1. Intro
Borg 是支持Google大规模数据中心计算的集群管理系统,其设计理念和工程实现对后来的 Kubernetes、Omega 等系统产生了深远影响。Borg 通过在共享集群上高效调度和管理成千上万的任务,实现了资源的高利用率、任务的高可靠性以及灵活的多租户隔离。论文介绍了 Borg 的整体架构、调度机制、容错设计和运维经验,揭示了支撑谷歌内部服务(如搜索、Gmail、YouTube)运行的关键技术。作为早期的超大规模集群管理系统,Brog提供了以下三个优势:
- 隐藏底层资源管理和故障处理细节,使用户专注于应用开发。
- 提供高可靠的集群管理系统
- 支持上万台机器高效运行
Borg 的创新在于将分布式资源抽象为可调度的统一资源池,并结合任务优先级、抢占机制、作业声明式配置等理念,为现代云计算和容器编排系统奠定了基础。
2. 架构设计
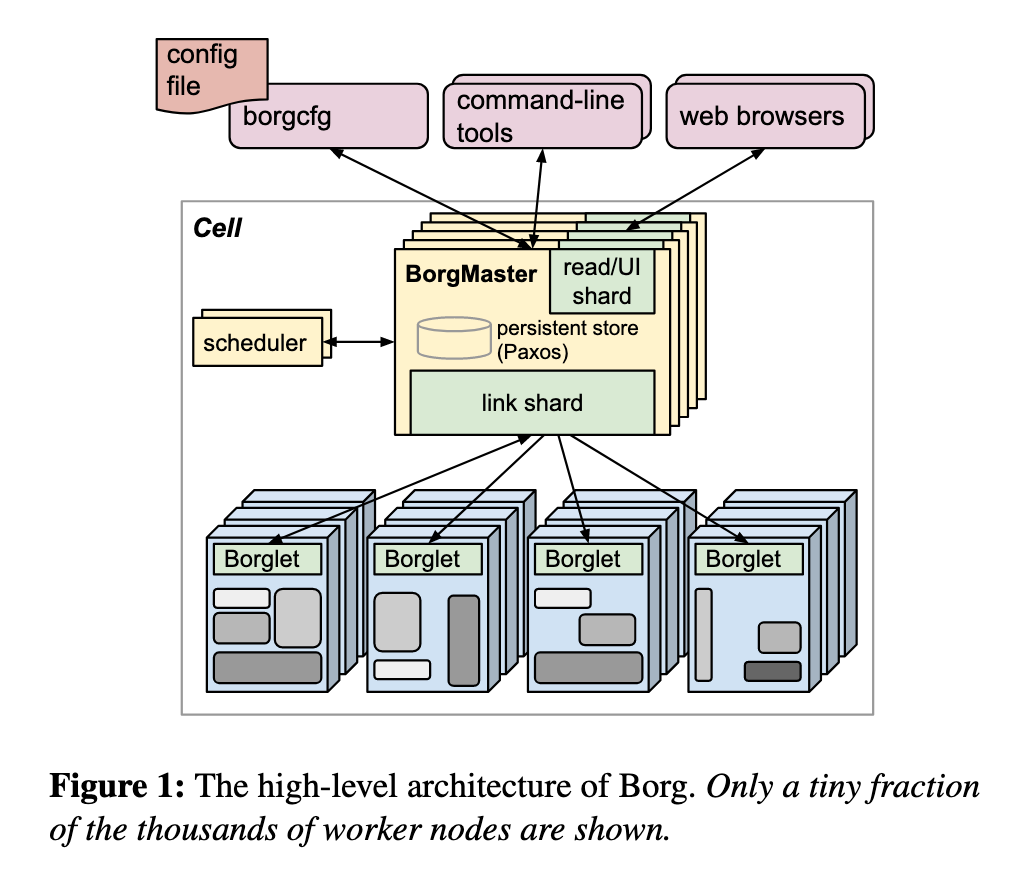
2.1. 架构简述
Brog系统由以下组件构成,与Kubernetes架构几乎一致:
- Cluster/Cell:一组机器集群,由大量worker节点(Borglet进程)和BorgMaster组成
- BorgMaster:Cell控制器,负责处理来自用户的所有请求,管理Cell中所有Borglet的状态,以及调度和启动任务。由集群组成,使用Paxos协议确保副本的数据一致性。
- Borglet:运行在每个worker节点上,运行BrogMaster分配的任务,负责监控本地任务的状态和资源使用情况,并定期上报给BrogMaster。
- Scheduler:当新Job被提交到BrogMaster后,Scheduler负责扫描待处理任务,并按照任务优先级,在Cell中寻找合适的Borglet来运行,找到Borglet后通知BorgMaster下发Job,通常Scheduler集成在BrogMaster中。
2.2. Job / Task
用户以Job的形式提交给Borg,Job由一个或多个Task组成,每个Task对应着一组Linux进程,每个Job只运行在同一个Cell中。
Cell主要运行两种Task:
- 应该永不停止的、长期运行的服务,处理时间较短且对网络延迟敏感的请求。
- 批处理作业,执行时间较长,例如MapReduce等
Borg通过任务优先级和配额,合理分配集群资源,优先级表示Cell中运行的Job相对重要性,配额用来决定允许哪个作业可以被调度,配额是指特定时间段的资源使用数量。
Borg 为每个Task创建了一个固定的 BNS 域名(Borg Name Service),使得其他Task可以访问到该服务。
2.3. BorgMaster
BorgMaster由两个进程组成:BrogMaster主进程和scheduler进程,其中主进程负责处理client的RPC请求,并与Borglet通信,提供了Web UI,BorgMaster逻辑上是单个进程,实际上有五个replica,每个replica都在内存中维护了Cell的状态,replica基于Paxos协议组成了一个高可用的分布式系统,其中有一个Master节点,负责处理所有变更Cell状态的RPC请求。某个时刻BrogMaster会创建checkpoint,以定期快照和变更日志的形式,保存在Paxos存储中。
