前言
clients模块是Kafka官方提供的默认Java客户端,该模块分为三部分:
- Admin:提供了管理topic、partition、config的相关API
- Consumer:提供了消费topic的API
- Producer:提供了向topic投递消息的功能
Kafka源码以3.9为例。
Producer
Producer作为Kafka client中的消息生产者,提供send()方法用于写入消息,并有后台sender线程定时发送消息。
send流程
核心send方法提供了以下两种异步方式:
/**
* See {@link KafkaProducer#send(ProducerRecord)}
*/Future<RecordMetadata> send(ProducerRecord<K, V> record);
/** 支持回调方法
* See {@link KafkaProducer#send(ProducerRecord, Callback)}
*/Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
interceptor机制
send流程中首先会检查用户是否自定义interceptor实现,用于处理send前置逻辑,具体业务场景不多赘述。
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// 拦截器前置send动作
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
其中ProducerInterceptor提供了以下接口:
- ProducerRecord<K, V> onSend(ProducerRecord<K, V> record):send前置处理逻辑
- onAcknowledgement(RecordMetadata metadata, Exception exception):消息被应答之后或发送消息失败时调用。
- close():用于关闭interceptor资源。
自定义interceptor需要考虑线程安全。
doSend流程
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
// 1.1 创建callback对象
AppendCallbacks appendCallbacks = new AppendCallbacks(callback, this.interceptors, record);
try {
//1.2 检查producer是否被close
throwIfProducerClosed();
// first make sure the metadata for the topic is available
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
//1.3 拉取指定topic、分区的元数据,和等待时间
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
//1.4 key value进行序列化
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 1.5 计算当前消息所属的partition
int partition = partition(record, serializedKey, serializedValue, cluster);
// 1.6 设置消息header为readOnly
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
//1.7 检查消息大小是否符合
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compression.type(), serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
// 自定义partitioner
boolean abortOnNewBatch = partitioner != null;
// 1.8 将消息追加到accumulator中
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
assert appendCallbacks.getPartition() != RecordMetadata.UNKNOWN_PARTITION;
// 1.9 消息入新batch的情况
if (result.abortForNewBatch) {
int prevPartition = partition;
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
// 2.1 开启事务的情况
if (transactionManager != null) {
transactionManager.maybeAddPartition(appendCallbacks.topicPartition());
}
// 2.2 如果batch满了,或者新batch被创建,唤醒后台sender线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future, // for other exceptions throw directly } catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null) {
TopicPartition tp = appendCallbacks.topicPartition();
RecordMetadata nullMetadata = new RecordMetadata(tp, -1, -1, RecordBatch.NO_TIMESTAMP, -1, -1);
callback.onCompletion(nullMetadata, e);
}
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
if (transactionManager != null) {
transactionManager.maybeTransitionToErrorState(e);
}
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
}
}
partition机制
Producer中计算消息partition的流程较为简单:
- 若record指定partition,则直接返回。
- 若自定义了partitioner则使用自定义规则的分区计算方式
- 若指定了key并未配置
partitioner.ignore.keys,则使用murmur2算法得出partition - 否则将partition设置为UNKNOWN_PARTITION,这会在org.apache.kafka.clients.producer.internals.RecordAccumulator#append方法中进行处理。
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
if (record.partition() != null)
return record.partition();
if (partitioner != null) {
int customPartition = partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
if (customPartition < 0) {
throw new IllegalArgumentException(String.format(
"The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition));
}
return customPartition;
}
if (serializedKey != null && !partitionerIgnoreKeys) {
// hash the keyBytes to choose a partition
return BuiltInPartitioner.partitionForKey(serializedKey, cluster.partitionsForTopic(record.topic()).size());
} else {
return RecordMetadata.UNKNOWN_PARTITION;
}
}
Partitioner提供了以下三个接口:
- int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster):自定义分区计算方法。
- void close():用于partitioner关闭资源的方法。
- void onNewBatch(String topic, Cluster cluster, int prevPartition):从3.3.0开始废弃,用于通知partitioner新分区被创建,sticky分区方式可以改变新分区的黏性分区。
需要注意的是, KIP-794中指出,sticky分区方式会将消息发送给更慢的broker,慢broker因此收到更多的消息,逐渐变得更慢,因此在该提案中,做了如下更新:
- partitioner默认配置设置为null,并且DefaultPartitioner和UniformStickyPartitioner都被废弃
- 添加新配置用于分区计算
其他具体细节见提案。
RecordAccumulator写入流程
RecordAccumulator是Producer用于存储batch的cache,当达到一定阈值后,会由sender线程将消息发送到Kafka broker。
首先看下核心append方法的逻辑:
/**
* Add a record to the accumulator, return the append result * <p>
* The append result will contain the future metadata, and flag for whether the appended batch is full or a new batch is created
* <p>
*
* @param topic The topic to which this record is being sent
* @param partition The partition to which this record is being sent or RecordMetadata.UNKNOWN_PARTITION
* if any partition could be used * @param timestamp The timestamp of the record
* @param key The key for the record
* @param value The value for the record
* @param headers the Headers for the record
* @param callbacks The callbacks to execute
* @param maxTimeToBlock The maximum time in milliseconds to block for buffer memory to be available
* @param abortOnNewBatch A boolean that indicates returning before a new batch is created and
* running the partitioner's onNewBatch method before trying to append again * @param nowMs The current time, in milliseconds
* @param cluster The cluster metadata
