1. Intro
上文介绍了KRaft架构的优势与基本组件,本文对Raft协议在Kafka中的实现做简单分析。
2. 核心属性
2.1. QuorumState
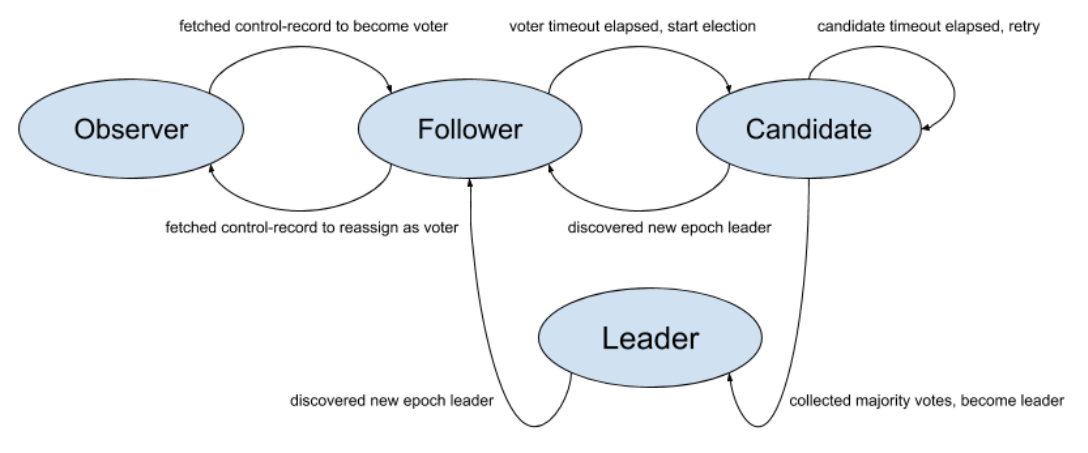
QuorumState用于存储KRaft节点状态,并处理状态转换,状态机图如下(引用自KIP-595):
核心属性:
//节点id
private final OptionalInt localId;
//目录id
private final Uuid localDirectoryId;
private final Time time;
private final Logger log;
//用于选举信息存储,JSON格式
private final QuorumStateStore store;
//kraft状态机
private final KRaftControlRecordStateMachine partitionState;
//各个listener endpoint节点信息
private final Endpoints localListeners;
//kraft版本信息
private final SupportedVersionRange localSupportedKRaftVersion;
private final Random random;
//选举超时时间
private final int electionTimeoutMs;
//fetch超时时间
private final int fetchTimeoutMs;
//日志上下文
private final LogContext logContext;
//节点状态对象
private volatile EpochState state;
其中EpochState接口是对节点状态的抽象,不同节点类型有对应的实现对象:
接口方法:
default Optional<LogOffsetMetadata> highWatermark() {
return Optional.empty();
}
boolean canGrantVote(ReplicaKey candidateKey, boolean isLogUpToDate);
ElectionState election();
int epoch();
Endpoints leaderEndpoints();
String name();
Kafka会将当前Quorum选举状态写入本地文件,当前实现类FileQuorumStateStore写入格式为JSON:
{"clusterId":"","leaderId":1,"leaderEpoch":2,"votedId":-1,"appliedOffset":0,"currentVoters":[{"voterId":1}],"data_version":0}
QuorumState中包含部分状态转换逻辑,这里以转换为Leader状态为例:
public <T> LeaderState<T> transitionToLeader(long epochStartOffset, BatchAccumulator<T> accumulator) {
//1.1 如果是observer或不是candidate,则抛出异常
if (isObserver()) {
throw new IllegalStateException(
String.format(
"Cannot transition to Leader since the local id (%s) and directory id (%s) " +
"is not one of the voters %s",
localId,
localDirectoryId,
partitionState.lastVoterSet()
)
);
} else if (!isCandidate()) {
throw new IllegalStateException("Cannot transition to Leader from current state " + state);
}
//1.2 获取candidateState
CandidateState candidateState = candidateStateOrThrow();
if (!candidateState.isVoteGranted())
throw new IllegalStateException("Cannot become leader without majority votes granted");
//2.1 创建LeaderState对象
LeaderState<T> state = new LeaderState<>(
time,
ReplicaKey.of(localIdOrThrow(), localDirectoryId),
epoch(),
epochStartOffset,
partitionState.lastVoterSet(),
partitionState.lastVoterSetOffset(),
partitionState.lastKraftVersion(),
candidateState.grantingVoters(),
accumulator,
localListeners,
fetchTimeoutMs,
logContext
);
//2.2 更新
durableTransitionTo(state);
return state;
}
durableTransitionTo方法完成文件、内存两处更新:
private void durableTransitionTo(EpochState newState) {
log.info("Attempting durable transition to {} from {}", newState, state);
//写入文件
store.writeElectionState(newState.election(), partitionState.lastKraftVersion());
//更新内存
memoryTransitionTo(newState);
}
private void memoryTransitionTo(EpochState newState) {
if (state != null) {
try {
state.close();
} catch (IOException e) {
throw new UncheckedIOException(
"Failed to transition from " + state.name() + " to " + newState.name(), e);
}
}
EpochState from = state;
state = newState;
log.info("Completed transition to {} from {}", newState, from);
}
2.2. ReplicatedLog
ReplicatedLog是KRaft架构下用于存储metadata信息的接口,它在实现上复用了日志模块的UnifiedLog,与topic数据采取相同的存储格式。
部分较为重要的接口方法如下:
public interface ReplicatedLog extends AutoCloseable {
LogAppendInfo appendAsLeader(Records records, int epoch);
LogAppendInfo appendAsFollower(Records records);
LogFetchInfo read(long startOffsetInclusive, Isolation isolation);
LogOffsetMetadata highWatermark();
void truncateTo(long offset);
void flush(boolean forceFlushActiveSegment);
TopicPartition topicPartition();
Optional<RawSnapshotWriter> createNewSnapshot(OffsetAndEpoch snapshotId);
