1. Introduction
传统的关系数据库架构在云环境中遇到了根本性的性能瓶颈:
- 网络I/O成为约束:在云基础设施中,计算、内存、存储都已经可以弹性扩展,但数据库实例与存储之间的网络带宽成为了性能瓶颈
- RDS MySQL镜像方案:简单地将单机MySQL搬到云上,将本地磁盘替换为EBS,但写放大问题被直接映射到网络上,导致性能急剧下降
- 分布式复制协议:如Raft、Paxos等通用协议,开销大,对数据库语义理解不足
- 写放大问题:传统MySQL架构一次逻辑写操作涉及5次物理磁盘写:
- Redo log写入
- Binlog写入
- 数据Page写入(可能触发)
- Double-write buffer写入
- FRM文件写入
针对上述问题,Aurora论文中提出了一个架构理念:
“Log is the Database”
将数据库视为redo log流,存储层变成"日志处理服务",网络上只传输redo log,其他所有工作(Page写入、检查点等)都下推到存储层异步完成。
2. 架构设计
2.1. 设计亮点:The Log is the Database
传统MySQL镜像架构的存在五倍的写放大的情况,Aurora针对此情况做了如下改进:
- 只通过网络传输redo log,其他所有写入都在存储层本地完成
- 存储节点接收并持久化redo log,并异步将日志转换成数据Page,同时维护checkpoint和snapshot,并通过gossip协议检查并修复数据不一致的情况
数据流:
DB Engine → Redo Log → Storage Service → Async Page Generation
(网络传输) (分布式存储) (后台异步)
2.2. 架构概览
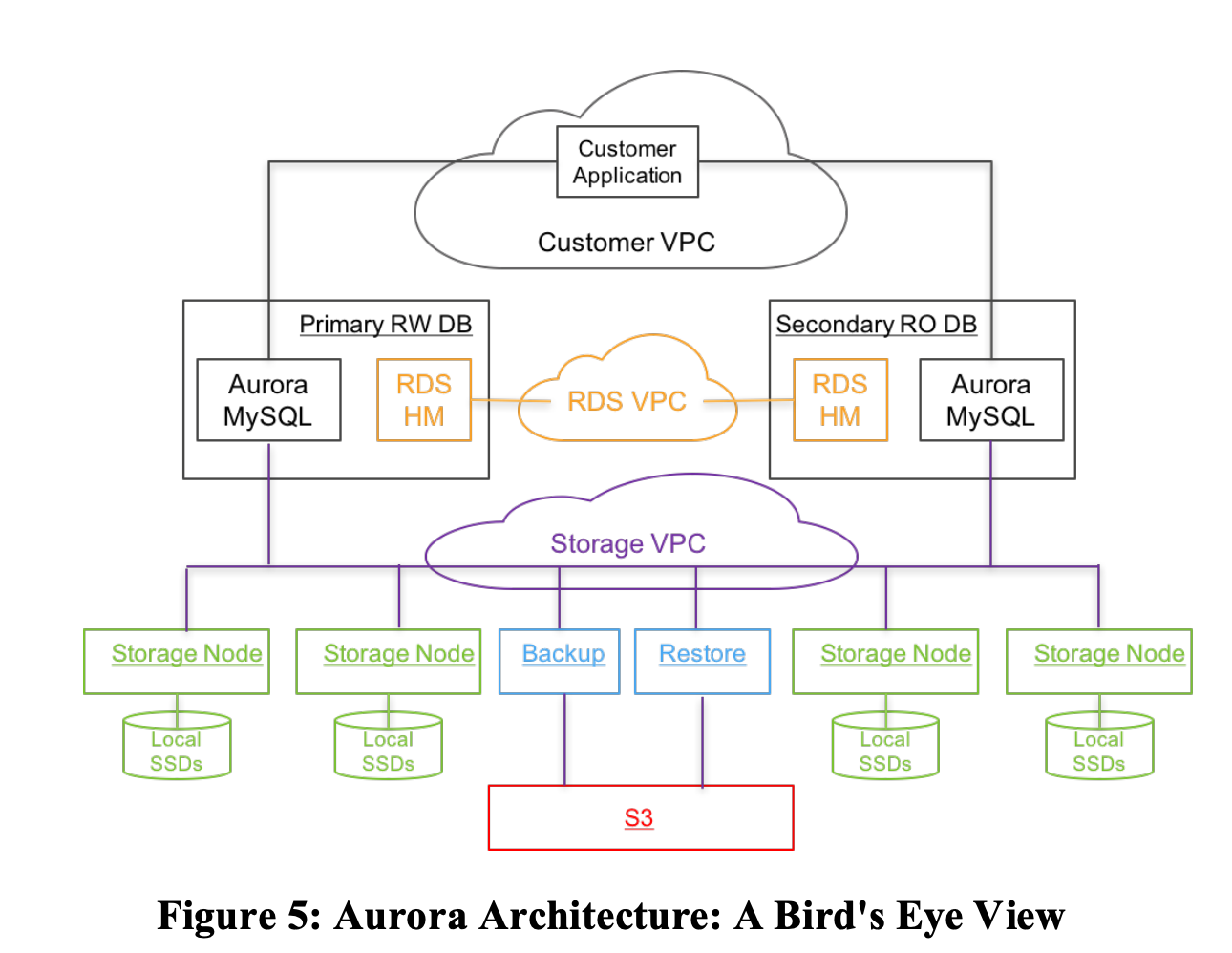
2.2.1. Primary Node
Primary写入节点核心职责:
- 唯一写入节点:接受所有客户端的写请求(INSERT/UPDATE/DELETE)
- 日志生成器:生成MySQL兼容的redo log,分配单调递增的LSN
- 日志分发器:将redo log同时发送到两个目的地:
- 存储层的6个Storage Node:用于持久化和Page生成
- 所有Secondary Node:用于实时同步
- 事务协调器:管理事务提交,等待VDL推进后确认事务完成
- 查询处理器:处理所有SQL查询(包括读和写)
特点:
- 只有1个,单写入者模型
- 不负责Page持久化(交给存储层)
- 通过只传日志实现极低的网络开销
2.2.2. Secondary Node
Secondary只读节点核心职责:
-
读请求负载均衡:分担主节点的读压力
-
日志接收与应用:接收主节点发送的redo log流
-
维护本地缓存:在自己的内存中维护Page缓存,通过日志应用保持最新
-
按需获取Page:当缓存未命中时,从存储层获取最新Page
优势:
- 延迟仅~20毫秒(传统MySQL主从:12+分钟)
- 无额外存储成本(共享同一存储卷)
- 可以独立扩展(最多15个)
2.2.3. Storage Layer
存储层由6个Storage Node组成,跨3个可用区(AZ)部署,每AZ 2个节点。
每个Storage Node承担以下职责:
- 日志持久化:
- 接收来自Primary的redo log
- 将日志记录持久化到本地磁盘
- 向Primary报告已接收的最高LSN(VCL)