*/public RecordAppendResult append(String topic,
int partition,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
AppendCallbacks callbacks,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs,
Cluster cluster) throws InterruptedException {
// 1.1 获取对应的topicInfo
TopicInfo topicInfo = topicInfoMap.computeIfAbsent(topic, k -> new TopicInfo(createBuiltInPartitioner(logContext, k, batchSize)));
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches(). appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 2. while循环处理并发竟态情况
while (true) {
// 2.1 partition取值兜底
final BuiltInPartitioner.StickyPartitionInfo partitionInfo;
final int effectivePartition;
if (partition == RecordMetadata.UNKNOWN_PARTITION) {
//2.1.1 若未指定分区,使用粘性分区(默认0)
partitionInfo = topicInfo.builtInPartitioner.peekCurrentPartitionInfo(cluster);
effectivePartition = partitionInfo.partition();
} else {
partitionInfo = null;
effectivePartition = partition;
}
// 2.2 更新callback中的partition
setPartition(callbacks, effectivePartition);
// 2.3 获取当前分区的deque
Deque<ProducerBatch> dq = topicInfo.batches.computeIfAbsent(effectivePartition, k -> new ArrayDeque<>());
synchronized (dq) {
// 2.4 check partition是否发生变化
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue;
// 2.5 调用tryAppend进行写入
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callbacks, dq, nowMs);
// 2.5.1 写入后result不为空,更新分区信息,细节见updatePartitionInfo
if (appendResult != null) {
// If queue has incomplete batches we disable switch (see comments in updatePartitionInfo).
boolean enableSwitch = allBatchesFull(dq);
topicInfo.builtInPartitioner.updatePartitionInfo(partitionInfo, appendResult.appendedBytes, cluster, enableSwitch);
return appendResult;
}
}
// 2.6 传入abortOnNewBatch为true,直接返回空batch,再次执行append进行写入
if (abortOnNewBatch) {
// Return a result that will cause another call to append.
return new RecordAppendResult(null, false, false, true, 0);
}
//2.8 buffer为空 分配空间并更新timestamp
if (buffer == null) {
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression.type(), key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, topic, effectivePartition, maxTimeToBlock);
// This call may block if we exhausted buffer space.
buffer = free.allocate(size, maxTimeToBlock);
// Update the current time in case the buffer allocation blocked above.
// NOTE: getting time may be expensive, so calling it under a lock // should be avoided. nowMs = time.milliseconds();
}
//3. 如果上轮deque为空,且abortOnNewBatch=false,则尝试重新将消息写入新batch
synchronized (dq) {
// After taking the lock, validate that the partition hasn't changed and retry.
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue;
//3.1 将新batch加到deque,将消息加到新batch
RecordAppendResult appendResult = appendNewBatch(topic, effectivePartition, dq, timestamp, key, value, headers, callbacks, buffer, nowMs);
// Set buffer to null, so that deallocate doesn't return it back to free pool, since it's used in the batch.
if (appendResult.newBatchCreated)
buffer = null;
// If queue has incomplete batches we disable switch (see comments in updatePartitionInfo).
boolean enableSwitch = allBatchesFull(dq);
topicInfo.builtInPartitioner.updatePartitionInfo(partitionInfo, appendResult.appendedBytes, cluster, enableSwitch);
return appendResult;
}
}
} finally {
//4. 释放buffer,并且减少appendsInProgress
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}
从中可以看出RecordAccumulator的一个核心属性:
//topicInfoMap是由topic到TopicInfo属性的映射
private final ConcurrentMap<String /*topic*/, TopicInfo> topicInfoMap = new CopyOnWriteMap<>();
内置类TopicInfo:
private static class TopicInfo {
//分区到deque的映射,deque由ProducerBatch构成
public final ConcurrentMap<Integer /*partition*/, Deque<ProducerBatch>> batches = new CopyOnWriteMap<>();
//内置partitioner,KIP-794更新
public final BuiltInPartitioner builtInPartitioner;
public TopicInfo(BuiltInPartitioner builtInPartitioner) {
this.builtInPartitioner = builtInPartitioner;
}
}
上述结构来看,写入的分区由ProducerBatch队列构成,ProducerBatch写入的核心方法tryAppend()使用MemoryRecordsBuilder执行写入,并处理压缩、格式转换等。
/**
* Try to append to a ProducerBatch. * * If it is full, we return null and a new batch is created. We also close the batch for record appends to free up * resources like compression buffers. The batch will be fully closed (ie. the record batch headers will be written * and memory records built) in one of the following cases (whichever comes first): right before send, * if it is expired, or when the producer is closed. */private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers,
Callback callback, Deque<ProducerBatch> deque, long nowMs) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
//1. 获取deque最后一个batch
ProducerBatch last = deque.peekLast();
if (last != null) {
//2. 获取当前batch的size
int initialBytes = last.estimatedSizeInBytes();
//3. 尝试将消息加到batch
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, nowMs);
//4. 如果batch已满,关闭batch,返回null
if (future == null) {
last.closeForRecordAppends();
} else {
//5. 计算写入的消息大小,并返回RecordAppendResult
int appendedBytes = last.estimatedSizeInBytes() - initialBytes;
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false, false, appendedBytes);
}
}
//deque 为空,return null
return null;
}
/**
* Append the record to the current record set and return the relative offset within that record set * * @return The RecordSend corresponding to this record or null if there isn't sufficient room.