Optional<RawSnapshotReader> readSnapshot(OffsetAndEpoch snapshotId);
}
当前唯一的实现类为:kafka.raft.KafkaMetadataLog:
final class KafkaMetadataLog private (
val log: UnifiedLog,
time: Time,
scheduler: Scheduler,
snapshots: mutable.TreeMap[OffsetAndEpoch, Option[FileRawSnapshotReader]],
topicPartition: TopicPartition,
config: MetadataLogConfig
) extends ReplicatedLog with Logging {
appendAsLeader方法实现也都是直接调用UnifiedLog的对应方法来实现:
override def appendAsLeader(records: Records, epoch: Int): LogAppendInfo = {
if (records.sizeInBytes == 0)
throw new IllegalArgumentException("Attempt to append an empty record set")
handleAndConvertLogAppendInfo(
log.appendAsLeader(records.asInstanceOf[MemoryRecords],
leaderEpoch = epoch,
origin = AppendOrigin.RAFT_LEADER,
requestLocal = RequestLocal.NoCaching
)
)
}
2.3. RaftMetadataLogCleanerManager
RaftMetadataLogCleanerManager是用于定时调度日志清理的manager:
this.snapshotCleaner = new RaftMetadataLogCleanerManager(logger, time, 60000, log::maybeClean);
实现较为简单:
private static class RaftMetadataLogCleanerManager {
private final Logger logger;
private final Timer timer;
private final long delayMs;
private final Runnable cleaner;
public long maybeClean(long currentTimeMs) {
timer.update(currentTimeMs);
if (timer.isExpired()) {
try {
cleaner.run();
} catch (Throwable t) {
logger.error("Had an error during log cleaning", t);
}
timer.reset(delayMs);
}
return timer.remainingMs();
}
}
2.4. KRaftControlRecordStateMachine
KRaftControlRecordStateMachine保存了kraft.version和voters信息:
private final VoterSetHistory voterSetHistory;
private final LogHistory<KRaftVersion> kraftVersionHistory = new TreeMapLogHistory<>();
3. pollCurrentState
由KafkaRaftClientDriver线程驱动的poll方法中调用的pollCurrentState方法会根据节点角色执行不同逻辑:
private long pollCurrentState(long currentTimeMs) {
//1.1 根据节点角色进行调用
if (quorum.isLeader()) {
return pollLeader(currentTimeMs);
} else if (quorum.isCandidate()) {
return pollCandidate(currentTimeMs);
} else if (quorum.isFollower()) {
return pollFollower(currentTimeMs);
} else if (quorum.isUnattached()) {
return pollUnattached(currentTimeMs);
} else if (quorum.isResigned()) {
return pollResigned(currentTimeMs);
} else {
throw new IllegalStateException("Unexpected quorum state " + quorum);
}
}
3.1. pollLeader
leader节点定期执行逻辑如下:
- 检查listener是否需要触发leader change事件
- 检查是否需要进入resigned状态
- 定期落盘accumulator中的日志数据
- 检查是否需要发送BeginQuorumEpoch请求
private long pollLeader(long currentTimeMs) {
//1.1 检查listener,触发leader change事件
LeaderState<T> state = quorum.leaderStateOrThrow();
maybeFireLeaderChange(state);
//1.2 检查是否需要进入resigned状态
long timeUntilCheckQuorumExpires = state.timeUntilCheckQuorumExpires(currentTimeMs);
if (shutdown.get() != null || state.isResignRequested() || timeUntilCheckQuorumExpires == 0) {
transitionToResigned(state.nonLeaderVotersByDescendingFetchOffset());
return 0L;
}
//1.3 计算下一次vote到期时间
long timeUtilVoterChangeExpires = state.maybeExpirePendingOperation(currentTimeMs);
//1.4 定期落盘accumulator中的日志数据
long timeUntilFlush = maybeAppendBatches(
state,
currentTimeMs
);
//1.5 检查是否需要发送BeginQuorumEpoch请求
long timeUntilNextBeginQuorumSend = maybeSendBeginQuorumEpochRequests(
state,
currentTimeMs
);
return Math.min(
timeUntilFlush,
Math.min(
timeUntilNextBeginQuorumSend,
Math.min(
timeUntilCheckQuorumExpires,
timeUtilVoterChangeExpires
)
)
);
}
3.2. pollCandidate
candidate节点会检查是否需要发送vote请求:
private long pollCandidate(long currentTimeMs) {
CandidateState state = quorum.candidateStateOrThrow();
GracefulShutdown shutdown = this.shutdown.get();
//1.1 检查是否需要shutdown
if (shutdown != null) {
//1.2 正在关闭也需要发送Vote请求
long minRequestBackoffMs = maybeSendVoteRequests(state, currentTimeMs);
