1. Intro
Kafka属于单Master多Worker结构,Zookeeper主要提供了metadata存储、分布式同步、集群Leader选举等功能。
至于为何当下Kafka抛弃Zookeeper转而选择自建Raft代替,也是一个老生常谈的问题:
- Zookeeper作为单独的分布式系统,加大了Kafka集群的部署、运维成本。
- Zookeeper存在性能瓶颈,无法支撑更大的集群规模,而自建KRaft支持更大数据量级的分区元数据管理。
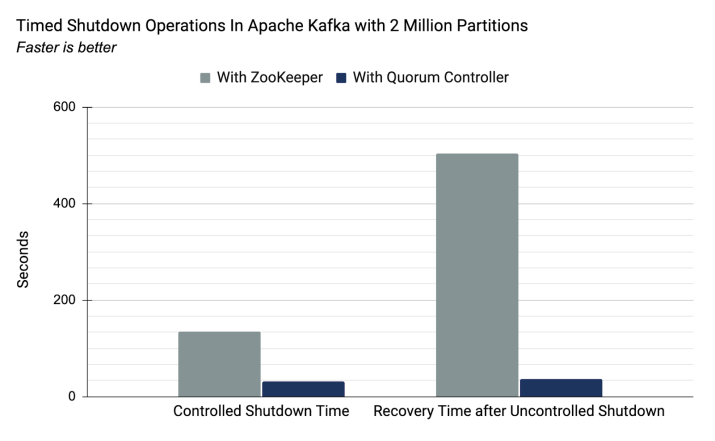
下文会对Kafka提出的KRaft架构做简要分析。
2. Raft算法回顾
Raft算法是一种用于保证分布式集群中数据一致性算法,在Raft论文 中也明确提出:正是因为Paxos算法较为复杂,并且不易于应用到工业界,所以构建了更易于理解的Raft算法来解决分布式系统中的一致性问题。
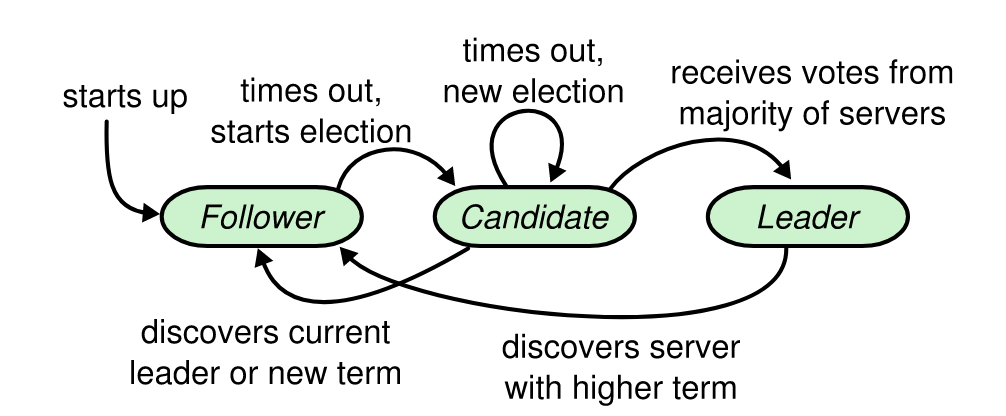
Raft集群中只有三种角色:领导者、候选者、跟随者。Raft算法中每一段任期只有一个领导者节点,每一段任期从一次选举开始,一个或多个候选者参加选举,赢得选举将在接下来的任期充当领导者。跟随者只响应其他服务器的请求。下图为三种状态的转换关系:
3. 架构简析
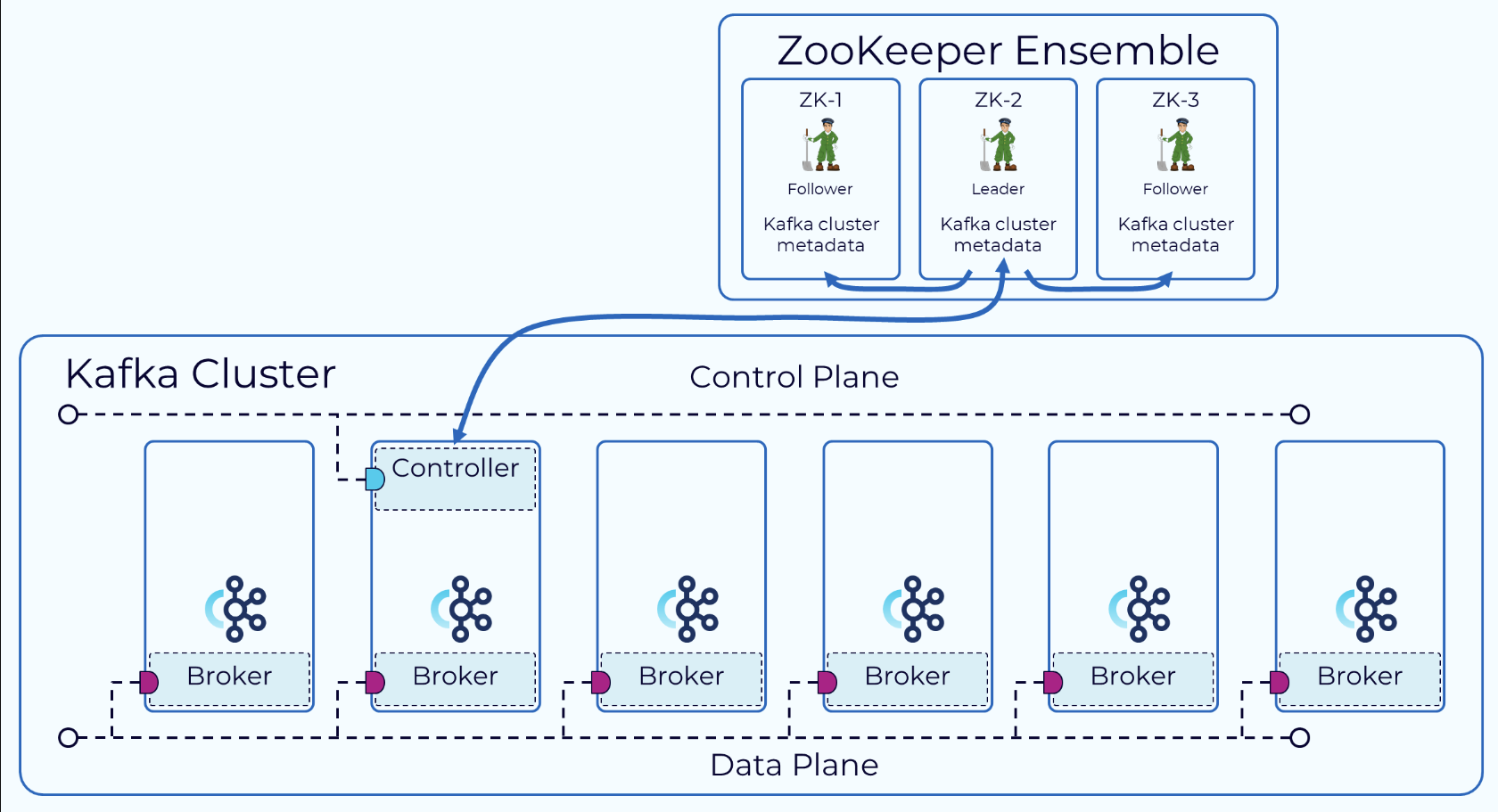
在KRaft架构之前,整个Kafka集群通过Zookeeper来实现元数据存储、选举等目的,通过Zookeeper来选举是通过创建临时节点来实现的,架构实现可以参考下图(confluent):
KRaft模式中,会选取其中部分Broker作为Controller来完成metadata存储和集群管理,但某个时间段只能有一个active Controller,它负责处理整个集群中的RPC请求,其他用作热备的Controller会从active节点同步数据。
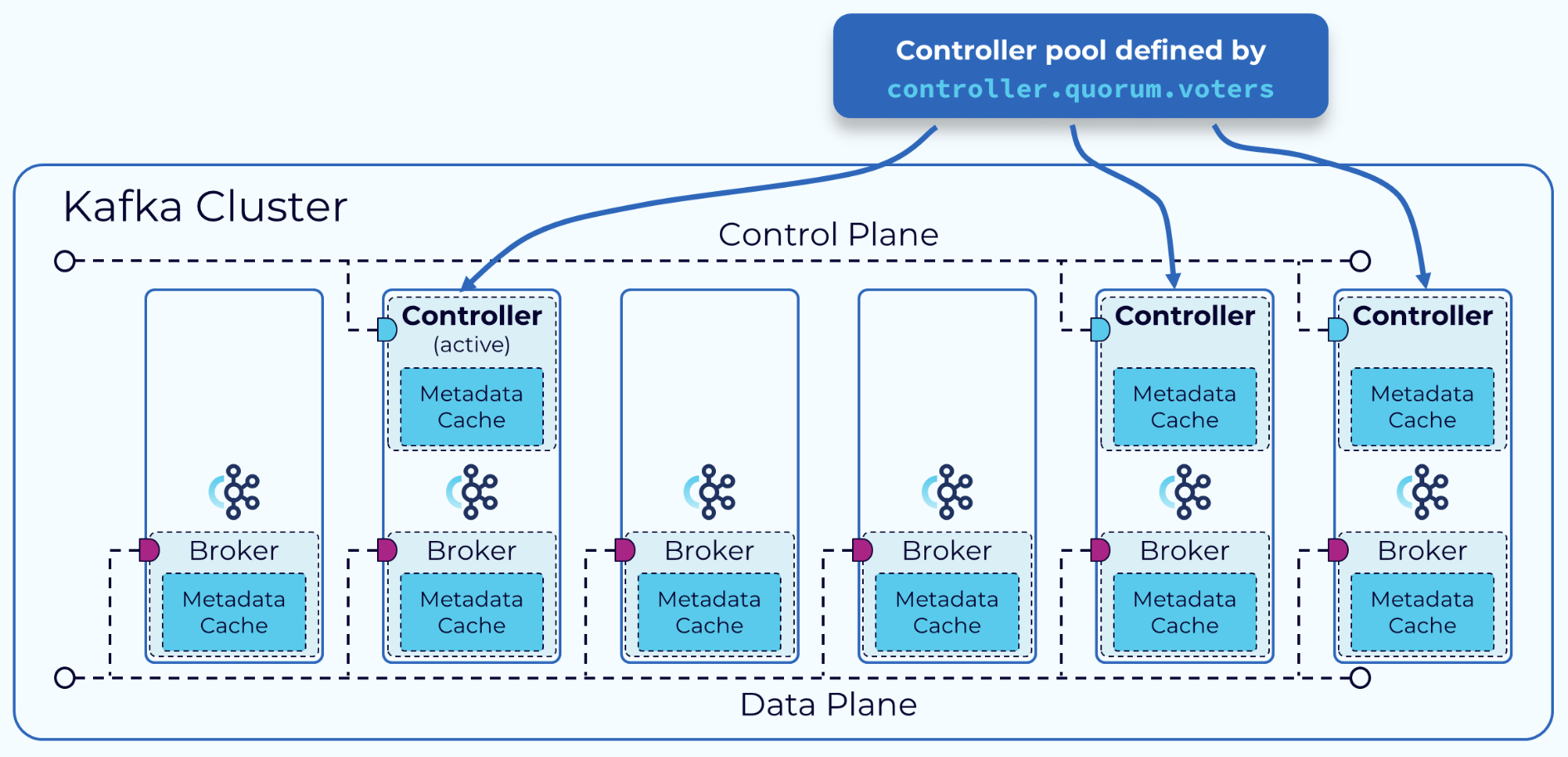
需要注意的是,在日志复制的实现上,KRaft并没有完全采用原生Raft的方式:Leader节点主动往Follower节点推送,而是让Follower主动从Leader执行Fetch。
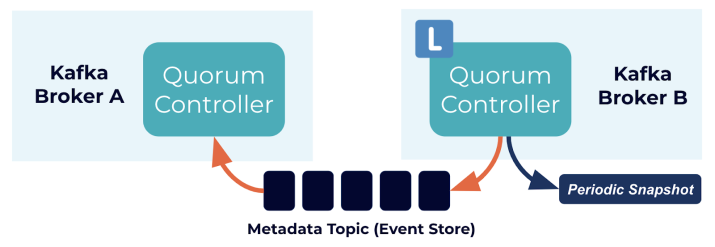
4. KRaft 基本结构
KRaft相关提案:
KRaft概述:KIP-500 KRaft复制/quorum维护协议规范:KIP-595 日志压缩:KIP-630
KRaft具体实现位于org.apache.kafka.raft,snapshot被拆分到org.apache.kafka.snapshot中。
- KafkaRaftManager:KRaft管理与入口类,封装了dir manager、register listener、handleRequest等接口,内部实现通过调用KafkaRaftClient和KafkaRaftClientDriver完成。
- KafkaRaftClientDriver:Thread类,负责运行、管理KafkaRaftClient的生命周期。
- KafkaRaftClient:Kafka Raft协议的具体实现,实现RaftClient接口,选举策略采用原生Raft协议,日志复制是follower主动从leader拉取(符合Kafka语义)。
KRaft提供了Listener接口,提供了commit、snapshot等事件的回调接口。
interface Listener<T> {
void handleCommit(BatchReader<T> reader);
void handleLoadSnapshot(SnapshotReader<T> reader);
default void handleLeaderChange(LeaderAndEpoch leader) {}
default void beginShutdown() {}
}
RaftClient抽取的通用方法如下:
void register(Listener<T> listener);
void unregister(Listener<T> listener);
long prepareAppend(int epoch, List<T> records);
void schedulePreparedAppend();