- 参与Quorum投票(写需4票,读需3票)
- 异步Page生成(Apply)
- 异步将redo log应用为数据Page
- 维护检查点(Checkpoint)和一致性点(CPL)
- 生成快照(Snapshot)用于备份
- 将Page持久化到本地存储
- 副本同步(Gossip)
- 通过Gossip协议与其他5个节点交换日志状态
- 填补日志空洞(Log Holes):如果发现自己缺少某些日志,向其他节点请求,如果其他节点缺少日志,主动发送,保证所有6个副本最终一致
- 容灾与修复
- 当某个节点故障时,其他节点可快速修复其数据,10GB Segment约10秒即可修复(10Gbps网络)
2.3. 可用性设计
2.3.1. Quorum投票模型
Aurora采用6副本跨3个可用区(AZ)的部署策略:
- 副本分布:每个AZ 2份副本
- 写仲裁(Vw):4票
- 读仲裁(Vr):3票
- 满足条件:Vw + Vr > V(6),确保读写交集至少1个副本
2.3.2. 容错能力
该设计能够容忍:
- 最坏情况1:整个AZ故障 + 额外1个节点故障,仍不丢数据(满足读仲裁)
- 最坏情况2:整个AZ故障,系统仍可继续写入(满足写仲裁)
2.3.3. 存储分段与快速修复
- Segment大小:将存储卷切分为10GB的Segment
- Protection Group (PG):6个副本组成一个保护组
- 修复速度:10GB数据在10Gbps网络下约10秒即可修复
- 可靠性计算:双重故障导致数据丢失的平均时间(MTTF)远超人类文明时长
2.4. Log设计概览
2.4.1. Log字段设计
每条日志记录都会携带单调递增的LSN,用于标识日志顺序。并使用Volume Complete LSN (VCL)保证此前所有日志记录在存储层可用的最高LSN,存储节点会使用该字段向计算层报告最新持久化位置。
存储节点使用Consistency Point LSN (CPL)作为一致性检查点,Volume Durable LSN (VDL)是最新的CPL,作为崩溃恢复时的截断点,也是系统"最新已持久化状态"的标识。崩溃恢复流程如下:
- 从最近的CPL(即VDL)开始
- 重放该点之后的redo log
- 恢复到崩溃前的最新一致状态
2.4.2. 写限流与背压机制
LSN分配限制:
- LSN分配不允许超过VDL 1000万以上
- 当日志生成速度超过存储层应用速度时,自动形成背压
- 防止日志无限堆积,保证系统稳定性
3. 总结
Amazon Aurora的成功源于一个极其优雅的架构:在云环境中,网络才是真正的瓶颈,因此应该将跨网络传输的内容压缩到极致。这一洞见催生了"Log is the Database"理念,配合4/6 Quorum容错模型和10GB存储分段的精巧工程设计,实现了数量级的性能提升。Aurora的技术启示在于:利用数据库的redo log语义而非通用复制协议,实现了更高效的分布式一致性;通过计算与存储分离的分层设计,各层专注核心职责;将Page生成等"脏活"下推到存储层异步处理,保持计算层的高响应;采用日志流和gossip协议实现渐进式最终一致性,而非强一致性。这一架构开创了云原生数据库的设计范式,验证了计算存储分离成为现代数据库的主流模式,推动了数据库服务化——存储从简单块设备演变为智能日志处理服务。然而,Aurora也面临单写入者限制(无法水平扩展写入)、深度依赖AWS基础设施、主要面向OLTP场景以及网络带宽假设等挑战。