return Math.min(shutdown.remainingTimeMs(), minRequestBackoffMs);
} else if (state.isBackingOff()) {
//1.3 如果退出选举,继续转换为candidate状态
if (state.isBackoffComplete(currentTimeMs)) {
logger.info("Re-elect as candidate after election backoff has completed");
transitionToCandidate(currentTimeMs);
return 0L;
}
return state.remainingBackoffMs(currentTimeMs);
} else if (state.hasElectionTimeoutExpired(currentTimeMs)) {
//1.4 选举超时
long backoffDurationMs = binaryExponentialElectionBackoffMs(state.retries());
logger.info("Election has timed out, backing off for {}ms before becoming a candidate again",
backoffDurationMs);
state.startBackingOff(currentTimeMs, backoffDurationMs);
return backoffDurationMs;
} else {
//检查是否需要发送vote请求
long minRequestBackoffMs = maybeSendVoteRequests(state, currentTimeMs);
return Math.min(minRequestBackoffMs, state.remainingElectionTimeMs(currentTimeMs));
}
}
3.3. pollFollower
pollFollower方法会检查节点角色为voter还是observer:
private long pollFollower(long currentTimeMs) {
FollowerState state = quorum.followerStateOrThrow();
if (quorum.isVoter()) {
return pollFollowerAsVoter(state, currentTimeMs);
} else {
return pollFollowerAsObserver(state, currentTimeMs);
}
}
作为observer都会发送fetch请求用以更新log信息。
private long pollFollowerAsObserver(FollowerState state, long currentTimeMs) {
//发送fetch请求
if (state.hasFetchTimeoutExpired(currentTimeMs)) {
return maybeSendFetchToAnyBootstrap(currentTimeMs);
} else {
return maybeSendFetchToBestNode(state, currentTimeMs);
}
}
作为voter角色会检查fetch是否超时,若是则转换为candidate状态。
private long pollFollowerAsVoter(FollowerState state, long currentTimeMs) {
GracefulShutdown shutdown = this.shutdown.get();
final long backoffMs;
if (shutdown != null) {
// If we are a follower, then we can shutdown immediately. We want to
// skip the transition to candidate in any case. backoffMs = 0;
} else if (state.hasFetchTimeoutExpired(currentTimeMs)) {
//1.1 如果fetch超时,转为candidate状态
logger.info("Become candidate due to fetch timeout");
transitionToCandidate(currentTimeMs);
backoffMs = 0;
} else if (state.hasUpdateVoterPeriodExpired(currentTimeMs)) {
//1.2 发送UpdateVoter请求
if (partitionState.lastKraftVersion().isReconfigSupported() &&
partitionState.lastVoterSet().voterNodeNeedsUpdate(quorum.localVoterNodeOrThrow())) {
backoffMs = maybeSendUpdateVoterRequest(state, currentTimeMs);
} else {
// 1.3 发送Fetch snapshot请求
backoffMs = maybeSendFetchOrFetchSnapshot(state, currentTimeMs);
}
state.resetUpdateVoterPeriod(currentTimeMs);
} else {
backoffMs = maybeSendFetchToBestNode(state, currentTimeMs);
}
return Math.min(
backoffMs,
Math.min(
state.remainingFetchTimeMs(currentTimeMs),
state.remainingUpdateVoterPeriodMs(currentTimeMs)
)
);
}
4. 日志复制
KRaft与原生Raft算法不同的是,kRaft是由follower节点主动从Leader节点Fetch日志数据,而不是像原生Raft算法那样,主动由Leader向Follower推送日志数据。
有关日志复制和选举的设计文档,可以参考KIP-595
4.1. handleFetchRequest
handleFetchRequest方法由Leader节点处理来自Follower的Fetch请求的逻辑:
- 检查请求参数合法性,offset等字段
- 从指定offset读取日志数据并返回
private CompletableFuture<FetchResponseData> handleFetchRequest(
RaftRequest.Inbound requestMetadata,
long currentTimeMs
) {
FetchRequestData request = (FetchRequestData) requestMetadata.data();
//1.1 检查参数
if (!hasValidClusterId(request.clusterId())) {
return completedFuture(new FetchResponseData().setErrorCode(Errors.INCONSISTENT_CLUSTER_ID.code()));
}
if (!hasValidTopicPartition(request, log.topicPartition(), log.topicId())) {
// Until we support multi-raft, we treat topic partition mismatches as invalid requests
return completedFuture(new FetchResponseData().setErrorCode(Errors.INVALID_REQUEST.code()));
}
// If the ID is valid, we can set the topic name.