*/public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
//1.1 检查MemoryRecordsBuilder是否还有足够空间用于写入
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
//1.1.1 没有空间写入直接return null
return null;
} else {
//1.2 调用append()方法写入消息,更新对应字段并return future
this.recordsBuilder.append(timestamp, key, value, headers);
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),
recordsBuilder.compression().type(), key, value, headers));
this.lastAppendTime = now;
//1.3 创建返回值
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp,
key == null ? -1 : key.length,
value == null ? -1 : value.length,
Time.SYSTEM);
// we have to keep every future returned to the users in case the batch needs to be
// split to several new batches and resent. thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
MemoryRecordsBuilder执行写入会检查消息格式,并区分不同版本的消息写入方式。
private void appendWithOffset(long offset, boolean isControlRecord, long timestamp, ByteBuffer key,
ByteBuffer value, Header[] headers) {
try {
//1. 检查isControl标志是否一致
if (isControlRecord != isControlBatch)
throw new IllegalArgumentException("Control records can only be appended to control batches");
// 2. 检查offset递增
if (lastOffset != null && offset <= lastOffset)
throw new IllegalArgumentException(String.format("Illegal offset %d following previous offset %d " +
"(Offsets must increase monotonically).", offset, lastOffset));
//3. 检查时间戳
if (timestamp < 0 && timestamp != RecordBatch.NO_TIMESTAMP)
throw new IllegalArgumentException("Invalid negative timestamp " + timestamp);
//4. 只有V2版本消息,才有header
if (magic < RecordBatch.MAGIC_VALUE_V2 && headers != null && headers.length > 0)
throw new IllegalArgumentException("Magic v" + magic + " does not support record headers");
if (baseTimestamp == null)
baseTimestamp = timestamp;
//5. 写入
if (magic > RecordBatch.MAGIC_VALUE_V1) {
appendDefaultRecord(offset, timestamp, key, value, headers);
} else {
appendLegacyRecord(offset, timestamp, key, value, magic);
}
} catch (IOException e) {
throw new KafkaException("I/O exception when writing to the append stream, closing", e);
}
}
appendDefaultRecord()方法负责写入消息到stream流中,并更新元信息。
private void appendDefaultRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value,
Header[] headers) throws IOException {
//1. 检查appendStream状态
ensureOpenForRecordAppend();
//2. 计算各个变量值
int offsetDelta = (int) (offset - baseOffset);
long timestampDelta = timestamp - baseTimestamp;
//3. 调用DefaultRecord类的writeTo方法,将消息写入appendStream流
int sizeInBytes = DefaultRecord.writeTo(appendStream, offsetDelta, timestampDelta, key, value, headers);
//更新元信息
recordWritten(offset, timestamp, sizeInBytes);
}
Sender线程
sender在KafkaProducer构造方法中初始化:
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
Sender是一个Runnable对象,核心逻辑如下:
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
runOnce()通过sendProducerData()执行实际的发送逻辑,最后通过poll()方法处理网络IO请求
void runOnce() {
……
//省略事务处理
//创建发送给broker的请求并发送
long currentTimeMs = time.milliseconds();
long pollTimeout = sendProducerData(currentTimeMs);
//处理实际网络IO socket的入口,负责发送请求、接收响应
client.poll(pollTimeout, currentTimeMs);
}
sendProducerData流程
该方法主干逻辑如下:
- 调用RecordAccumulator的ready()方法获取可以发送的Node消息
- 调用RecordAccumulator的drain(),获取nodeId -> 待发送的ProducerBatch集合映射
- 调用sendProduceRequests()按Node分组发送请求
其中guaranteeMessageOrder取决于max.in.flight.requests.per.connection配置是否等于1
private long sendProducerData(long now) {
MetadataSnapshot metadataSnapshot = metadata.fetchMetadataSnapshot();
// 1.1 查询accumulator的ready()方法,获取当前已经满足发送要求的node(只需要有一个batch满足发送要求)
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(metadataSnapshot, now);
// 1.2 如果metadata中有topic的partition leader未知,先更新metadata
if (!result.unknownLeaderTopics.isEmpty()) {
// The set of topics with unknown leader contains topics with leader election pending as well as
// topics which may have expired. Add the topic again to metadata to ensure it is included // and request metadata update, since there are messages to send to the topic. for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
result.unknownLeaderTopics);
this.metadata.requestUpdate(false);
}
// 1.3 删除暂未connection ready的node
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
//1.4 更新readyTimeMs
if (!this.client.ready(node, now)) {
// Update just the readyTimeMs of the latency stats, so that it moves forward
// every time the batch is ready (then the difference between readyTimeMs and // drainTimeMs would represent how long data is waiting for the node). this.accumulator.updateNodeLatencyStats(node.id(), now, false);
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
} else {
// Update both readyTimeMs and drainTimeMs, this would "reset" the node
// latency. this.accumulator.updateNodeLatencyStats(node.id(), now, true);
}
}
// 2.1 调用drain(),获取nodeId -> 待发送的ProducerBatch集合映射
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(metadataSnapshot, result.readyNodes, this.maxRequestSize, now);
//2.2 调用addToInflightBatches(),将待发送的ProducerBatch集合映射添加到inFlightBatches中,这个集合记录了已经发送但未响应的ProducerBatch
addToInflightBatches(batches);
//2.3 如果guaranteeMessageOrder为true,将batch添加到muted
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
//2.4 重置batch到期时间
accumulator.resetNextBatchExpiryTime();
//2.5 获取过期的batch
List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
expiredBatches.addAll(expiredInflightBatches);
//2.6 循环调用failBatch()方法来处理过期的batch,内部调用ProducerBatch.done()
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
+ ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
failBatch(expiredBatch, new TimeoutException(errorMessage), false);
if (transactionManager != null && expiredBatch.inRetry()) {
// This ensures that no new batches are drained until the current in flight batches are fully resolved.
