1. Intro
《MapReduce: Simplified Data Processing on Large Clusters》是Google发布于 OSDI 2004的一篇分布式计算领域论文,奠定了大规模数据处理的基础架构范式,是大数据领域的里程碑式工作。该论文系统性地提出了一种简洁的编程模型,使开发者可以方便地在大规模分布式系统中进行并行计算,而无需关注底层的容错、调度、数据分片等复杂问题。通过将任务划分为 Map 和 Reduce 两个阶段,系统自动完成任务调度、节点容错与数据传输,大幅提升了开发效率与系统可扩展性。
2. 编程模型设计
计算任务大都可以被抽象为map和reduce操作,首先对输入数据中每条逻辑记录应用map操作以计算出一系列的中间键值对,然后对所有键相同的值应用reduce操作以合理地整合这些派生数据。
MapReduce执行过程可以简单理解为:
- 利用一个输入的key/value pair集合来产生一个输出的key/value pair集合。
- 自定义的Map函数接受一个key/value pair输入,然后产生一个中间key/value pair集合。会将相同key和对应多个value值集合在一起传递给reduce函数。
- 自定义的Reduce函数接受上面的集合,合并这些value值,形成一个新的value值集合。
Map Reduce函数可以抽象成以下形式:
map(k1, v1) -> list(k2, v2)
reduce(k2, list(v2)) -> list(v2)
2.1. 以wordcount为例
考虑一个业务场景:需要统计大批量文件中每个单词的出现次数,开发者编写的伪代码如下:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
通过两阶段任务,将原始计算需求拆分为:先计算每个单词出现的次数,再通过reduce阶段合并计算每个单词出现次数总和。
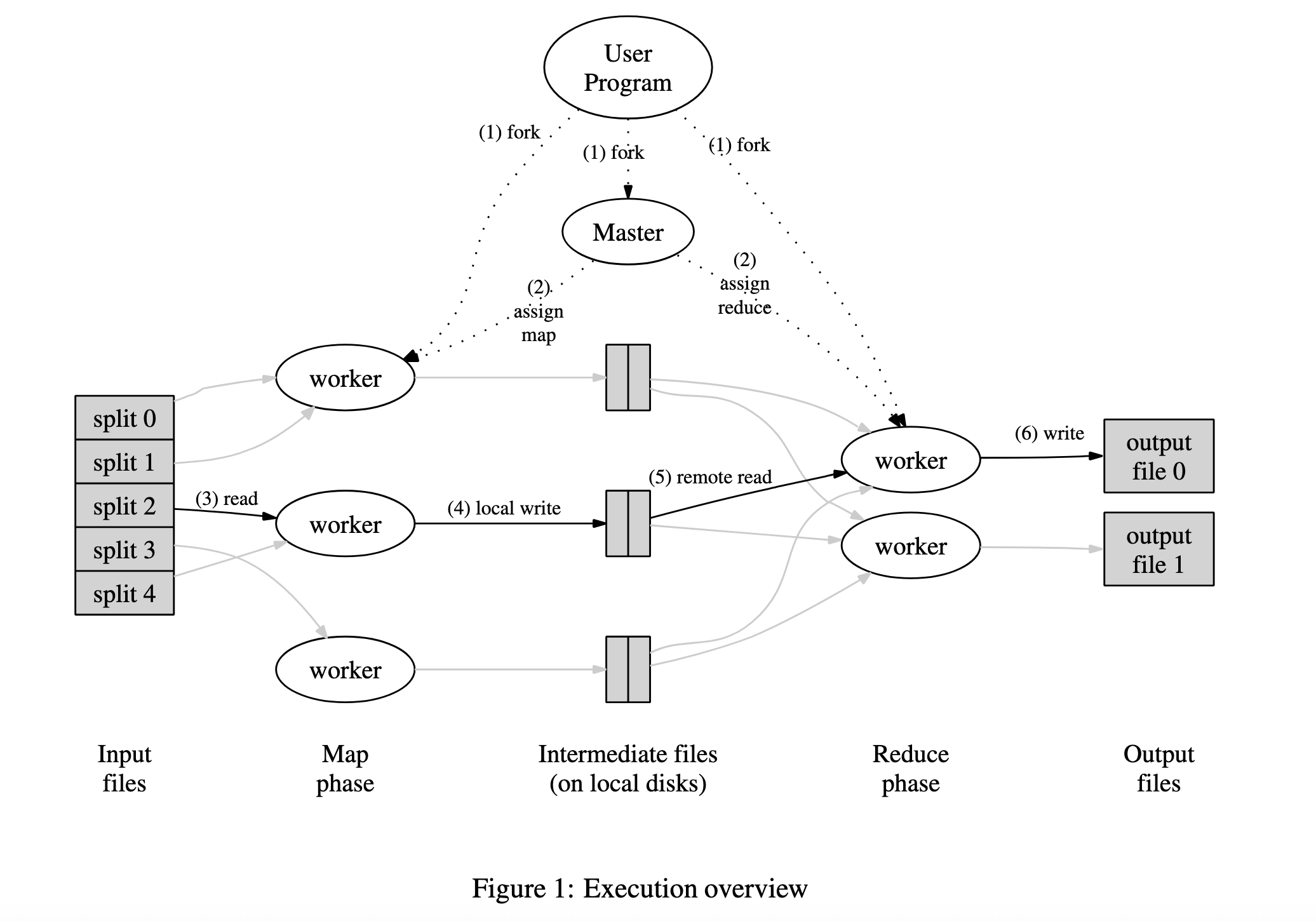
2.2. MapReduce执行概览
首先将输入数据自动分割成$M$个分片,Map函数在多台机器上分布式执行。Map函数生成的中间key-value pair会被分去函数分割为多个分区,这样Reduce函数也可以摄取这些分区进行分布式执行,MapReduce大致执行流程如下:
- 用户程序首先将输入文件切分为$M$个分片,通常是16MB=64MB之间(可改配置项)
- Master节点负责分配管理map和reduce任务,它会选取空闲的Worker节点并为其分配任务
- Worker节点从数据分片中读取内容,并完成Map任务,中间计算结果key-value pair存储在内存中
- 存储在内存中的中间结果会定期写入本地磁盘,写入数据会被Hash Partition Function划分为$R$个区域,写入完成后这些信息会被发送给Master
- Master会将所有 Map 任务产出的、与分区$R$相关的中间文件的位置信息(即在哪些 Map Worker 的哪个本地路径下)发送给这个 Reduce Worker,Reduce Worker会发起RPC调用从Map Worker获取分区数据,读取完成后按照key进行排序分组(相同key分为一组),这个过程中如果数据量过大则使用外部排序
- Reduce Worker遍历所有数据,将每个key-value pair传递给用户定义的reduce函数,reduce函数的输出会被追加到磁盘输出文件中