CompletableFuture<Void> shutdown(int timeoutMs);
void resign(int epoch);
Optional<SnapshotWriter<T>> createSnapshot(OffsetAndEpoch snapshotId, long lastContainedLogTime);
4.1. listener注册逻辑
listener采用lazy-register方式,在消费RaftMessage的前置处理中,将一个时间段内的listener进行注册。
//存储RaftMessage的队列
private final RaftMessageQueue messageQueue;
//listener上下文信息
private final Map<Listener<T>, ListenerContext> listenerContexts = new IdentityHashMap<>();
//待注册的listener信息
private final ConcurrentLinkedQueue<Registration<T>> pendingRegistrations = new ConcurrentLinkedQueue<>();
注册Listener会往pendingRegistrations追加,并唤醒messageQueue执行poll方法完成前置注册逻辑。register和unregister动作通过包装类Registration中的ops字段来区分。
@Override
public void register(Listener<T> listener) {
pendingRegistrations.add(Registration.register(listener));
wakeup();
}
@Override
public void unregister(Listener<T> listener) {
pendingRegistrations.add(Registration.unregister(listener));
// No need to wake up the polling thread. It is a removal so the updates can be
// delayed until the polling thread wakes up for other reasons.}
private void wakeup() {
messageQueue.wakeup();
}
private void pollListeners() {
// Apply all of the pending registration
while (true) {
Registration<T> registration = pendingRegistrations.poll();
if (registration == null) {
break;
}
processRegistration(registration);
}
}
private void processRegistration(Registration<T> registration) {
Listener<T> listener = registration.listener();
Registration.Ops ops = registration.ops();
if (ops == Registration.Ops.REGISTER) {
if (listenerContexts.putIfAbsent(listener, new ListenerContext(listener)) != null) {
logger.error("Attempting to add a listener that already exists: {}", listenerName(listener));
} else {
logger.info("Registered the listener {}", listenerName(listener));
}
} else {
if (listenerContexts.remove(listener) == null) {
logger.error("Attempting to remove a listener that doesn't exists: {}", listenerName(listener));
