1. Intro
Bigtable: A Distributed Storage System for Structured Data是Google发布于ODDI 2006的一篇论文,介绍了当时Google内部大规模使用的结构化分布式存储系统BigTable的设计与实现。BigTable 被广泛应用于 Google 内部多个核心产品中,如 Google Analytics、Google Earth等产品。
与传统RDB产品相比,BigTable参考了很多实现方案,但它不支持完整的关系数据模型,而是通过一个稀疏的多维映射结构,在性能、可扩展性和容错性之间取得了良好平衡。设计中的BigTable支持扩展到PB级数据量和上千数据节点,实现了高性能、高可用性等设计目标。BigTable 构建于 Google 自身的基础设施之上,使用GFS完成数据存储,使用 Chubby 锁完成分布式协调。本文将围绕论文中数据模型、架构设计、容错机制等方面进行分析。
2. 数据模型设计
A Bigtable is a sparse, distributed, persistent multidimensional sorted map.
BigTable是一个稀疏、分布式、持久化存储的多维Map结构,主要体现在:
- Sparse:于关系模型约束严格的RDB相比,BigTable每一行数据的Column组成可能不同,行与行之间可以是不同的列。
- Distributed:Map会被切分成多个分区,在多个机器上分布存储。
- Persistent:Map中所有记录都会被持久化存储。
数据结构特点:
- 数据通过row key、column key和一个timestamp进行索引
- 表中每个数据项都是字节数组
- 映射关系为:$(row:string, column:string, time:int64) → string$

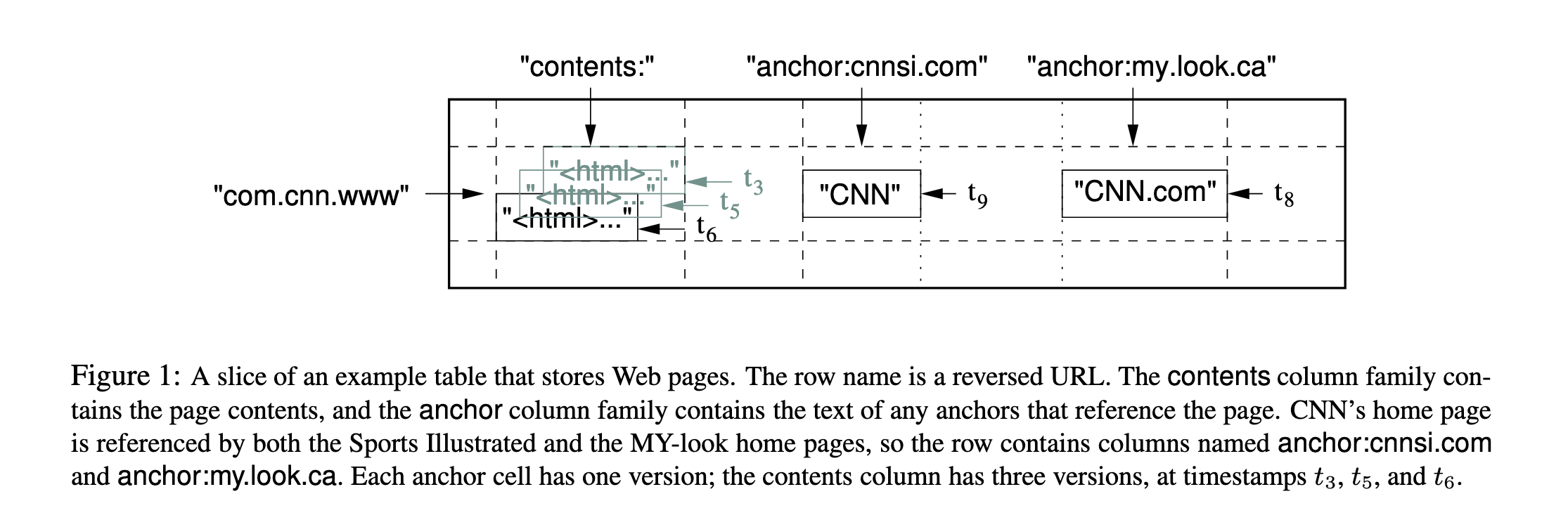
以下图为例:
- row key:逆序URL,方便按照主机名排序,加速查询
contents:列:存储HTML页面信息,存在三个版本,对应时间戳为t3、t5、t6anchor::这是一个column family(列族)
BigTable不支持完整的关系型数据模型:
- 提供客户端的是一个简单数据模型
- 支持动态控制数据格式,允许client推测数据在底层存储中的locality特性
- 数据使用行名和列名进行索引
2.1. Row
Row是BigTable的基本数据单位,可以类比RDB中的Row,每个Row通过唯一的Row Key来标识,实际上按照Row Key字典序进行存储,BigTable动态分区规则也是根据Row Key进行切分,每个分区被称为Tablet,这是基本物理存储单元。
Row key可以是任意字符串(最大支持64KB),Client对于单行数据的读写操作都是原子的,以保障数据一致性。