- 当所有map和reduce任务执行完毕后,Master会唤醒用户程序,来读取MapReduce程序的$R$个输出文件,通常用户程序不需要执行合并,这里的结果通常会被作为下一次MapReduce的输入。
2.3. Master元数据信息
- 每个Map和Reduce任务的状态
- Worker机器的标识
- 各个已完成的Map任务$M$个文件分区位置
3. 容错设计
Google在论文中也明确了无论底层发生了各种复杂的故障(Worker 宕机、网络分区、任务重试),都不会影响MapReduce任务执行结果的一致性,这主要依赖于两个关键机制:任务输出的原子性提交(Atomic Commits) 和 确定性函数(Deterministic Functions)
确定性函数是指:用户提供的两个函数每次执行结果都是一致幂等的。而任务输出的原子性提交确保了任务retry不会导致数据重复或不一致。Map 和 Reduce 任务的提交机制略有不同。下面分别阐述。
一个 Map Worker 在执行任务时,不会直接修改任何全局状态。它会把输出写入到它自己本地磁盘上的$R$个临时文件中。这些文件在此时对系统的其他部分是不可见的。当 Map 任务成功完成后,它会向 Master 发送一个消息,其中包含了这$R$个临时文件的位置(文件名和所在 Worker 的地址)。Master 收到这个消息后,会将这些文件的位置信息记录在自己的一个数据结构中。这个记录动作,就是 Map 任务的Commit。一旦被记录,这些中间文件可供 Reduce 任务拉取的数据源。
那么当发生故障时:
- Master宕机:Master会定期将metadata做checkpoint持久化到磁盘,如果Master节点宕机,新Master从最新的checkpoint恢复,与GFS类似,采用单Master节点以提升架构简洁性。
- Worker 宕机:如果 Map Worker 在完成前宕机,它本地的临时文件就丢失了,Master 也永远不会收到完成消息。Master 会将该任务重新分配给另一个 Worker,一切从头开始,对最终结果没有影响。
- 任务重试(Straggler):假设任务A被 Master 认为太慢,启动了一个备份任务A’。现在 A 和 A’ 都在运行。
- 如果 A’ 先完成,它会向 Master 报告。Master 记录下 A’ 产生的临时文件位置,并视 Map 任务完成。
- 如果 A 也完成了,它也会向 Master 报告。但此时 Master 发现这个 Map 任务已经被标记为“完成”,它会直接忽略来自 A 的消息。
一个 Reduce Worker 在执行时,将其聚合后的最终结果写入到全局文件系统(GFS/HDFS)上的一个临时文件中,例如 mr-out-0-temp。当任务成功完成后,Worker 会对这个临时文件执行一个原子性的 rename 操作,将其重命名为最终的输出文件名,例如 rename("mr-out-0-temp", "mr-out-0")。这里的rename操作原子性由GFS/HDFS这类文件系统来保证。
4. 设计优化
4.1.1. 存储位置
MapReduce的master在调度Map任务时会考虑输入文件的位置信息,尽量将一个Map任务调度到离其输入文件Replica较近的机器上。这样可以减少网络带宽的消耗。
4.1.2. 任务粒度
前文中提到Map阶段会被拆分成 M个片段,Reduce拆分成R个片段执行,理想状态下$M + R$应当远大于Worker。
但是实际上对M和R的取值有一定的客观限制:
- master必须执行$O(M + R)$次调度
- 需要在内存中保存$O(M * R)$个状态