} else {
logger.info("Unregistered the listener {}", listenerName(listener));
}
}
}
kafka.Kafka.buildServer在创建Server对象时,会根据配置,选择对应Sercer。
private def buildServer(props: Properties): Server = {
val config = KafkaConfig.fromProps(props, doLog = false)
if (config.requiresZookeeper) {
new KafkaServer(
config,
Time.SYSTEM,
threadNamePrefix = None,
enableForwarding = enableApiForwarding(config)
)
} else {
new KafkaRaftServer(
config,
Time.SYSTEM,
)
}
}
4.2. KafkaRaftManager
KafkaRaftManager作为KRaft的入口类,从kafka.server.ControllerApis#handleRaftRequest中可以体现,涉及Raft相关的请求
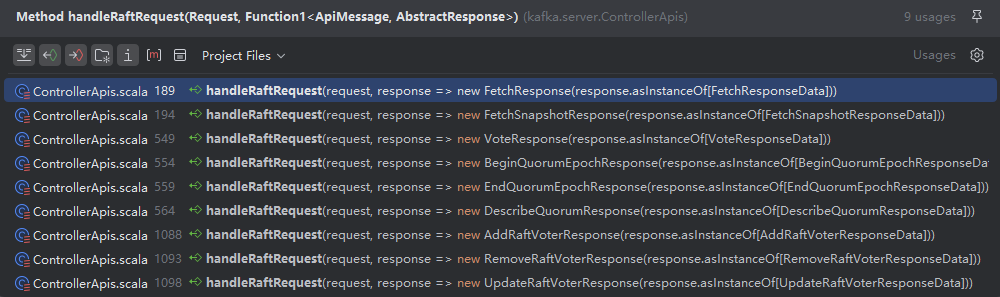
private def handleRaftRequest(request: RequestChannel.Request,
buildResponse: ApiMessage => AbstractResponse): CompletableFuture[Unit] = {
val requestBody = request.body[AbstractRequest]
val future = raftManager.handleRequest(request.context, request.header, requestBody.data, time.milliseconds())
future.handle[Unit] { (responseData, exception) =>
val response = if (exception != null) {
requestBody.getErrorResponse(exception)
} else {
buildResponse(responseData)
}
requestHelper.sendResponseExemptThrottle(request, response)
}
}
在KafkaRaftManager中,也是直接将Request传递给Driver线程:
override def handleRequest(
context: RequestContext,
header: RequestHeader,
request: ApiMessage,
createdTimeMs: Long
): CompletableFuture[ApiMessage] = {
clientDriver.handleRequest(context, header, request, createdTimeMs)
}
其它代理方法:
override def register(
listener: RaftClient.Listener[T]
): Unit = {
client.register(listener)
}
override def leaderAndEpoch: LeaderAndEpoch = {
client.leaderAndEpoch
}
override def voterNode(id: Int, listener: ListenerName): Option[Node] = {
client.voterNode(id, listener).toScala
}
4.3. KafkaRaftClientDriver
KafkaRaftClientDriver作为RaftClient处理线程,与KafkaRaftClient生命周期绑定,继承自ShutdownableThread类,doWrok逻辑中会一直调用client.poll()来处理inbound和outbound请求,有关poll细节在下文再做分析。
private final KafkaRaftClient<T> client;