request.topics().get(0).setTopic(log.topicPartition().topic());
FetchRequestData.FetchPartition fetchPartition = request.topics().get(0).partitions().get(0);
if (request.maxWaitMs() < 0
|| fetchPartition.fetchOffset() < 0
|| fetchPartition.lastFetchedEpoch() < 0
|| fetchPartition.lastFetchedEpoch() > fetchPartition.currentLeaderEpoch()) {
return completedFuture(
buildEmptyFetchResponse(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
Errors.INVALID_REQUEST,
Optional.empty()
)
);
}
//1.2 构造初始的Fetch响应数据
ReplicaKey replicaKey = ReplicaKey.of(
FetchRequest.replicaId(request),
fetchPartition.replicaDirectoryId()
);
//1.3 处理fetch请求,并返回response
FetchResponseData response = tryCompleteFetchRequest(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
replicaKey,
fetchPartition,
currentTimeMs
);
FetchResponseData.PartitionData partitionResponse =
response.responses().get(0).partitions().get(0);
//1.3 如果满足以下条件,直接返回
if (partitionResponse.errorCode() != Errors.NONE.code()
|| FetchResponse.recordsSize(partitionResponse) > 0
|| request.maxWaitMs() == 0
|| isPartitionDiverged(partitionResponse)
|| isPartitionSnapshotted(partitionResponse)) {
// Reply immediately if any of the following is true
// 1. The response contains an error
// 2. There are records in the response
// 3. The fetching replica doesn't want to wait for the partition to contain new data
// 4. The fetching replica needs to truncate because the log diverged
// 5. The fetching replica needs to fetch a snapshot
return completedFuture(response);
}
CompletableFuture<Long> future = fetchPurgatory.await(
fetchPartition.fetchOffset(),
request.maxWaitMs());
//2.1 等待异步完成,处理response
return future.handle((completionTimeMs, exception) -> {
if (exception != null) {
Throwable cause = exception instanceof ExecutionException ?
exception.getCause() : exception;
Errors error = Errors.forException(cause);
if (error == Errors.REQUEST_TIMED_OUT) {
// Note that for this case the calling thread is the expiration service thread and not the
// polling thread. // // If the fetch request timed out in purgatory, it means no new data is available, // just return the original fetch response.
return response;
} else {
// If there was any error other than REQUEST_TIMED_OUT, return it.
logger.info(
"Failed to handle fetch from {} at {} due to {}",
replicaKey,
fetchPartition.fetchOffset(),
error
);
return buildEmptyFetchResponse(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
error,
Optional.empty()
);
}
}
// FIXME: `completionTimeMs`, which can be null
logger.trace(
"Completing delayed fetch from {} starting at offset {} at {}",
replicaKey,
fetchPartition.fetchOffset(),
completionTimeMs
);
// It is safe to call tryCompleteFetchRequest because only the polling thread completes this
// future successfully. This is true because only the polling thread appends record batches to // the log from maybeAppendBatches. return tryCompleteFetchRequest(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
replicaKey,
fetchPartition,
time.milliseconds()
);
});
}
tryCompleteFetchRequest方法负责从log指定offset读取数据,并封装response返回。
private FetchResponseData tryCompleteFetchRequest(
ListenerName listenerName,
short apiVersion,
ReplicaKey replicaKey,
FetchRequestData.FetchPartition request,
long currentTimeMs
) {
try {
//1.1 验证请求参数
Optional<Errors> errorOpt = validateLeaderOnlyRequest(request.currentLeaderEpoch());
if (errorOpt.isPresent()) {
return buildEmptyFetchResponse(listenerName, apiVersion, errorOpt.get(), Optional.empty());
}
long fetchOffset = request.fetchOffset();
int lastFetchedEpoch = request.lastFetchedEpoch();
LeaderState<T> state = quorum.leaderStateOrThrow();
//1.2 检查offset、snapshotId是否有效
Optional<OffsetAndEpoch> latestSnapshotId = log.latestSnapshotId();
final ValidOffsetAndEpoch validOffsetAndEpoch;
if (fetchOffset == 0 && latestSnapshotId.isPresent() && !latestSnapshotId.get().equals(BOOTSTRAP_SNAPSHOT_ID)) {
// If the follower has an empty log and a non-bootstrap snapshot exists, it is always more efficient
// to reply with a snapshot id (FETCH_SNAPSHOT) instead of fetching from the log segments.
