1. Intro
《Megastore: Providing Scalable, Highly Available Storage for Interactive Services》是Google于CIDR 2011上发表的一篇重要论文,该论文介绍了 Google 内部使用的一种分布式存储系统——Megastore,它在强一致性与高可用性之间实现了权衡,构建于BigTable之上,引入了事务机制、同步复制、SQL查询接口等,它将RDB的事务机制、一致性和NoSQL高扩展性结合起来。MegaStore对数据进行分区,并对每个分区使用Paxos算法实现同步复制,在分区内支持完整的ACID语义。
2. 存储设计
2.1. 逻辑设计
MegaStore将数据划分为多个Entity Groups,每个Entity Group都独立进行Paxos数据复制,并且该Group内部支持ACID语义。
一个 Entity Group 是一组相关联的数据实体(records),这些实体共享同一个 分布式事务边界 和 Paxos日志,在这个组内支持强一致的事务操作。
例如一个Group可能同时包含两个Data Model:
<entitygroup name="UserGroup">
<table name="User">
<column name="user_id" key="true"/>
<column name="name"/>
</table>
<table name="Settings">
<column name="user_id" key="true"/>
<column name="dark_mode"/>
</table>
</entitygroup>
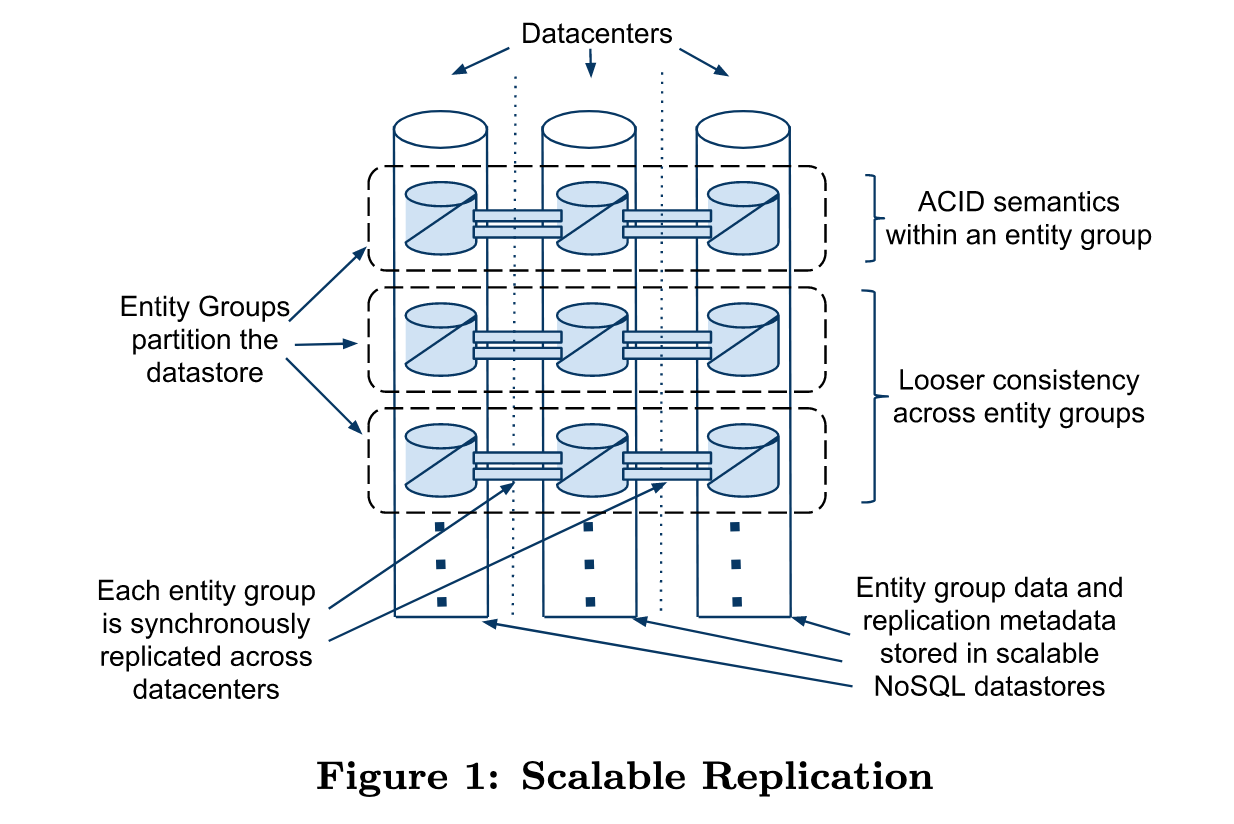
通过上文可知,Group越大,单个Group的Paxos日志负载越高,Group越小,跨Group事务越容易发生,性能越差,因此如何选定Entity Group的边界十分重要。论文中提到:Megastore 要求应用开发者根据访问模式来决定Entity Group边界。开发者需要遵循以下规则:
- 高频事务操作的数据放在一个Entity Group
- 跨Group的事务代价较高,尽量避免
- 避免将大量数据放进一个Group,可能导致Paxos日志并发性能瓶颈
2.2. 物理存储设计
MegaStore的物理存储层使用BigTable实现,每个Entity Group的数据都存储在BigTable的连续行,来提高系统吞吐量和数据命中效率。
Megastore 并不是从头开发一个全新的存储引擎,而是使用BigTable作为底层存储引擎,负责数据的持久化、分片以及数据中心内的存储和基本读写,跨数据中心的数据复制,则由MegaStore自行实现。
Megastore 通过精心设计 row key规则,将一个 Entity Group 内的所有记录 编码为一组具有相同前缀的 row keys,以实现数据局部性。
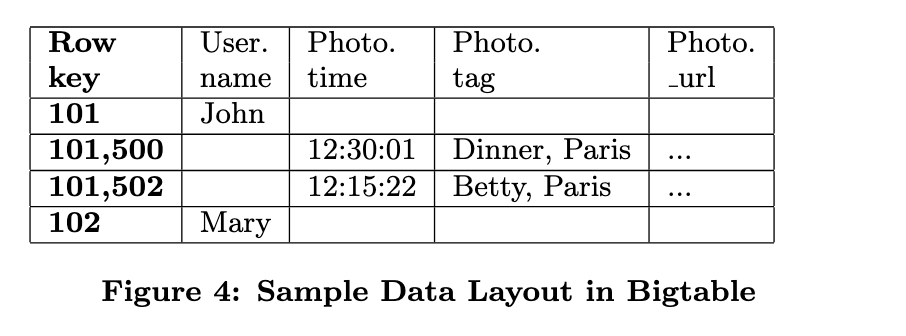
2.3. 数据模型
MegaStore数据模型的定义介于RDB和NoSQL之间,table有 root table 和 child table 之分,每个 child table 必须声明一个具有区分意义的外键指向root table。Megastore 要求每张表都有 主键(Primary Key),这是因为因为:
- 数据底层存储在 Bigtable,需要唯一 row key;
- 主键用于组合 row key,从而将同一个实体组的数据物理聚集在一起。

3. 事务与并发控制
每个Entity Group都可以当成一个mini database,一个事务发起之后,会先将事务的操作 写入WAL,然后更新持久化数据,MVCC机制可以通过BigTable特性来实现:BigTable允许对同一行存储不同时间戳的值,因此事务读取选择最新的时间戳,独立于写事务。
MegaStore提供三种读取方式:当前读、快照读、不一致读,其中当前读和快照读在单个Entity Group内完成
- 当前读会读取当前最新已提交事务的数据版本,如果存在并发事务写入,则会阻塞只到写入事务完成后读取
- 快照读会获取最新的已提交事务时间戳,并读取这个时间戳的数据,即使存在写入事务也不影响读取
- 不一致读则直接读取BigTable中的数据
3.1. 读取操作
一次完整写事务生命周期:
- Read:执行一次当前读,获取当前 Entity Group 的 Paxos 日志的末尾位置,也就是确定下一个可以尝试写入的位置。
- Application Logic:所有的更新操作(mutations)被打包成一个 日志条目(log entry),给该entry分配一个比之前更新的 时间戳(timestamp),确保时间单调递增。
- Commit:- 通过Paxos 协议尝试将这条日志追加到 Entity Group 的日志中。