@Override
public void doWork() {
try {
client.poll();
} catch (Throwable t) {
throw fatalFaultHandler.handleFault("Unexpected error in raft IO thread", t);
}
}
shutdown逻辑中会首先shutdown RaftClient:
@Override
public boolean initiateShutdown() {
if (super.initiateShutdown()) {
client.shutdown(5000).whenComplete((na, exception) -> {
if (exception != null) {
log.error("Graceful shutdown of RaftClient failed", exception);
} else {
log.info("Completed graceful shutdown of RaftClient");
}
});
return true;
} else {
return false;
}
}
@Override
public void shutdown() throws InterruptedException {
try {
super.shutdown();
} finally {
client.close();
}
}
4.4. KafkaRaftClient
KafkaRaftClient是Raft协议在Kafka中的具体实现,包含:leader选举、日志复制、日志snapshot等功能。
核心属性如下:
//节点id
private final OptionalInt nodeId;
//节点目录id
private final Uuid nodeDirectoryId;
//
private final AtomicReference<GracefulShutdown> shutdown = new AtomicReference<>();
private final LogContext logContext;
private final Logger logger;
private final Time time;
//fetch最大等待时间
private final int fetchMaxWaitMs;
private final boolean followersAlwaysFlush;
//集群id
private final String clusterId;
//listener endpoint地址
private final Endpoints localListeners;
private final SupportedVersionRange localSupportedKRaftVersion;
private final NetworkChannel channel;
//本地日志对象
private final ReplicatedLog log;
private final Random random;
//延迟任务
private final FuturePurgatory<Long> appendPurgatory;
private final FuturePurgatory<Long> fetchPurgatory;
//log序列化工具
private final RecordSerde<T> serde;
//内存池
private final MemoryPool memoryPool;
//raft事件消息队列
private final RaftMessageQueue messageQueue;
private final QuorumConfig quorumConfig;
//raft snapshot清理
private final RaftMetadataLogCleanerManager snapshotCleaner;
//listeners
private final Map<Listener<T>, ListenerContext> listenerContexts = new IdentityHashMap<>();
//等待注册的listener队列