Tablet是BigTable水平扩展的基本单位,随着单个Tablet数据量的增长,Worker节点会进行自动拆分,以便于在多个节点上分布存储,并且不同Tablet会由不同的Worker节点管理,Client发起请求时会将请求负载均衡到各个节点上,从而实现高并发读写。
2.2. Column Family
Column Family 是一组具有相同前缀的列(Column Qualifiers)的集合,是 BigTable 数据的逻辑和物理组织单位。每个Family在创建表时就需要确定,具体的Column Qualifiers可以后续动态添加,同一个Column Family中的数据在物理上存储在一起,每个都可以独立配置存储参数(数据压缩方式、TTL等),对单个Family的读写性能很高效,因此在Schema, Column Family Schama格式符合该规则:family:qualifier
2.3. TimeStamp
Timestamp与上面两个字段作为索引三元组,用于标识同一个列中多个版本数据的机制,是支持多版本存储(multi-versioned storage)的核心特性之一。时间戳本质上是一个 64 bit 的整数,允许Client指定,也允许BigTable写入时自动分配,同一个数据的不同版本按照timestamp降序存储,这样每次读取的第一个都是最新版本。
为了控制历史版本数量,BigTable同样提供两个参数来进行自动垃圾回收:
- 保留最后的N个版本
- 保留最近时间内的版本
3. 外部组件依赖
3.1. GFS - 分布式文件存储系统
在 Bigtable 中,GFS(Google File System)主要被用作底层的持久化存储系统。Bigtable 本身并不直接管理磁盘文件,而是把数据文件(如 SSTable、WAL 等)存储在 GFS 上,以实现高可靠性和可扩展性。
Bigtable将其核心文件存储在 GFS 上,包括:
- SSTable 文件:用于存储table数据
- WAL(Write-Ahead Log):用于记录尚未刷入内存表的数据变更日志,以实现崩溃恢复;
- 元数据文件:记录 Tablet 的状态信息等。
3.2. Chubby - 分布式锁服务
Chubby是Google发布的一个分布式协调组件,与Apache Zookeeper应用场景和能力都较为类似。Chubby服务提供了一个包含目录和小文件的namespace,每个目录或文件都可以视为一个lock,读写文件都是原子性的,BigTable使用Chubby实现以下需求:
- 保证任何时间最多只有一个active master
- 存储BigTable数据的bootstrap location
- tablet服务发现与服务终止的清理任务
- 存储BigTable schema信息(包括每个table的Column Family)