transactionManager.markSequenceUnresolved(expiredBatch);
}
}
//2.7 更新metric
sensors.updateProduceRequestMetrics(batches);
//2.8 计算pollTimeout
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
pollTimeout = Math.max(pollTimeout, 0);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
// if some partitions are already ready to be sent, the select time would be 0;
// otherwise if some partition already has some data accumulated but not ready yet, // the select time will be the time difference between now and its linger expiry time; // otherwise the select time will be the time difference between now and the metadata expiry time; pollTimeout = 0;
}
//2.9 调用sendProduceRequests()按Node分组发送请求
sendProduceRequests(batches, now);
return pollTimeout;
}
ready流程
从batchReady()方法中可以看出,是否被确定为ready node,只需要满足以下几个条件中的任何一条:
- full:full = dequeSize > 1 || batch.isFull()
- expired:当前等待时间是否大于lingerMs,其中有重试backoff参数的影响
- exhausted:buffer pool是否已满
- closed:accumulator是否被关闭
- flushInProgress():是否有其他线程在调用flush(),见:org.apache.kafka.clients.producer.KafkaProducer#flush
- transactionCompleting:若开启事务,且事务正准备完成
/**
* Add the leader to the ready nodes if the batch is ready * * @param exhausted 'true' is the buffer pool is exhausted
* @param part The partition
* @param leader The leader for the partition
* @param waitedTimeMs How long batch waited
* @param backingOff Is backing off
* @param backoffAttempts Number of attempts for calculating backoff delay
* @param full Is batch full
* @param nextReadyCheckDelayMs The delay for next check
* @param readyNodes The set of ready nodes (to be filled in)
* @return The delay for next check
*/private long batchReady(boolean exhausted, TopicPartition part, Node leader,
long waitedTimeMs, boolean backingOff, int backoffAttempts,
boolean full, long nextReadyCheckDelayMs, Set<Node> readyNodes) {
if (!readyNodes.contains(leader) && !isMuted(part)) {
long timeToWaitMs = backingOff ? retryBackoff.backoff(backoffAttempts > 0 ? backoffAttempts - 1 : 0) : lingerMs;