R由用户指定的,实际使用时需要选择合适的M,以使得每一个独立任务都处理大约16M~64M的输入数据。R值应该设置为worker机器数量的倍数。
4.1.3. 备用任务
如果一个Worker花了很长时间才完成最后几个Map或Reduce任务,会导致MapReduce操作总的执行时间超过预期。产生以上现象的原因有很多,例如:磁盘性能下降、网络时延等情况。因此需要使用一个机制来减少这种现象:当一个MapReduce操作接近完成的时候,Master调度备用任务进程和原始分配Worker同时执行,其中任何一方执行完成后,该任务会被标记已完成,极大减少了MapReduce执行时间。
4.1.4. 自定义分区函数
MapReduce允许用户自定义所需要的Reduce数量或输出文件数量R,默认提供的分区函数$hash(key) mod R$能产生非常平衡的分区,但是,其它分区函数对一些key的分区效果较好,例如输入的key值是URL,我们希望每个主机的所有条目保持在同一个输出文件中。
4.1.5. 顺序保证
在给定的分区中,中间key-value pair需要按key进行排序,有序性可以保证高效的随机访问。
4.1.6. Combiner函数
某些情况下(以wordcount为例),Map函数产生的中间key值相同的键值对,并且用户自定义的Reduce函数能接收完成相同key合并后的数据,因此允许用户指定一个可选的combiner函数,该函数首先在本地将重复数据进行一次合并,然后再提供给Reduce函数用于计算。
Combiner函数会在会在每台执行完Map函数的机器上执行,通常Combiner和Reduce处理逻辑类似,这种进行网络IO之前预先合并操作,极大减少了多余的网络通信次数。
4.1.7. 输入/输出的类型
MapReduce提供了多种输入格式的支持,并且提供了Reader接口供用户实现自定义格式,可以通过实现该接口,从数据库或内存中读取待处理数据。
4.1.8. 跳过损坏的记录
有些时候用户程序中的Bug会导致Map/Reduce函数在处理记录的时候发生crash,常用的做法是修复Bug后再执行MapReduce操作。某些情况下,忽略问题数据是可以接受的,因此提供了一种执行模式,MapReduce会检测哪些记录导致了crash,并且会跳过这些记录不做处理。
每个Worker进程都设置了信号处理函数来捕获内存段错误和总线错误。在执行MapReduce之前,通过全局变量保存记录序号。如果用户程序触发了一个系统信号,消息处理函数会通过UDP向Master发送处理的最后一条记录的序号,当master看到处理某条记录失败多次后,Master标记此条记录将不会被处理。
4.1.9. 数据可视化
Master提供了HTTP服务器来显示状态信息,用户可以监控各类信息。包括任务完成数量、任务处理数量、执行时间、资源占用等。
4.1.10. 计数器
MapReduce提供了Counter来统计不同事件发生次数,例如用户希望在WordCount案例中,统计所有处理的单词数量。每个Worker会定时将Counter上报给Master,并由Master完成相加计算,用户可以在分析页面查看任务的计算进度。
5. 总结
MapReduce 在分布式计算领域占据着开创性和奠基性的地位,这一模型成为后续分布式计算框架的核心思想来源。它由 Google 于 2004 年提出,首次以高度抽象的方式,将复杂的分布式计算任务简化为两个核心操作:Map 和 Reduce,从而极大地降低了大规模并行计算的开发门槛。在当时,分布式系统开发面临诸如节点失败、数据分布、任务调度等诸多挑战,而 MapReduce 的设计通过自动化处理这些底层细节,实现了容错性强、易扩展的计算框架。