- Apply:Paxos各副本接受写入后,执行真正的写操作,将数据写入到BigTable中,并更新索引表和数据表
- Clean Up:清理事务产生的无关数据,例如中间状态等
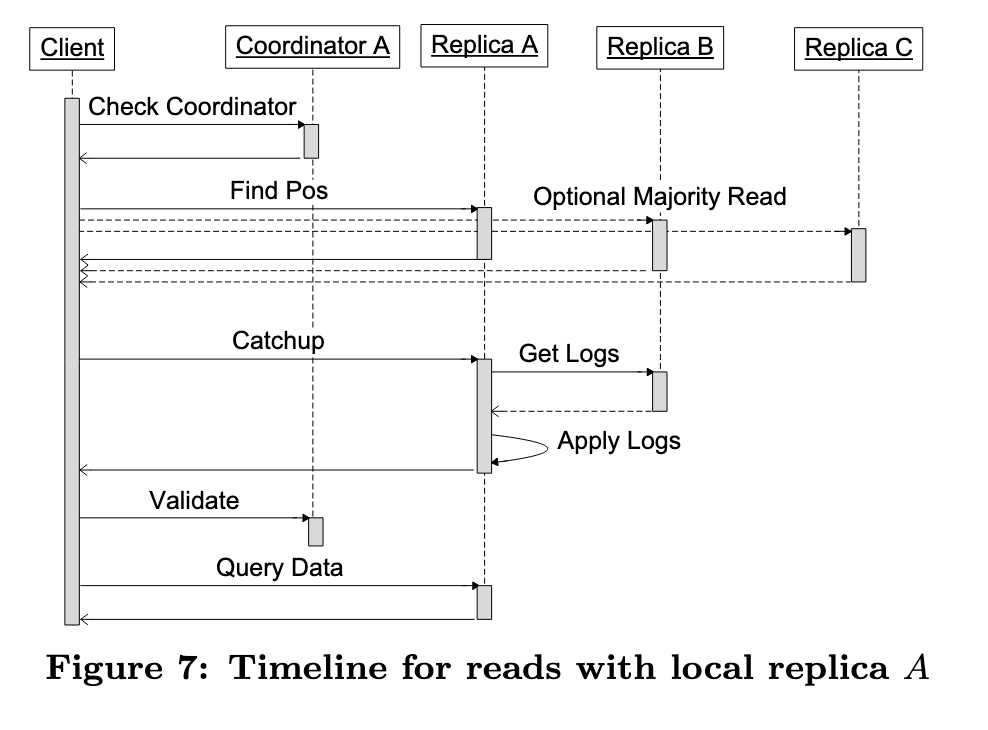
多个客户端可能写入同一个日志位置,MegaStore使用乐观锁让各个客户端竞争写入,未获取到锁的事务会中止,并重新开始新一轮的事务,并使用Advisory Locking机制,减少高并发事务场景下的频繁重试,
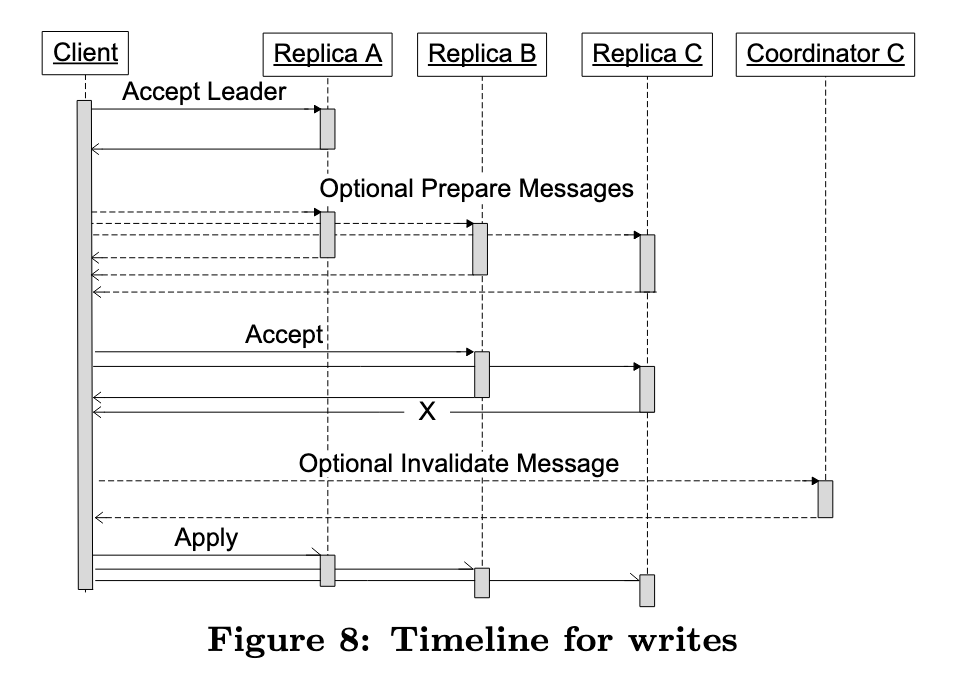
3.2. 写入操作
- Accept Leader:- 向当前 Paxos log position的leader 提交编号为 0 的提案。如果成功,直接跳到第 3 步(Accept)。
- Prepare:如果没抢到编号 0,执行标准的 Paxos Prepare 阶段。提出一个比之前更高的编号。
- Accept:将值提交给副本,要求执行 accept 投票。如果获取投票失败,进行退避backoff后重试 Prepare 阶段。
- Invalidate:对于没有接受该写入的完整副本,必须把它们的 Coordinator 中状态 标记为失效。
- Apply:向多个Replica发送Apply写入请求
3.3. 跨分区事务
MegaStore中每个Entity Group是事务边界,当事务操作存在跨Entity Groups的情况时,MegaStore提供了Queue来解决事务消息传递,Queue 的三个典型用途:
- 跨 Entity Group 的操作(如多个用户或订单的同步状态更新)
- 批量写操作:多个更新聚合成一个事务操作(发送多条消息)