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean transactionCompleting = transactionManager != null && transactionManager.isCompleting();
boolean sendable = full
|| expired
|| exhausted
|| closed
|| flushInProgress()
|| transactionCompleting;
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
// Note that this results in a conservative estimate since an un-sendable partition may have
// a leader that will later be found to have sendable data. However, this is good enough // since we'll just wake up and then sleep again for the remaining time. nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
return nextReadyCheckDelayMs;
}
sendProduceRequests
sendProduceRequests()会基于每个node去请求。
/**
* Transfer the record batches into a list of produce requests on a per-node basis */private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) {
for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeoutMs, entry.getValue());
}
Consumer
Consumer作为Kafka Clients中的消费者,继承关系如下图所示:
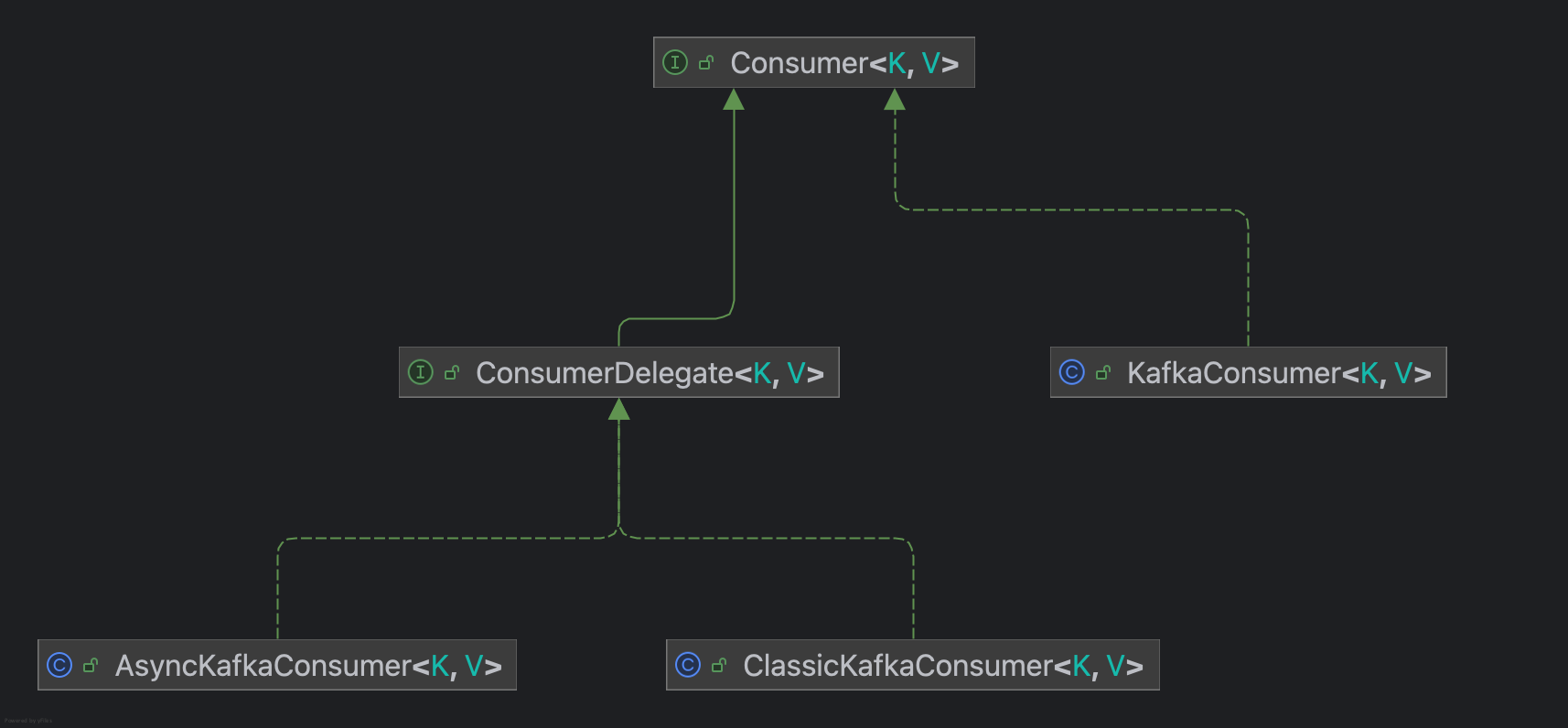
KafkaConsumer作为Facade类,提供API给clients使用,而ConsumerDelegate作为实现类接口,提供了两种实现方式,通过配置group.protocol进行控制,其中ClassicKafkaConsumer所有的线程都会处理网络IO请求,AsyncKafkaConsumer则是基于Reactor模式,使用单独线程处理网络IO,以事件驱动模式处理任务,具体细节见 Consumer threading refactor design。
KafkaConsumer内置的成员变量如下:
//用于创建delegate的工厂类
private static final ConsumerDelegateCreator CREATOR = new ConsumerDelegateCreator();
//consumer具体的实现类
private final ConsumerDelegate<K, V> delegate;
初始化方法:
KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
delegate = CREATOR.create(config, keyDeserializer, valueDeserializer);
}
public <K, V> ConsumerDelegate<K, V> create(ConsumerConfig config,
Deserializer<K> keyDeserializer,
Deserializer<V> valueDeserializer) {
try {
//根据配置选取对应的实现类
GroupProtocol groupProtocol = GroupProtocol.valueOf(config.getString(ConsumerConfig.GROUP_PROTOCOL_CONFIG).toUpperCase(Locale.ROOT));
if (groupProtocol == GroupProtocol.CONSUMER)