validOffsetAndEpoch = ValidOffsetAndEpoch.snapshot(latestSnapshotId.get());
} else {
validOffsetAndEpoch = log.validateOffsetAndEpoch(fetchOffset, lastFetchedEpoch);
}
//2.1 从fetchOffset读取日志数据
final Records records;
if (validOffsetAndEpoch.kind() == ValidOffsetAndEpoch.Kind.VALID) {
LogFetchInfo info = log.read(fetchOffset, Isolation.UNCOMMITTED);
if (state.updateReplicaState(replicaKey, currentTimeMs, info.startOffsetMetadata)) {
onUpdateLeaderHighWatermark(state, currentTimeMs);
}
records = info.records;
} else {
records = MemoryRecords.EMPTY;
}
return buildFetchResponse(
listenerName,
apiVersion,
Errors.NONE,
records,
validOffsetAndEpoch,
state.highWatermark()
);
} catch (Exception e) {
logger.error("Caught unexpected error in fetch completion of request {}", request, e);
return buildEmptyFetchResponse(listenerName, apiVersion, Errors.UNKNOWN_SERVER_ERROR, Optional.empty());
}
}
4.2. handleFetchResponse
handleFetchResponse方法是Follower从Leader获取到metadata数据后,完成本地写入的流程:
- 检查响应字段合法性
- 检查是否需要truncate操作
- 检查响应是否返回snapshot数据
- 写入日志records记录,并更新high watermark字段
private boolean handleFetchResponse(
RaftResponse.Inbound responseMetadata,
long currentTimeMs
) {
//1.1 检查参数合法性
FetchResponseData response = (FetchResponseData) responseMetadata.data();
Errors topLevelError = Errors.forCode(response.errorCode());
if (topLevelError != Errors.NONE) {
return handleTopLevelError(topLevelError, responseMetadata);
}
if (!hasValidTopicPartition(response, log.topicPartition(), log.topicId())) {
return false;
}
// If the ID is valid, we can set the topic name.
response.responses().get(0).setTopic(log.topicPartition().topic());
FetchResponseData.PartitionData partitionResponse =
response.responses().get(0).partitions().get(0);
//1.2 获取leaderId和epoch
FetchResponseData.LeaderIdAndEpoch currentLeaderIdAndEpoch = partitionResponse.currentLeader();
OptionalInt responseLeaderId = optionalLeaderId(currentLeaderIdAndEpoch.leaderId());
int responseEpoch = currentLeaderIdAndEpoch.leaderEpoch();
Errors error = Errors.forCode(partitionResponse.errorCode());
final Endpoints leaderEndpoints;
//1.3 根据响应中的leaderId,构造endpoint
if (responseLeaderId.isPresent()) {
if (response.nodeEndpoints().isEmpty()) {
leaderEndpoints = partitionState.lastVoterSet().listeners(responseLeaderId.getAsInt());
} else {
leaderEndpoints = Endpoints.fromFetchResponse(
channel.listenerName(),
responseLeaderId.getAsInt(),
response.nodeEndpoints()
);
}
} else {
leaderEndpoints = Endpoints.empty();
}
//2.1 处理response,检查字段
Optional<Boolean> handled = maybeHandleCommonResponse(
error,
responseLeaderId,
responseEpoch,
leaderEndpoints,
responseMetadata.source(),
currentTimeMs
);
if (handled.isPresent()) {
return handled.get();
}
FollowerState state = quorum.followerStateOrThrow();
if (error == Errors.NONE) {
FetchResponseData.EpochEndOffset divergingEpoch = partitionResponse.divergingEpoch();
//2.2 检查是否需要截断
if (divergingEpoch.epoch() >= 0) {
// The leader is asking us to truncate before continuing
final OffsetAndEpoch divergingOffsetAndEpoch = new OffsetAndEpoch(
divergingEpoch.endOffset(), divergingEpoch.epoch());
state.highWatermark().ifPresent(highWatermark -> {
if (divergingOffsetAndEpoch.offset() < highWatermark.offset()) {
throw new KafkaException("The leader requested truncation to offset " +
divergingOffsetAndEpoch.offset() + ", which is below the current high watermark" +
" " + highWatermark);
}
});
long truncationOffset = log.truncateToEndOffset(divergingOffsetAndEpoch);
logger.info(