2.4. 调度
当client提交一个Job后,BorgMaster会把它持久化道Paxos存储上,并将这个Job中所有的Task都加入到等待队列中,Scheduler会异步扫描等待队列,将Task分配到合适的机器上。Borg调度算法有两个步骤:
- 可行性检查:找到可以运行Task的一批机器
- 评分:从中选择合适的机器
Borg早期使用优化后的E-PVM算法进行评分,这个算法会把负载分散到所有的机器,但是导致了资源的碎片化,对突如其来的大型任务支持性较差。最佳匹配算法与之相反,挨个对机器资源进行分配, 这样会有空闲机器来处理大型任务。
2.5. Borglet
Borglet是部署在每台机器上的proxy进程,负责启动、停止Task,并需要将本机状态上报给BorgMaster,每个BorgMaster replica会负责一个无状态的link shard来处理部分的Borglet的通信,来减少Master的更新负担。
2.6. 扩展性设计
Borg支持使用单独的BorgMaster管理有着数千台机器的Cell,Cell可能每分钟有10K的任务被提交到集群。早期BorgMaster使用简单的同步循环实现scheduler,为了处理更多的任务,Borg的scheduler被分离为单独的进程,Scheduler会重复处理流程如下:
- 从选举出来的BorgMaster获取状态变更数据
- 更新自己的本地副本状态
- 执行一轮调度来分配任务
- 将分配信息发送给Master
- Master接受数据,如果分配计划不合理或者过时,会等待下一轮调度。
Borg在性能优化上的方法如下:
- 缓存评分信息:Borg会缓存计算得出的机器评分,用于下次调度使用,如果机器属性更新,则会触发缓存失效
- 任务等效类:一般来说,同一个Borg作业的任务都有相同的请求和约束,Borg只对等效类中的一个任务做可行性检查和评分,而不是遍历计算所有的任务
- 适度随机:Scheduler可能会随机抽取机器,直到找到足够多的可用机器并完成评分,从中挑选最合适的分配任务
2.7. 隔离
Borg使用Linux的chroot作为机器的安全隔离机制,Google的AppEngine使用VM和安全沙箱运行外部软件,每个运行在KVM进程的VM,作为一个Borg任务来运行。
3. 设计缺陷
Borg的部分设计存在缺陷,这些经验教训也改善了Kubernetes,例如:
- 将作业作为唯一的任务分组机制比较受限:Borg没有内置的方法,将多个作业组成单个对象进行管理,只能通过high level的管理工具去解决,在K8s中,使用Label组织调度单元Pod,用户可以通过给运行任务打上Label来进行分组。
- 同一台机器的任务共享一个IP:Borg必须使用端口作为访问入口,而K8s使用Linux namespace和SDN,使得每个任务都能拥有自己的IP地址。
- 为了进行性能优化,使得API复杂化
4. 总结
Kubernetes 继承了 Borg 的核心思想,如基于声明式配置的任务管理、容器化的应用部署、Pod 的调度与健康检查机制,以及对高可用性和资源利用率的追求。同时,Kubernetes 在开放性与可扩展性上进一步发展,将 Borg 的内部理念开源化、标准化,使之成为云原生基础设施的核心。可以说,Kubernetes 是 Borg 在云时代的演进与重生。