return new AsyncKafkaConsumer<>(config, keyDeserializer, valueDeserializer);
else
return new ClassicKafkaConsumer<>(config, keyDeserializer, valueDeserializer);
} catch (KafkaException e) {
throw e;
} catch (Throwable t) {
throw new KafkaException("Failed to construct Kafka consumer", t);
}
}
事件处理逻辑
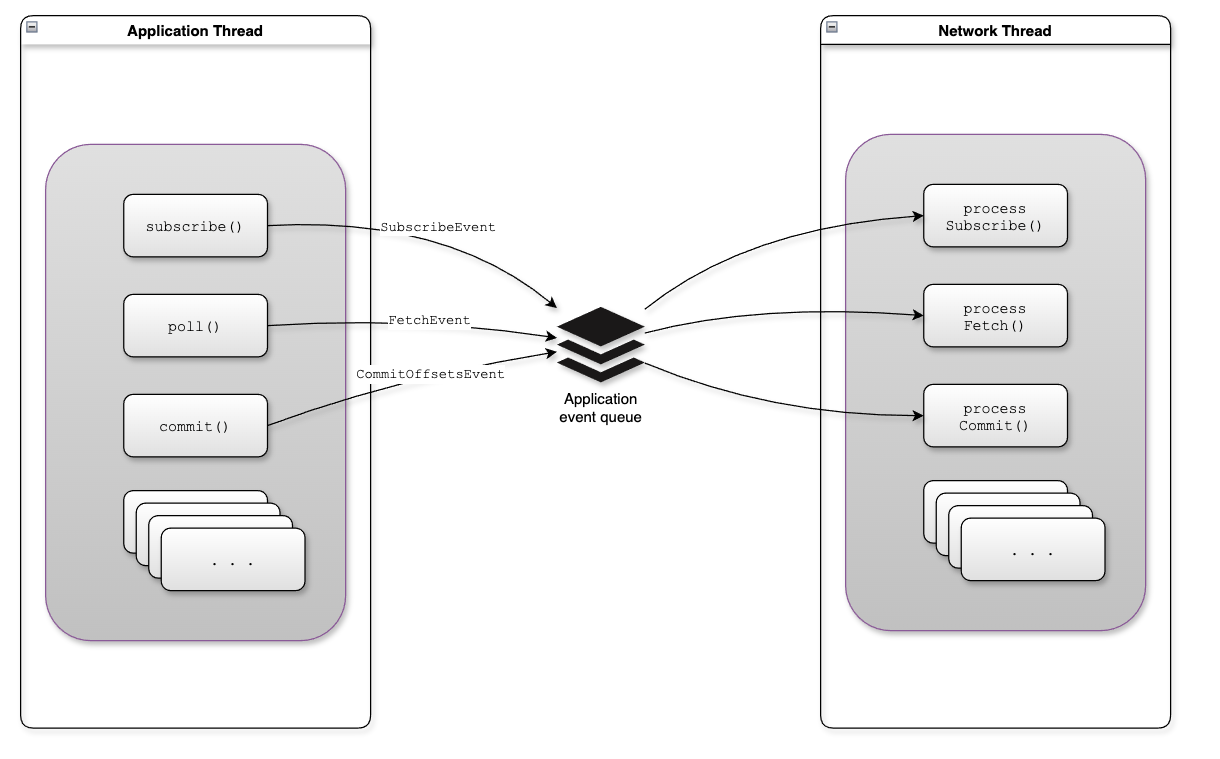
AsyncKafkaConsumer的核心使用事件驱动模式来处理各类事件,具体事件类型见org.apache.kafka.clients.consumer.internals.events.ApplicationEvent
ApplicationEventHandler
ApplicationEventHandler用于接收来自consumer端的各类事件,属性和构造方法如下:
// 用于接收application event的BlockingQueue
private final BlockingQueue<ApplicationEvent> applicationEventQueue;
//网络IO线程
private final ConsumerNetworkThread networkThread;
public ApplicationEventHandler(final LogContext logContext,
final Time time,
final BlockingQueue<ApplicationEvent> applicationEventQueue,
final CompletableEventReaper applicationEventReaper,
final Supplier<ApplicationEventProcessor> applicationEventProcessorSupplier,
final Supplier<NetworkClientDelegate> networkClientDelegateSupplier,
final Supplier<RequestManagers> requestManagersSupplier) {
this.log = logContext.logger(ApplicationEventHandler.class);
this.applicationEventQueue = applicationEventQueue;
this.networkThread = new ConsumerNetworkThread(logContext,
time,
applicationEventQueue,
applicationEventReaper,
applicationEventProcessorSupplier,
networkClientDelegateSupplier,
requestManagersSupplier);
this.networkThread.start();
}
核心方法add()用于向event queue追加事件,并唤醒网络IO线程。
public void add(final ApplicationEvent event) {
Objects.requireNonNull(event, "ApplicationEvent provided to add must be non-null");
applicationEventQueue.add(event);
wakeupNetworkThread();
}
ConsumerNetworkThread
ConsumerNetworkThread是用于后台处理event的线程,并负责处理broker的网络IO。
线程的run()方法通过while循环循环调用runOnce()。
public void run() {
try {
log.debug("Consumer network thread started");
// Wait until we're securely in the background network thread to initialize these objects...
