进行 流水线调度 | 需要 shuffle 重分区和 barrier |
| 容错恢复 | 只需重算一个 partition | 可能需要重算整个父 RDD |
| 性能开销 | 无需 shuffle,性能开销小 | 涉及 shuffle,可能产生大量 I/O 和网络传输 |
| 并行度 | 高:partition 可以独立运行 | 受限:存在阶段边界(stage boundaries) |
| 任务划分(stage) | 可在同一 stage 执行 | 通常会产生新的 stage(触发 job 切分) |
3. Spark实现
初版Spark使用约1.4万行Scala代码实现,使用Memos进行调度,并支持接入Hadoop,每个Spark任务都拥有自己的driver和worker节点。
3.1. 作业调度
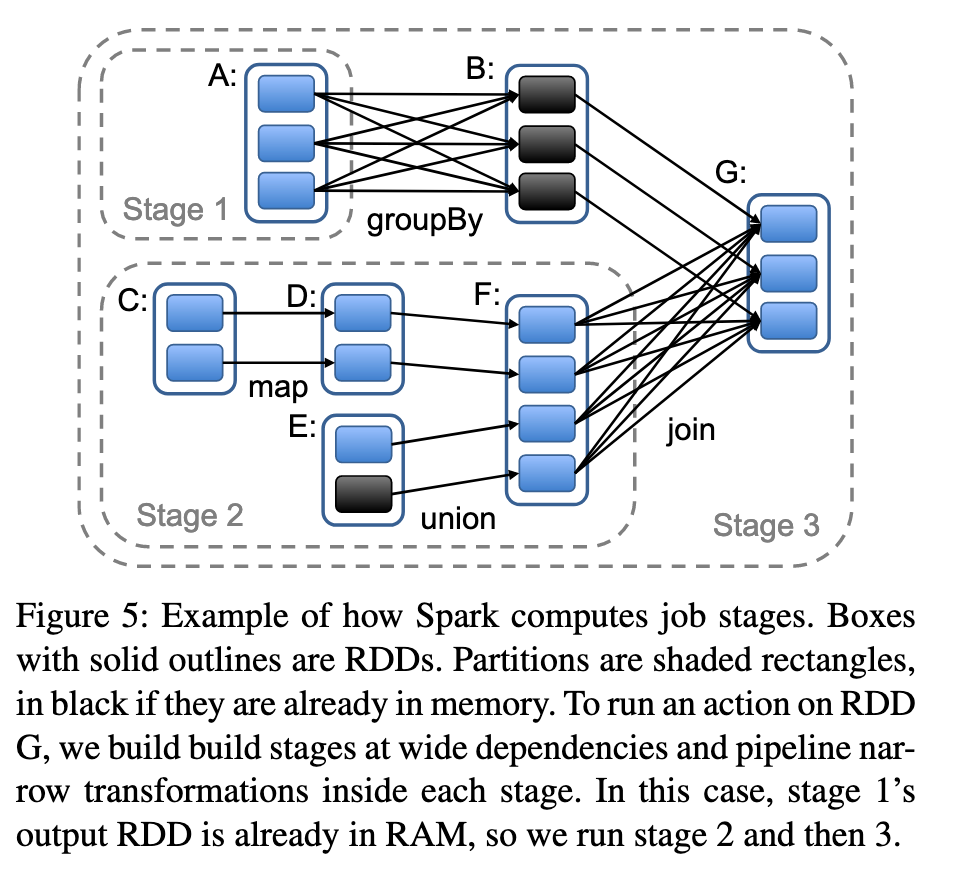
Spark作业调度机制具备故障恢复能力,会根据RDD的血缘关系,来构建该任务需要执行的stage的DAG,要求每个阶段尽量包含更多的窄依赖操作,stage的边界是宽依赖所需执行的shuffle操作,若执行阶段任一Stage执行失败,只要父类RDD仍然可用,就可以重新调度运行。
3.2. 内存管理
Spark提供了三种持久化RDD的方案:Java对象的内存存储、序列化后的内存存储、硬盘存储,使用LRU策略来管理内存。Spark集群中每个任务都有独立的内存空间,互不影响。
3.3. Checkpoint
任务调度中提到,可以通过RDD血缘关系进行故障恢复,但是对于血缘关系过长的RDD来说,耗时过长,可以将RDD checkpoint到持久化存储中能加速故障恢复的过程。
4. 总结
本论文提出了 Resilient Distributed Datasets(RDD)这一核心抽象,用于构建容错且高效的分布式内存计算系统。RDD 是一个只读的分布式对象集合,支持以函数式方式进行并行操作,具备基于血缘关系(lineage)的容错机制。通过在内存中缓存中间结果,RDD 有效减少了迭代式和交互式计算中频繁的 I/O 与序列化开销。相较于传统如 MapReduce 等模型,RDD 在性能与可编程性方面均有显著提升。该论文的思想构成了 Apache Spark 的核心基础,极大推动了大数据计算框架的发展,使得 Spark 成为支持机器学习、图计算、大数据处理等场景的主流平台之一。