private final ConcurrentLinkedQueue<Registration<T>> pendingRegistrations = new ConcurrentLinkedQueue<>();
//kraft状态机
private volatile KRaftControlRecordStateMachine partitionState;
//kraft监控指标
private volatile KafkaRaftMetrics kafkaRaftMetrics;
//Quorum状态
private volatile QuorumState quorum;
//管理与其他controller的通信
private volatile RequestManager requestManager;
// Specialized handlers
private volatile AddVoterHandler addVoterHandler;
private volatile RemoveVoterHandler removeVoterHandler;
private volatile UpdateVoterHandler updateVoterHandler;
通过KafkaRaftClientDriver线程驱动的事件逻辑:
public void poll() {
if (!isInitialized()) {
throw new IllegalStateException("Replica needs to be initialized before polling");
}
long startPollTimeMs = time.milliseconds();
if (maybeCompleteShutdown(startPollTimeMs)) {
return;
}
//1.1 根据不同节点角色,执行对应逻辑
long pollStateTimeoutMs = pollCurrentState(startPollTimeMs);
//1.2 定期清理日志snapshot
long cleaningTimeoutMs = snapshotCleaner.maybeClean(startPollTimeMs);
long pollTimeoutMs = Math.min(pollStateTimeoutMs, cleaningTimeoutMs);
//1.3 更新指标
long startWaitTimeMs = time.milliseconds();
kafkaRaftMetrics.updatePollStart(startWaitTimeMs);
//1.4 获取inbound消息并处理
RaftMessage message = messageQueue.poll(pollTimeoutMs);
long endWaitTimeMs = time.milliseconds();
kafkaRaftMetrics.updatePollEnd(endWaitTimeMs);
if (message != null) {
handleInboundMessage(message, endWaitTimeMs);
}
//1.5 处理新注册的listener
pollListeners();
}
4.5. KafkaRaftServer
KafkaRaftServer是Kraft模式下的Bootstrap启动类,一共有三个较为重要的对象,分别是:
- sharedServer:管理BrokerServer和ControllerServer共享的组件,例如:RaftManager、MetadataLoader等
- broker:broker对象,管理broker相关组件,例如:LogManager、GroupCoordinator等
- controller:controller对象,处理集群管理等事件
后两者通过具体配置process.roles进行选择性加载。
private val sharedServer = new SharedServer(
config,
metaPropsEnsemble,
time,
metrics,
CompletableFuture.completedFuture(QuorumConfig.parseVoterConnections(config.quorumVoters)),
QuorumConfig.parseBootstrapServers(config.quorumBootstrapServers),