- 延迟执行任务(如异步处理日志、通知、邀请等)
每条消息有唯一的发送方和接收方 Entity Group,在一次事务操作中,读取消息和写操作是原子性的,Queue的异步机制可以提供极大的吞吐量,但是无法保证跨分区事务的幂等性和强一致性,因此MegaStore同时提供了更重的2PC协议解决强一致写入的场景。
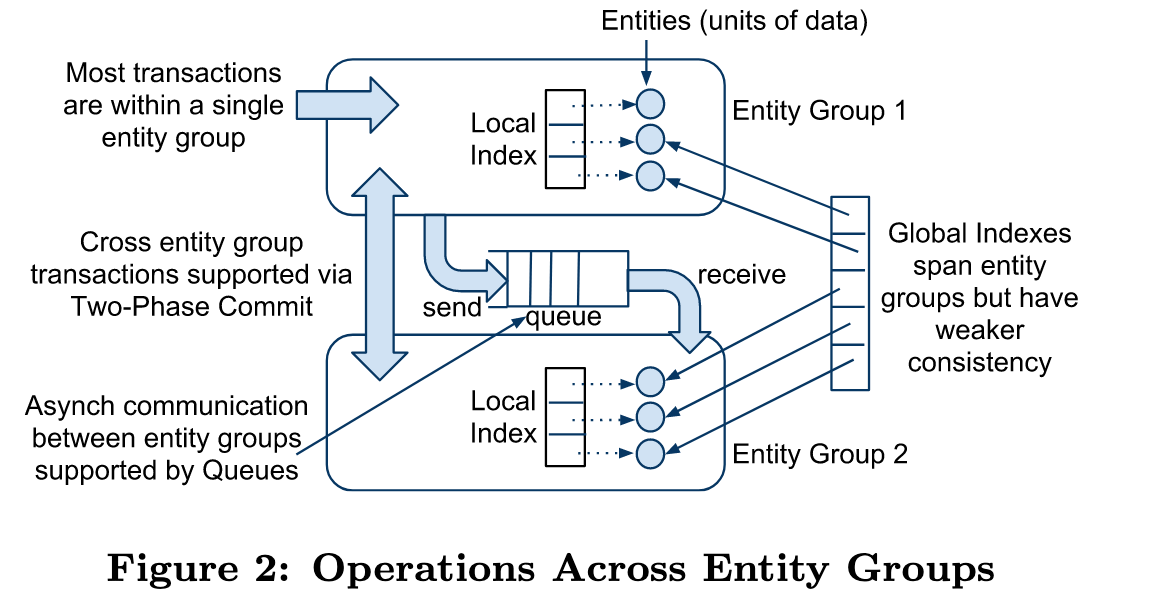
2PC需要协调多个Paxos实例,延迟较高,并更容易产生事务冲突,但是能保证写入数据幂等性和自动回滚。
4. 数据复制设计
Megastore采用的Paxox协议主要用于 每个 Entity Group 的 write-ahead log (WAL)。每个 Entity Group 维护一条 独立的、单调递增的日志序列,通过 Paxos 算法在多个副本之间复制这条日志。
整个MegaStore集群架构如图所示,集群中的Paxos实例分为Full Replica和Witness Replica,这里每个Replica都位于不同的数据中心,其中Full Replica存储全量的数据和Paxos日志,而Witness Replica只负责投票和存储Paxos日志,这样设计既可以提高写入可用性,也能降低部分存储成本。
Coordinator承担发起Paxos协议轮次并协调副本之间达成一致的责任,通过Coordinator实现可以避免并发写入冲突。每个副本所在的数据中心都有一个对应的 Coordinator。同时Coordinator还负责维护一个集合来存储当前Replica已完成最新数据复制的Entity Group,并允许客户端直接读取。