"Truncated to offset {} from Fetch response from leader {}",
truncationOffset,
quorum.leaderIdOrSentinel()
);
//2.3 截断旧数据
// Update the internal listener to the new end offset
partitionState.truncateNewEntries(truncationOffset);
} else if (partitionResponse.snapshotId().epoch() >= 0 ||
partitionResponse.snapshotId().endOffset() >= 0) {
// The leader is asking us to fetch a snapshot
//2.4 检查是否需要写入snapshot
if (partitionResponse.snapshotId().epoch() < 0) {
logger.error(
"The leader sent a snapshot id with a valid end offset {} but with an invalid epoch {}",
partitionResponse.snapshotId().endOffset(),
partitionResponse.snapshotId().epoch()
);
return false;
} else if (partitionResponse.snapshotId().endOffset() < 0) {
logger.error(
"The leader sent a snapshot id with a valid epoch {} but with an invalid end offset {}",
partitionResponse.snapshotId().epoch(),
partitionResponse.snapshotId().endOffset()
);
return false;
} else {
final OffsetAndEpoch snapshotId = new OffsetAndEpoch(
partitionResponse.snapshotId().endOffset(),
partitionResponse.snapshotId().epoch()
);
// Do not validate the snapshot id against the local replicated log since this
// snapshot is expected to reference offsets and epochs greater than the log // end offset and high-watermark. state.setFetchingSnapshot(log.createNewSnapshotUnchecked(snapshotId));
if (state.fetchingSnapshot().isPresent()) {
logger.info(
"Fetching snapshot {} from Fetch response from leader {}",
snapshotId,
quorum.leaderIdOrSentinel()
);
} else {
logger.info(
"Leader {} returned a snapshot {} in the FETCH response which is " +
"already stored",
quorum.leaderIdOrSentinel(),
snapshotId
);
}
}
} else {
//2.5 写入日志records记录,并更新high watermark
Records records = FetchResponse.recordsOrFail(partitionResponse);
if (records.sizeInBytes() > 0) {
appendAsFollower(records);
}
OptionalLong highWatermark = partitionResponse.highWatermark() < 0 ?
OptionalLong.empty() : OptionalLong.of(partitionResponse.highWatermark());
updateFollowerHighWatermark(state, highWatermark);
}
state.resetFetchTimeout(currentTimeMs);
return true;
} else {
return handleUnexpectedError(error, responseMetadata);
}
}
5. 选举机制
KRaft模式中Controller是通过具体的配置选择,如果配置多个节点作为controller,一段时间内,只会有一个active来处理各类请求,通过配置参数process.roles来区分节点的角色:
private val controller: Option[ControllerServer] = if (config.processRoles.contains(ProcessRole.ControllerRole)) {
Some(new ControllerServer(
sharedServer,
KafkaRaftServer.configSchema,
bootstrapMetadata,
))
} else {
None
}
判断是否为active Controller的依据:判断org.apache.kafka.controller.QuorumController#curClaimEpoch字段是否为-1
private boolean isActiveController() {
return isActiveController(curClaimEpoch);
}
private static boolean isActiveController(int claimEpoch) {
return claimEpoch != -1;
}
作为voter如果满足以下任一条件,则会触发一轮新的选举:
- Fetch时发现当前Leader超时,相关参数:
quorum.fetch.timeout.ms - 从当前Leader接收到
EndQuorumEpoch请求 - 在成为candidate后,在
quorum.election.timeout.ms时间内未能获得大部分投票
5.1. 投票过程
voter触发选举后,会首先给自己投一票,并且将发送VoteRequest给其他voter。voter处理VoteRequest的流程如下:
- 检查clusterId是否与当前相等
- 检查请求中的epoch是否大于当前epoch,若小于则拒绝投票
- 检查是否已经为请求投票的epoch投过票,若已经投过,检查candidate id是否匹配,匹配则投票
- 如果请求中的epoch大于当前节点的epoch:
- 检查candidate id是否为reassign部分
- 检查candidate的log是否比当前voter新
private VoteResponseData handleVoteRequest(
RaftRequest.Inbound requestMetadata
) {
VoteRequestData request = (VoteRequestData) requestMetadata.data();
//1.1 检查request
if (!hasValidClusterId(request.clusterId())) {
return new VoteResponseData().setErrorCode(Errors.INCONSISTENT_CLUSTER_ID.code());