new StandardFaultHandlerFactory(),
)
private val broker: Option[BrokerServer] = if (config.processRoles.contains(ProcessRole.BrokerRole)) {
Some(new BrokerServer(sharedServer))
} else {
None
}
private val controller: Option[ControllerServer] = if (config.processRoles.contains(ProcessRole.ControllerRole)) {
Some(new ControllerServer(
sharedServer,
KafkaRaftServer.configSchema,
bootstrapMetadata,
))
} else {
None
}
4.6. ControllerServer
ControllerServer作为KRaft模式下的controller Bootstrap类,内部属性如下:
var socketServer: SocketServer = _
var controller: Controller = _
var controllerApis: ControllerApis = _
var controllerApisHandlerPool: KafkaRequestHandlerPool = _
val metadataPublishers: util.List[MetadataPublisher] = new util.ArrayList[MetadataPublisher]()
其中ControllerApis是所有Controller API的路由,负责调度各类Kafka control请求:
override def handle(request: RequestChannel.Request, requestLocal: RequestLocal): Unit = {
try {
val handlerFuture: CompletableFuture[Unit] = request.header.apiKey match {
case ApiKeys.FETCH => handleFetch(request)
case ApiKeys.FETCH_SNAPSHOT => handleFetchSnapshot(request)
case ApiKeys.CREATE_TOPICS => handleCreateTopics(request)
case ApiKeys.DELETE_TOPICS => handleDeleteTopics(request)
case ApiKeys.API_VERSIONS => handleApiVersionsRequest(request)
}
}
}
4.7. QuorumController
Controller是对集群管理动作的抽象接口:
public interface Controller extends AclMutator, AutoCloseable {
/**
* Change partition information.
* @param context The controller request context.
* @param request The AlterPartitionRequest data.
* @return A future yielding the response.
*/ CompletableFuture<AlterPartitionResponseData> alterPartition(
ControllerRequestContext context,
AlterPartitionRequestData request
);
/**
* Alter the user SCRAM credentials.
* @param context The controller request context.
* @param request The AlterUserScramCredentialsRequest data.
* @return A future yielding the response.