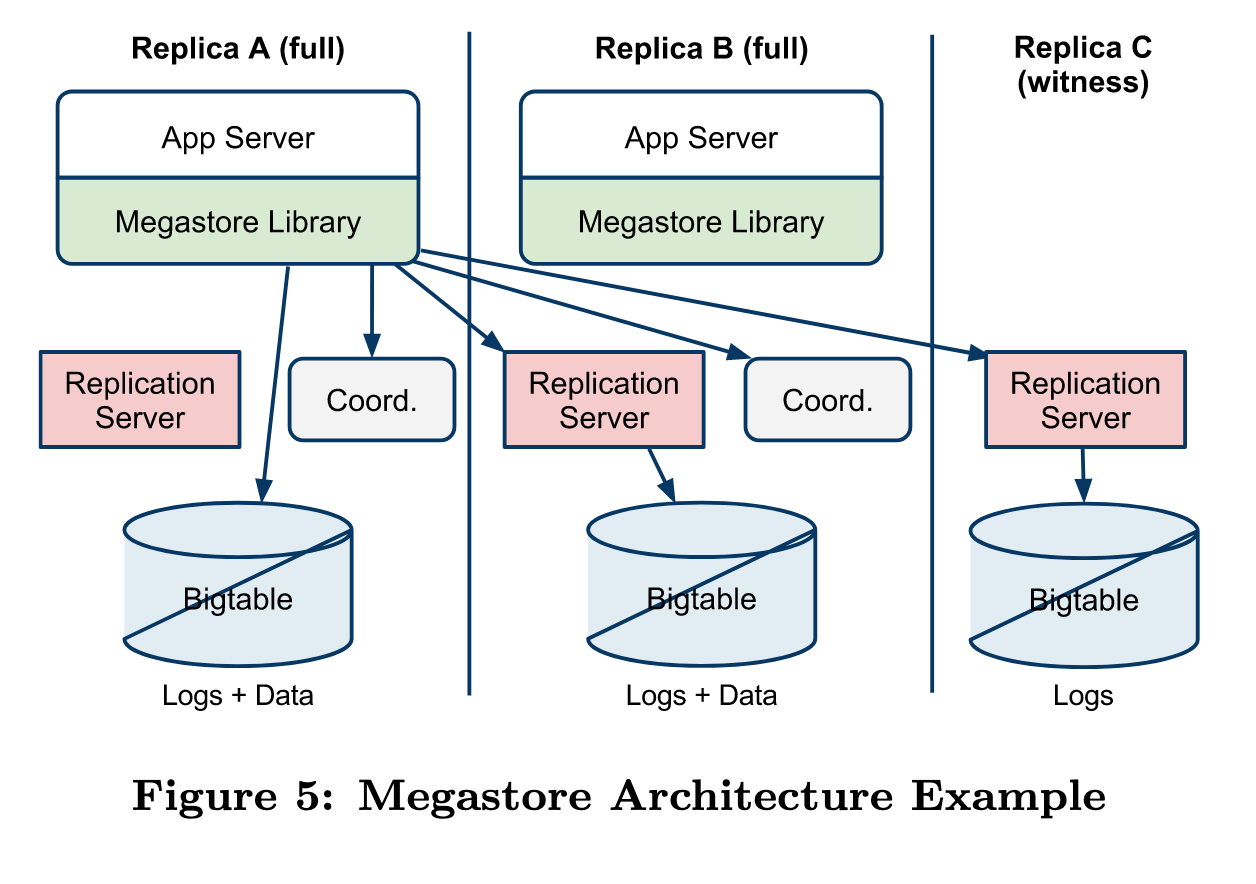
从实现上来看,Coordinator只是一个轻量级线程,并不会访问磁盘和数据库等组件,启动时会创建Chubby锁,MegaStore可以通过Chubby检查Coordinator是否可用。
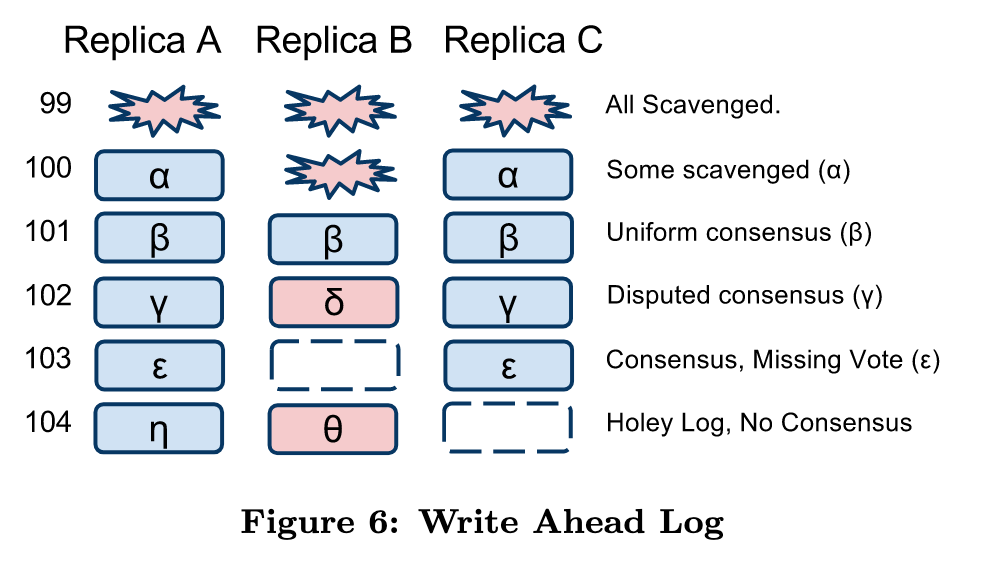
为了让某个副本即便经历过故障恢复后仍能参与写入投票(quorum),Megastore 允许它接受乱序的 Paxos 提议(out-of-order proposals),如果某个Replica的日志前缀缺失了某些位置(比如有 101 和 103,但没有 102),我们就称日志有“洞(holes)”。
5. 总结
Megastore 是 Google 构建的一种分布式存储系统,结合了关系型数据库的事务支持和 NoSQL 的可扩展性,主要面向交互式在线服务。它通过将数据划分为“实体组”(Entity Groups),以支持组内强一致的多行事务。Megastore 使用 Paxos 协议进行跨数据中心的日志复制,实现高可用性与线性一致性,具备多副本写能力。每个副本都有一个Coordinator,负责本地事务推进与副本状态维护。为降低写入延迟,Megastore 对 Paxos 进行了多项优化,如单轮提交、并行日志实例及使用轻量的 Witness 副本。Chubby 锁服务则用于成员检测和主选举。尽管在网络分区下会牺牲部分可用性以保证一致性,Megastore 仍能支撑 PB 级数据规模与每天数十亿次访问。其设计理念为 Spanner 和后续云原生数据库奠定了基础。