initializeResources();
while (running) {
try {
runOnce();
} catch (final Throwable e) {
// Swallow the exception and continue
log.error("Unexpected error caught in consumer network thread", e);
}
}
} finally {
cleanup();
}
}
runOnce()方法主要处理以下几个任务:
- 提取event并使用ApplicationEventProcessor处理application event
- 遍历RequestManager并调用poll()方法
- 调用NetworkClientDelegate. addAll(List)将request添加到unsentRequests队列中
- 调用KafkaClient. poll(long, long)向broker发送请求
void runOnce() {
//1.1 通过ApplicationEventProcessor处理各类event
processApplicationEvents();
final long currentTimeMs = time.milliseconds();
final long pollWaitTimeMs = requestManagers.entries().stream()
.filter(Optional::isPresent)
.map(Optional::get)
//1.2 循环调用RequestManager.poll(long)获取unsentRequests
.map(rm -> rm.poll(currentTimeMs))
//1.3 调用addAll,将unsentRequests添加到NetworkClientDelegate中
.map(networkClientDelegate::addAll)
.reduce(MAX_POLL_TIMEOUT_MS, Math::min);
//1.4 调用poll,发送请求,接收响应
networkClientDelegate.poll(pollWaitTimeMs, currentTimeMs);
cachedMaximumTimeToWait = requestManagers.entries().stream()
.filter(Optional::isPresent)
.map(Optional::get)
.map(rm -> rm.maximumTimeToWait(currentTimeMs))
.reduce(Long.MAX_VALUE, Math::min);
//1.5 清理过期event
reapExpiredApplicationEvents(currentTimeMs);
}
processApplicationEvents()用于通过applicationEventProcessor来处理event。
/**
* Process the events—if any—that were produced by the application thread. */private void processApplicationEvents() {
//1.1 获取queue中所有 event LinkedList<ApplicationEvent> events = new LinkedList<>();
applicationEventQueue.drainTo(events);
//1.2 循环遍历,通过applicationEventProcessor处理event
for (ApplicationEvent event : events) {
try {
if (event instanceof CompletableEvent)
applicationEventReaper.add((CompletableEvent<?>) event);
applicationEventProcessor.process(event);
} catch (Throwable t) {
log.warn("Error processing event {}", t.getMessage(), t);
}
}
}
BackgroundEventProcessor
BackgroundEventProcessor作为AsyncKafkaConsumer成员变量,用于处理network thread产生的background events,从其process()方法中可以看出,该processor主要处理以下事件:
- network thread产生的error event
- 在application thread执行rebalance回调逻辑
public void process(final BackgroundEvent event) {
switch (event.type()) {
case ERROR:
process((ErrorEvent) event);
break;
case CONSUMER_REBALANCE_LISTENER_CALLBACK_NEEDED:
process((ConsumerRebalanceListenerCallbackNeededEvent) event);
break;
default:
throw new IllegalArgumentException("Background event type " + event.type() + " was not expected");
}
}
订阅主题
subscribe方法来订阅主题,若多次调用,以最后一次作为消费的主题。
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
if (listener == null)
throw new IllegalArgumentException("RebalanceListener cannot be null");
subscribeInternal(topics, Optional.of(listener));
}
subscribeInternal()方法用于处理实际的subscribe逻辑。
private void subscribeInternal(Collection<String> topics, Optional<ConsumerRebalanceListener> listener) {
//1.1 获取lock,并且判断是否已经close
acquireAndEnsureOpen();
try {
//1.2 判断group id是否有效
maybeThrowInvalidGroupIdException();
//1.3 校验参数
if (topics == null)
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
//1.4 若为空,则unsubscribe
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
unsubscribe();
} else {
for (String topic : topics) {
if (isBlank(topic))
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
// 1.5 更新buffer中不再指定的partition
final Set<TopicPartition> currentTopicPartitions = new HashSet<>();
for (TopicPartition tp : subscriptions.assignedPartitions()) {
if (topics.contains(tp.topic()))
currentTopicPartitions.add(tp);
}
fetchBuffer.retainAll(currentTopicPartitions);
log.info("Subscribed to topic(s): {}", String.join(", ", topics));
// 1.6 调用SubscriptionState.subscribe 更新订阅topic
if (subscriptions.subscribe(new HashSet<>(topics), listener))
//若请求成功,更新metadata
this.metadataVersionSnapshot = metadata.requestUpdateForNewTopics();
// 1.7 向handler添加event
applicationEventHandler.add(new SubscriptionChangeEvent());
}
} finally {
//1.8 释放lock
release();
}
}
加锁方式采用乐观锁,校验内置threadId是否一致:
private void acquire() {
final Thread thread = Thread.currentThread();
final long threadId = thread.getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access. " +
"currentThread(name: " + thread.getName() + ", id: " + threadId + ")" +
" otherThread(id: " + currentThread.get() + ")"
);
refCount.incrementAndGet();
}
取消订阅
unsubscribe()方法用于取消topic订阅。
public void unsubscribe() {
//1.1 获取锁,并确保当前消费者没有关闭
acquireAndEnsureOpen();
try {
//1.2 删除buffer中所有订阅的topic分区
fetchBuffer.retainAll(Collections.emptySet());
Timer timer = time.timer(Long.MAX_VALUE);
//1.3 向handler发送unsubscribeEvent
UnsubscribeEvent unsubscribeEvent = new UnsubscribeEvent(calculateDeadlineMs(timer));
applicationEventHandler.add(unsubscribeEvent);
log.info("Unsubscribing all topics or patterns and assigned partitions {}",
subscriptions.assignedPartitions());
//1.4 循环处理background event
try {
processBackgroundEvents(unsubscribeEvent.future(), timer);
log.info("Unsubscribed all topics or patterns and assigned partitions");
} catch (TimeoutException e) {
log.error("Failed while waiting for the unsubscribe event to complete");
}
//1.5 重置group的metadata
resetGroupMetadata();
} catch (Exception e) {
log.error("Unsubscribe failed", e);
throw e;
} finally {
//1.6 释放lock
release();
}
}
拉取消息
poll()方法传递timeout,在指定timeout内,从broker消费数据。
public ConsumerRecords<K, V> poll(final Duration timeout) {
Timer timer = time.timer(timeout);
//1.1 获取lock并确保consumer未关闭
acquireAndEnsureOpen();
try {
//1.2 更新consumer监控指标
kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
//1.3 确保已订阅topic
if (subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
//1.4 定时处理poll逻辑
do {
// 1.5 向handler发送PollEvent
applicationEventHandler.add(new PollEvent(timer.currentTimeMs()));
// We must not allow wake-ups between polling for fetches and returning the records.