*/ CompletableFuture<AlterUserScramCredentialsResponseData> alterUserScramCredentials(
ControllerRequestContext context,
AlterUserScramCredentialsRequestData request
);
}
当前仅有一个实现类:org.apache.kafka.controller.QuorumController,QuorumController是对Quorum组节点的抽象,Quorum可以参考:# Quorum (分布式系统))
QuorumController划分出多个manager进行功能划分:
/**
* An object which stores the controller's view of the cluster. * This must be accessed only by the event queue thread. */
private final ClusterControlManager clusterControl;
/**
* An object which stores the controller's view of the cluster features. * This must be accessed only by the event queue thread. */
private final FeatureControlManager featureControl;
/**
* An object which stores the controller's view of the latest producer ID * that has been generated. This must be accessed only by the event queue thread. */
private final ProducerIdControlManager producerIdControlManager;
/**
* An object which stores the controller's view of topics and partitions. * This must be accessed only by the event queue thread. */
private final ReplicationControlManager replicationControl;
这里以创建topic为例,来看下在KRaft架构下的处理流程。
@Override
public CompletableFuture<CreateTopicsResponseData> createTopics(
ControllerRequestContext context,
CreateTopicsRequestData request, Set<String> describable
) {
if (request.topics().isEmpty()) {
return CompletableFuture.completedFuture(new CreateTopicsResponseData());
}
return appendWriteEvent("createTopics", context.deadlineNs(),
() -> replicationControl.createTopics(context, request, describable));
}
<T> CompletableFuture<T> appendWriteEvent(
String name,
OptionalLong deadlineNs,
ControllerWriteOperation<T> op,
EnumSet<ControllerOperationFlag> flags
) {
ControllerWriteEvent<T> event = new ControllerWriteEvent<>(name, op, flags);
if (deadlineNs.isPresent()) {
queue.appendWithDeadline(deadlineNs.getAsLong(), event);
} else {
queue.append(event);
}
return event.future();
}
() -> replicationControl.createTopics(context, request, describable)是controller处理topic创建的逻辑,它会被封装成ControllerWriteEvent并写入到队列KafkaEventQueue中。
4.7.1. KafkaEventQueue
KafkaEventQueue是用于处理Controller事件的异步队列,实现自接口EventQueue,该接口封装了append、scheduleDeferred等方法。
public interface EventQueue extends AutoCloseable {
interface Event {
void run() throws Exception;
default void handleException(Throwable e) {}
}
default void append(Event event) {
enqueue(EventInsertionType.APPEND, null, NoDeadlineFunction.INSTANCE, event);
}
void enqueue(EventInsertionType insertionType,
String tag,
Function<OptionalLong, OptionalLong> deadlineNsCalculator,
Event event);
default void scheduleDeferred(String tag,
Function<OptionalLong, OptionalLong> deadlineNsCalculator,
Event event) {
enqueue(EventInsertionType.DEFERRED, tag, deadlineNsCalculator, event);
KafkaEventQueue通过EventHandler完成事件写入、处理。
@Override
public void enqueue(EventInsertionType insertionType,
String tag,
Function<OptionalLong, OptionalLong> deadlineNsCalculator,
Event event) {
EventContext eventContext = new EventContext(event, insertionType, tag);
Exception e = eventHandler.enqueue(eventContext, deadlineNsCalculator);
if (e != null) {
eventContext.completeWithException(log, e);
}
}
KafkaEventQueue内部字段如下,初始化时会启动处理线程。
//事件处理器,封装了事件处理逻辑
private final EventHandler eventHandler;
//实际处理事件的线程
private final Thread eventHandlerThread;
public KafkaEventQueue(
Time time,
LogContext logContext,
String threadNamePrefix,
Event cleanupEvent
) {
this.time = time;
this.cleanupEvent = Objects.requireNonNull(cleanupEvent);
this.lock = new ReentrantLock();
this.log = logContext.logger(KafkaEventQueue.class);
this.eventHandler = new EventHandler();
this.eventHandlerThread = new KafkaThread(threadNamePrefix + EVENT_HANDLER_THREAD_SUFFIX,
this.eventHandler, false);
this.shuttingDown = false;
this.interrupted = false;
this.eventHandlerThread.start();
}
enqueue操作会将事件存储到一个双向链表,提供EventHandler进行处理。
Exception enqueue(EventContext eventContext,
Function<OptionalLong, OptionalLong> deadlineNsCalculator) {
//1.1 上锁,检查是否关闭或中断
lock.lock();
try {
if (shuttingDown) {
return new RejectedExecutionException("The event queue is shutting down");
}
if (interrupted) {
return new InterruptedException("The event handler thread is interrupted");
}
//1.2 检查tag、计算deadline time
OptionalLong existingDeadlineNs = OptionalLong.empty();
if (eventContext.tag != null) {
EventContext toRemove =
tagToEventContext.put(eventContext.tag, eventContext);
if (toRemove != null) {
existingDeadlineNs = toRemove.deadlineNs;
remove(toRemove);
size--;
}
}
OptionalLong deadlineNs = deadlineNsCalculator.apply(existingDeadlineNs);
boolean queueWasEmpty = head.isSingleton();
boolean shouldSignal = false;
//1.3 根据插入类型,选择插入位置
switch (eventContext.insertionType) {
case APPEND:
head.insertBefore(eventContext);
if (queueWasEmpty) {
shouldSignal = true;
}
break;
case PREPEND:
head.insertAfter(eventContext);
if (queueWasEmpty) {
shouldSignal = true;
}
break;
case DEFERRED:
if (!deadlineNs.isPresent()) {
return new RuntimeException(
"You must specify a deadline for deferred events.");
}
break;
}
//1.4 如果事件有deadline time,将其插入deadlineMap中,更新size,唤醒等待线程
if (deadlineNs.isPresent()) {
long insertNs = deadlineNs.getAsLong();
long prevStartNs = deadlineMap.isEmpty() ? Long.MAX_VALUE : deadlineMap.firstKey();
// If the time in nanoseconds is already taken, take the next one.