- ACL列表
4. 设计与实现
4.1. 架构简介
BigTable采用与GFS类似的单Master多Worker架构,各个角色职责如下:
- Master Server:Master仅负责Client端的metadata读取和Worker集群管理等工作。而Client的读写请求直接请求到Worker节点
- 将Tablet分配给Tablet Server
- 检查Tablet Server中的过期事件
- 平衡各个Tablet Server的负载
- Tablet Server集群GC
- 处理Schema变动(创建Table或新增Column Family)
- Tablet Server集群
- 每个Tablet Server管理一组Tablets
- Tablet Server负责这些Tablet的读写请求,如果Tablet太大,需要对其进行切分并存储
- 根据系统负载情况,动态向集群添加或删除Tablet Server节点
Master节点会管理所有Tablet Server和Tablet的分配关系,每个Tablet只会分配给一个Tablet Server,Tablet Server会在特定的Chubby目录下创建并获取一个Lock,Master通过监听这个目录来发现Tablet Server,如果Master发现Lock消失,说明Tablet Server宕机,需要重新将其所属的Tablet分配给其他节点。新的Tablet Server会从原Server的Commit Log中读取这个Tablet的修改日志进行数据恢复。
Client会预先缓存Tablet的metadata,以减少多次请求Master的网络开销,如果本地缓存缺失或错误,它会请求Master获取最新数据。
4.2. Metadata存储
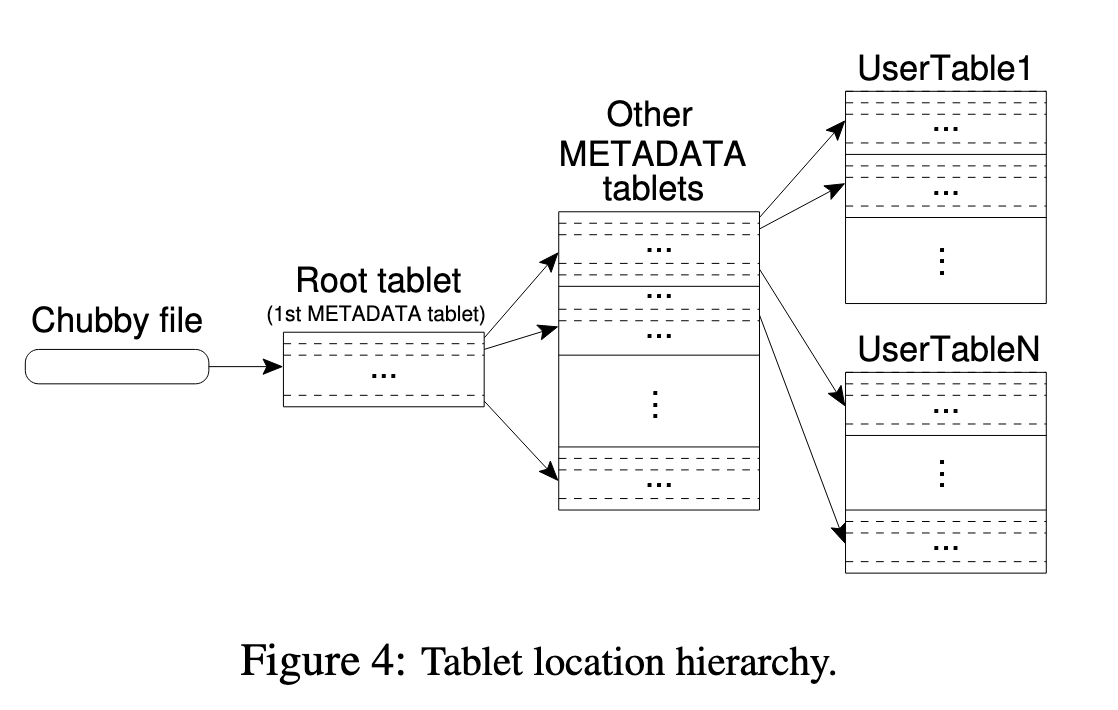
BigTable的Metadata使用类似B+ Tree的三级结构来存储,分别为:
- Chubby File:Chubby中文件存储了Root Tablet的位置
- Metadata Tablet:Root Tablet保存了Metadata Tablet中其他所有Tablet的位置,Metadata Tablet中存储了一组User Tablet的位置
- User Tablet:实际业务数据
Metadata是一个特殊的Tablet,第一个Root Tablet较为特殊,它永远不会分裂,因此图中单独画出。
4.3. 数据存储设计
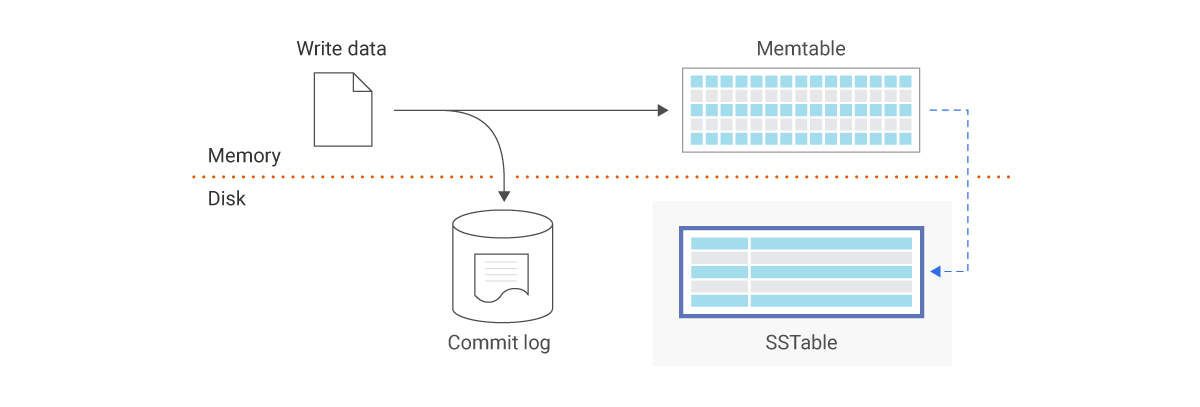
论文中提到,SSTable是当时Google内部使用的磁盘存储格式,SSTable 被用作底层数据存储结构,搭配 MemTable(内存表)、GFS 和 Bloom Filter 实现高效的写入和读取操作。