}
if (!hasValidTopicPartition(request, log.topicPartition())) {
// Until we support multi-raft, we treat individual topic partition mismatches as invalid requests
return new VoteResponseData().setErrorCode(Errors.INVALID_REQUEST.code());
}
VoteRequestData.PartitionData partitionRequest =
request.topics().get(0).partitions().get(0);
int candidateId = partitionRequest.candidateId();
int candidateEpoch = partitionRequest.candidateEpoch();
int lastEpoch = partitionRequest.lastOffsetEpoch();
long lastEpochEndOffset = partitionRequest.lastOffset();
//1.2 检查请求是否有效
if (lastEpochEndOffset < 0 || lastEpoch < 0 || lastEpoch >= candidateEpoch) {
return buildVoteResponse(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
Errors.INVALID_REQUEST,
false
);
}
Optional<Errors> errorOpt = validateVoterOnlyRequest(candidateId, candidateEpoch);
if (errorOpt.isPresent()) {
return buildVoteResponse(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
errorOpt.get(),
false
);
}
//1.3 如果vote请求的epoch信息,大于当前节点的epoch信息,则转换为unattach状态
if (candidateEpoch > quorum.epoch()) {
transitionToUnattached(candidateEpoch);
}
//1.3 检查voterkey是否与本地匹配
// Check that the request was intended for this replica
Optional<ReplicaKey> voterKey = RaftUtil.voteRequestVoterKey(request, partitionRequest);
if (!isValidVoterKey(voterKey)) {
logger.info(
"Candidate sent a voter key ({}) in the VOTE request that doesn't match the " +
"local key ({}, {}); rejecting the vote",
voterKey,
nodeId,
nodeDirectoryId
);
// The request is not intended to this replica since the replica keys don't match
return buildVoteResponse(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
Errors.INVALID_VOTER_KEY,
false
);
}
//2.1 构造OffsetAndEpoch
OffsetAndEpoch lastEpochEndOffsetAndEpoch = new OffsetAndEpoch(lastEpochEndOffset, lastEpoch);
ReplicaKey candidateKey = ReplicaKey.of(
candidateId,
partitionRequest.candidateDirectoryId()
);
//2.2 检查是否可以vote:对比log offset
boolean voteGranted = quorum.canGrantVote(
candidateKey,
lastEpochEndOffsetAndEpoch.compareTo(endOffset()) >= 0
);
//2.3 如果可以vote,并且当前节点是unattached状态,则转换为unattached voted状态
if (voteGranted && quorum.isUnattachedNotVoted()) {
transitionToUnattachedVoted(candidateKey, candidateEpoch);
}
//2.4 成功进行投票
logger.info("Vote request {} with epoch {} is {}", request, candidateEpoch, voteGranted ? "granted" : "rejected");
return buildVoteResponse(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
Errors.NONE,
voteGranted
);
}
处理voteResponse的流程如下:
- 检查当前节点是否任然为candidate,若不是则忽略响应。
- 检查节点是否已经获得了大部分选票,如果没有更新的epoch candidate,则成为leader,并更新quorum状态。
- 如果candidate已经获取了大部分选票,它也会将当前的分配状态写入log,更新
LastEpoch和LastEpochOffset,最后发送BeginQuorumEpochRequest。
handleVoteResponse方法的核心逻辑:
if (handled.isPresent()) {
return handled.get();
} else if (error == Errors.NONE) {
//2.1 如果当前节点是leader,直接忽略当前response
if (quorum.isLeader()) {
logger.debug("Ignoring vote response {} since we already became leader for epoch {}",
partitionResponse, quorum.epoch());
//2.1 如果为candidate,记录本次投票,并检查是否可以成为leader
} else if (quorum.isCandidate()) {
CandidateState state = quorum.candidateStateOrThrow();
if (partitionResponse.voteGranted()) {
state.recordGrantedVote(remoteNodeId);
maybeTransitionToLeader(state, currentTimeMs);
} else {
//2.3 如果不是candidate,记录拒绝投票
state.recordRejectedVote(remoteNodeId);
// If our vote is rejected, we go immediately to the random backoff. This
// ensures that we are not stuck waiting for the election timeout when the // vote has become gridlocked.