while (deadlineMap.putIfAbsent(insertNs, eventContext) != null) {
insertNs++;
}
eventContext.deadlineNs = OptionalLong.of(insertNs);
// If the new timeout is before all the existing ones, wake up the
// timeout thread. if (insertNs <= prevStartNs) {
shouldSignal = true;
}
}
size++;
if (shouldSignal) {
cond.signal();
}
} finally {
lock.unlock();
}
return null;
}
EventHandler是一个Runnable实现,负责处理进入KafkaEventQueue的各类事件:
@Override
public void run() {
try {
handleEvents();
} catch (Throwable e) {
log.warn("event handler thread exiting with exception", e);
}
try {
cleanupEvent.run();
} catch (Throwable e) {
log.warn("cleanup event threw exception", e);
}
}
handleEvents方法从双向链表和deadlineMap中不断地取事件处理,事件实际运行的逻辑为:event.run(),也就是执行入队列的元素run方法。
private void handleEvents() {
Throwable toDeliver = null;
EventContext toRun = null;
boolean wasInterrupted = false;
//1.1 循环处理事件
while (true) {
//1.2 如果toRun不为空,则运行事件event.run()
if (toRun != null) {
wasInterrupted = toRun.run(log, toDeliver);
}
//1.3 上锁检查deadlineMap 中是否有超时或延迟事件
lock.lock();
try {
if (toRun != null) {
size--;
if (wasInterrupted) {
interrupted = wasInterrupted;
}
toDeliver = null;
toRun = null;
wasInterrupted = false;
}
long awaitNs = Long.MAX_VALUE;
Map.Entry<Long, EventContext> entry = deadlineMap.firstEntry();
//1.4 如果deadlineMap不为空,则获取第一个事件
if (entry != null) {
// Search for timed-out events or deferred events that are ready
// to run. long now = time.nanoseconds();
long timeoutNs = entry.getKey();
EventContext eventContext = entry.getValue();
//1.5 如果第一个事件超时,赋值toRun,在下一轮循环执行
if (timeoutNs <= now) {
if (eventContext.insertionType == EventInsertionType.DEFERRED) {
// The deferred event is ready to run. Prepend it to the
// queue. (The value for deferred events is a schedule time // rather than a timeout.) remove(eventContext);
toDeliver = null;
toRun = eventContext;
} else {
// not a deferred event, so it is a deadline, and it is timed out.
remove(eventContext);
toDeliver = new TimeoutException();
toRun = eventContext;
}
continue;
} else if (interrupted) {
remove(eventContext);
toDeliver = new InterruptedException("The event handler thread is interrupted");
toRun = eventContext;
continue;
} else if (shuttingDown) {
remove(eventContext);
toDeliver = new RejectedExecutionException("The event queue is shutting down");
toRun = eventContext;
continue;
}
awaitNs = timeoutNs - now;
}
//2.1 如果队列为空,并且shuttingDown或interrupted,则直接退出循环
if (head.next == head) {
if (deadlineMap.isEmpty() && (shuttingDown || interrupted)) {
// If there are no more entries to process, and the queue is
// closing, exit the thread. return;
}
} else {
//2.2 否则获取队列的第一个事件,赋值toRun,在下一轮循环执行
if (interrupted) {
toDeliver = new InterruptedException("The event handler thread is interrupted");
} else {
toDeliver = null;
}
toRun = head.next;
remove(toRun);
continue;
}
//3.1 wait等待新事件
if (awaitNs == Long.MAX_VALUE) {
try {
cond.await();
} catch (InterruptedException e) {
log.warn("Interrupted while waiting for a new event. " +
"Shutting down event queue");
interrupted = true;
}
} else {
try {
cond.awaitNanos(awaitNs);
} catch (InterruptedException e) {
log.warn("Interrupted while waiting for a deferred event. " +
"Shutting down event queue");
interrupted = true;
}
}
} finally {
lock.unlock();
}
}
}
5. Reference
https://docs.confluent.io/platform/current/kafka-metadata/kraft.html https://cwiki.apache.org/confluence/display/KAFKA/KIP-500 https://cwiki.apache.org/confluence/display/KAFKA/KIP-631 https://cwiki.apache.org/confluence/display/KAFKA/KIP-595