这里以写入操作为例,探讨一下写入流程:
- 写入操作全部追加到Commit Log(WAL),WAL文件存储在GFS,即使系统崩溃也能从Log恢复数据
- 将数据写入到内存中的MemTable
- MemTable大小超过阈值后,会被异步写入到SSTable,并存储到GFS
查询操作时会使用Bloom Filter来快速判断某个key是否在某个SSTable,如果不在则节省一次磁盘I/O开销。
随着数据量的增多,SSTable数量也会增加,BigTable会定期执行 compaction ,将多个 SSTable 文件合并成一个新的SSTable,删除重复数据、过期版本,合并排序,减小 Bloom Filter 误判率。
SSTable 是一个持久化的、有序的、不可变的map,每个都包含一批blocks,block使用block index作为offset,查找时首先在内存中通过二分查找确定block index,因此一次查询只需要一次磁盘I/O。
4.4. Locality Groups
Locality Groups 是 Bigtable 提供的一种细粒度的数据布局优化手段,通过将列族组合进行物理隔离存储,来优化查询性能和磁盘利用效率。BigTable允许用户将多个Column Family组织到一个Locality Group,每个组的数据会被单独存储为独立的 SSTable,针对于Locality Group维度可以对某些参数进行调优:
- 每个 Locality Group 的数据 单独编码与压缩
- 写入时数据会写入该组对应的 MemTable 和最终 SSTable
- 读取时只需读取包含目标列的组,减少 I/O
- 也能让不同组使用不同的缓存策略(例如 Block Cache)
4.5. Compression
BigTable中针对于磁盘存储中的SSTable Block维度进行了压缩存储,主要目标是减少磁盘存储空间和网络带宽占用,每个Block都会被单独压缩,针对不同的数据特性可以选取最合适的压缩算法,从而达到最大的压缩比,例如论文中提到的案例:相同域名的页面非常适合 Bentley-McIlroy 算法 。
5. 总结
Bigtable 奠定了现代 NoSQL的重要基础。设计思想直接影响了后来的开源系统,如 Apache HBase、Cassandra和Hypertable等,成为大数据时代的重要技术基石。
文中结尾也提到一些系统设计的经验之谈:
- 大规模分布式系统中存在很多方面的故障,在开发期间都需要覆盖。包括不限于:内存和网络损坏、很大的时钟偏差(clock skew)、机器死机(hung)、更复杂的和非对称的网络分裂、依赖的基础服务的 bug(例如 Chubby)、GFS 配额溢出(overflow)等各类问题。
- 所有引入的新特性,都要能解决问题,不要为了设计而设计
- 提供完善的监控告警服务
- 保持简单设计