// If the polled fetches are not empty the consumed position has already been updated in the polling // of the fetches. A wakeup between returned fetches and returning records would lead to never // returning the records in the fetches. Thus, we trigger a possible wake-up before we poll fetches. wakeupTrigger.maybeTriggerWakeup();
//1.6 更新metadata,并唤醒network thread处理poll任务,获取数据
updateAssignmentMetadataIfNeeded(timer);
final Fetch<K, V> fetch = pollForFetches(timer);
if (!fetch.isEmpty()) {
if (fetch.records().isEmpty()) {
log.trace("Returning empty records from `poll()` "
+ "since the consumer's position has advanced for at least one topic partition");
}
//1.6 通过interceptors处理前置消费逻辑,并返回ConsumerRecords
return interceptors.onConsume(new ConsumerRecords<>(fetch.records()));
}
// We will wait for retryBackoffMs
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
//1.7 更新consumer监控指标,释放lock
kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
release();
}
}
collectFetch()方法从buffer中获取消息,其中FetchBuffer用于存储来自broker响应的消息结果CompletedFetch,每个CompletedFetch代表来自一个partition的响应结果。
public Fetch<K, V> collectFetch(final FetchBuffer fetchBuffer) {
final Fetch<K, V> fetch = Fetch.empty();
final Queue<CompletedFetch> pausedCompletedFetches = new ArrayDeque<>();
int recordsRemaining = fetchConfig.maxPollRecords;
try {
while (recordsRemaining > 0) {
//1.1 从fetchBuffer获取CompletedFetch
final CompletedFetch nextInLineFetch = fetchBuffer.nextInLineFetch();
//1.2 若nextInLineFetch()返回null或已被消费,从queue中获取
if (nextInLineFetch == null || nextInLineFetch.isConsumed()) {
final CompletedFetch completedFetch = fetchBuffer.peek();
//1.3 此时为空,说明broker暂无消息响应
if (completedFetch == null)
break;
//1.4 初始化CompletedFetch
if (!completedFetch.isInitialized()) {
try {
fetchBuffer.setNextInLineFetch(initialize(completedFetch));
} catch (Exception e) {
// Remove a completedFetch upon a parse with exception if (1) it contains no completedFetch, and
// (2) there are no fetched completedFetch with actual content preceding this exception. // The first condition ensures that the completedFetches is not stuck with the same completedFetch // in cases such as the TopicAuthorizationException, and the second condition ensures that no // potential data loss due to an exception in a following record.
if (fetch.isEmpty() && FetchResponse.recordsOrFail(completedFetch.partitionData).sizeInBytes() == 0)
fetchBuffer.poll();
throw e;
}
} else {
fetchBuffer.setNextInLineFetch(completedFetch);
}
fetchBuffer.poll();
//1.5 检查当前topic partition是否被暂停消费
} else if (subscriptions.isPaused(nextInLineFetch.partition)) {
// when the partition is paused we add the records back to the completedFetches queue instead of draining
// them so that they can be returned on a subsequent poll if the partition is resumed at that time
log.debug("Skipping fetching records for assigned partition {} because it is paused", nextInLineFetch.partition);
pausedCompletedFetches.add(nextInLineFetch);
fetchBuffer.setNextInLineFetch(null);
} else {
//1.6 从CompletedFetch中获取Fetch
final Fetch<K, V> nextFetch = fetchRecords(nextInLineFetch, recordsRemaining);
recordsRemaining -= nextFetch.numRecords();
fetch.add(nextFetch);
}
}
} catch (KafkaException e) {
if (fetch.isEmpty())
throw e;
} finally {
// add any polled completed fetches for paused partitions back to the completed fetches queue to be
// re-evaluated in the next poll
fetchBuffer.addAll(pausedCompletedFetches);
}
return fetch;
}
rebalance机制
Kafka支持多consumer并行消费多个partition,因此当consumer数量或partition发生变化时,broker端会重新为当前消费Group分配所订阅的partition。
新版rebalance协议细节可见:# KIP-848: The Next Generation of the Consumer Rebalance Protocol
Reference
https://docs.confluent.io/kafka-client/overview.html https://learn.conduktor.io/kafka/kafka-producers-advanced