//2.4 如果拒绝投票,则进入随机退避,确保我们不会在选举超时之后被卡住
if (state.isVoteRejected() && !state.isBackingOff()) {
logger.info("Insufficient remaining votes to become leader (rejected by {}). " +
"We will backoff before retrying election again", state.rejectingVoters());
state.startBackingOff(
currentTimeMs,
binaryExponentialElectionBackoffMs(state.retries())
);
}
}
} else {
logger.debug("Ignoring vote response {} since we are no longer a candidate in epoch {}",
partitionResponse, quorum.epoch());
}
return true;
} else {
return handleUnexpectedError(error, responseMetadata);
}
6. 日志快照
Raft算法约定每个节点定期要对log数据做snapshot,用于故障后恢复,在KRaft视线中,在以下场景中会加载snapshot数据:
- broker启动时
- follower从leader节点fetch了一个新snapshot时
对于KRaft的日志做Snapshot的时机,通过以下两个参数进行控制:
metadata.snapshot.min.changed_records.ratio:最新一次snapshot后,新产生的snapshot频率
metadata.log.max.record.bytes.between.snapshots:最新一次snapshot后的record字节数
生成snapshot的逻辑由org.apache.kafka.image.publisher.SnapshotGenerator来实现,它实现了MetadataPublisher接口,会在每次metadata更新时检查是否需要做snapshot。
@Override
public void onMetadataUpdate(
MetadataDelta delta,
MetadataImage newImage,
LoaderManifest manifest
) {
switch (manifest.type()) {
case LOG_DELTA:
publishLogDelta(delta, newImage, (LogDeltaManifest) manifest);
break;
case SNAPSHOT:
publishSnapshot(delta, newImage, (SnapshotManifest) manifest);
break;
}
}
针对于metadata的增量监控,满足配置项的任一条件都会调度snapshot生成:
void publishLogDelta(
MetadataDelta delta,
MetadataImage newImage,
LogDeltaManifest manifest
) {
//1.1 更新bytesSinceLastSnapshot
bytesSinceLastSnapshot += manifest.numBytes();
//1.2 检查当前写入bytes是否大于配置项
if (bytesSinceLastSnapshot >= maxBytesSinceLastSnapshot) {
//1.3 如果queue为空,立即触发生成snapshot
if (eventQueue.isEmpty()) {
scheduleEmit("we have replayed at least " + maxBytesSinceLastSnapshot +
" bytes", newImage);
} else if (log.isTraceEnabled()) {
log.trace("Not scheduling bytes-based snapshot because event queue is not empty yet.");
}
} else if (maxTimeSinceLastSnapshotNs != 0 &&
(time.nanoseconds() - lastSnapshotTimeNs >= maxTimeSinceLastSnapshotNs)) {
//2.1 如果time条件满足也会触发生成snapshot
if (eventQueue.isEmpty()) {
scheduleEmit("we have waited at least " +
TimeUnit.NANOSECONDS.toMinutes(maxTimeSinceLastSnapshotNs) + " minute(s)", newImage);
} else if (log.isTraceEnabled()) {
log.trace("Not scheduling time-based snapshot because event queue is not empty yet.");
}
} else if (log.isTraceEnabled()) {
log.trace("Neither time-based nor bytes-based criteria are met; not scheduling snapshot.");
}
}
触发snapshot的scheduleEmit方法通过调用Emitter实现snapshot创建。
void scheduleEmit(
String reason,
MetadataImage image
) {
//1.1 重置counter
resetSnapshotCounters();
eventQueue.append(() -> {
//1.2 检查是否禁用snapshot
String currentDisabledReason = disabledReason.get();
if (currentDisabledReason != null) {
log.error("Not emitting {} despite the fact that {} because snapshots are " +
"disabled; {}", image.provenance().snapshotName(), reason,
currentDisabledReason);
} else {
//2.1 触发创建snapshot
log.info("Creating new KRaft snapshot file {} because {}.",
image.provenance().snapshotName(), reason);
try {
emitter.maybeEmit(image);
} catch (Throwable e) {
faultHandler.handleFault("KRaft snapshot file generation error", e);
}
}
});
}
实际创建snapshot的流程:
override def createNewSnapshot(snapshotId: OffsetAndEpoch): Optional[RawSnapshotWriter] = {
//1.1 检查传入offset是否小于start offset和high watermark
if (snapshotId.offset < startOffset) {
info(s"Cannot create a snapshot with an id ($snapshotId) less than the log start offset ($startOffset)")
return Optional.empty()
}
val highWatermarkOffset = highWatermark.offset
if (snapshotId.offset > highWatermarkOffset) {
throw new IllegalArgumentException(
s"Cannot create a snapshot with an id ($snapshotId) greater than the high-watermark ($highWatermarkOffset)"
)
}
//1.2 检查offset和epoch
val validOffsetAndEpoch = validateOffsetAndEpoch(snapshotId.offset, snapshotId.epoch)
if (validOffsetAndEpoch.kind() != ValidOffsetAndEpoch.Kind.VALID) {
throw new IllegalArgumentException(
s"Snapshot id ($snapshotId) is not valid according to the log: $validOffsetAndEpoch"
)
}
//2.1 调用createNewSnapshotUnchecked返回RawSnapshotWriter
createNewSnapshotUnchecked(snapshotId)
}
createNewSnapshotUnchecked方法通过创建FileRawSnapshotWriter对象,其内部封装了对应日志文件的FileChannel。
override def createNewSnapshotUnchecked(snapshotId: OffsetAndEpoch): Optional[RawSnapshotWriter] = {
//1.1 检查是否已有该snapshot
val containsSnapshotId = snapshots synchronized {
snapshots.contains(snapshotId)
}
if (containsSnapshotId) {
Optional.empty()
} else {
Optional.of(
//传入log dir,通过FileRawSnapshotWriter创建,FileRawSnapshotWriter内部封装了FileChannel
new NotifyingRawSnapshotWriter(
FileRawSnapshotWriter.create(log.dir.toPath, snapshotId),
onSnapshotFrozen
)
)
}
}