1. Intro
Apache Kafka是一个分布式事件存储和流处理平台,最初由LinkedIn公司开发,旨在解决其内部大规模实时数据流存储的问题。在2011年初,LinkedIn将Kafka作为开源项目发布,并于2012年10月23日,Kafka从Apache孵化器毕业,成为Apache软件基金会的顶级项目。2014年11月,几位曾在LinkedIn参与Kafka开发的工程师,包括Jay Kreps、Neha Narkhede和Jun Rao,离开LinkedIn创立了Confluent公司,专注于提供与Kafka相关的企业级支持和服务。
1.1. 设计亮点
| 方案 | 细节 |
|---|---|
| 磁盘存储+pagecache替代内存缓存 | JVM语言操作内存成本较高,并且Kafka为重网络I/O应用,顺序读写+pagecache场景下磁盘I/O并不会成为性能瓶颈 |
| 合适的数据结构 | 数据存储系统通常使用Btree进行持久化存储,而message system通常为尾端I/O,使用queue可以实现O(1) |
| 异步batch I/O | producer端积攒一批消息,使用一次网络I/O传输到broker,降低多次small I/O的次数 |
| 文件零拷贝 | broker向client返回log数据时,使用mmap内存映射避免多次 |
| 消息压缩 | 端到端传输/存储时,会对原始消息进行压缩 |
| broker负载均衡 | topic再次物理划分partition,producer写入请求均衡打到各个partition所在broker |
| ISR机制 | 基于多副本机制,实现集群容错和高可用 |
| broker端网络模式 | 使用Reactor网络模式,按职责划分为:接受请求的acceptor,实际处理逻辑的processor,提升了broker端吞吐量 |
| exactly once语义 | producer端:开启幂等性后,每条消息都会附带sequence number,broker端严格接受递增sequence number,确保不会存在重复数据。 consumer端:实现消费-处理-提交 offset 的原子性(事务实现) |
1.2. 消息模型
1.2.1. Queue Model(peer to peer)
生产者将消息发送到Queue时会进行暂时存储,当消费者完成消费或者消息TTL到期,将会从队列中移除,每条消息只有一个consumer进行消费。
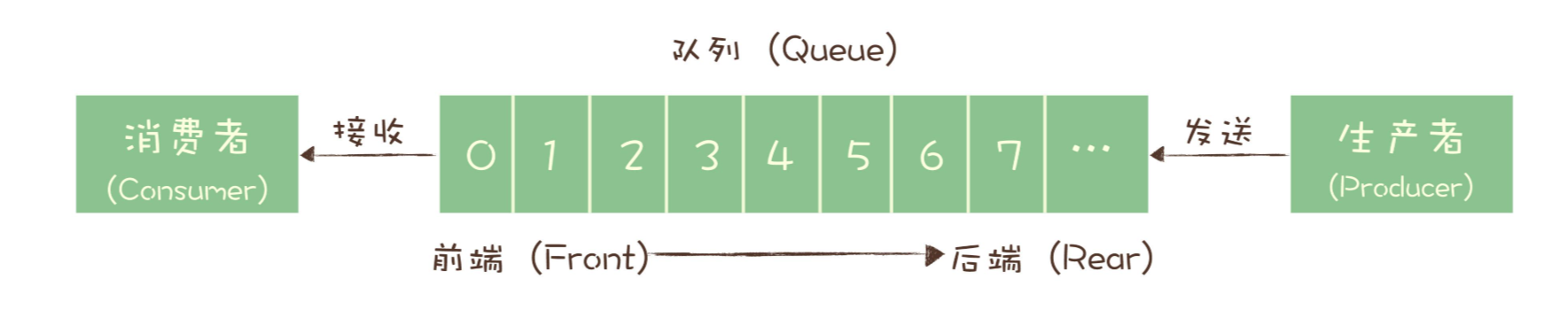
案例:redis queue、Amazon SQS、RabbitMQ、activeMQ等
1.2.2. Pub/Sub Model
发布/订阅(Pub/Sub)模型是一种异步消息传递模式,旨在实现应用程序组件之间的解耦。在这种模式中,消息发布者Publisher将消息发布到特定的Topic,而消息订阅者Subscriber则订阅感兴趣的主题,以接收相关消息。这种方式使得发布者和订阅者彼此独立,不直接通信,从而提高系统的灵活性和可扩展性。
案例:Kafka、AutoMQ、Pulsar等
1.3. Streaming Storage Platform选型
| 维度 | ActiveMQ | RabbitMQ | RocketMQ | Kafka | Pulsar |
|---|---|---|---|---|---|
| 单机吞吐量 | 较低(万级) | 一般(万级) | 高(十万级) | 高(十万级) | 高(十万级) |
| 开发语言 | Java | Erlang | Java | Java/Scala | Java |
| 维护者 | Apache | Spring | Apache(Alibaba) | Apache(Confluent) | Apache(StreamNative) |
| 社区活跃度 | 低 | 高 | 高 | 高 | 高 |
| 消费模式 | P2P、Pub-Sub | direct、topic、Headers、fanout | 基于 Topic 和 MessageTag 的的 Pub-Sub | 基于 Topic 的 Pub-Sub | 基于 Topic 的 Pub-Sub,支持独占(exclusive)、共享(shared)、灾备(failover)、key 共享(key_shared)4 种模式 |
| 持久化 | 支持(小) | 支持(小) | 支持(大) | 支持(大) | 支持(大) |
| 顺序消息 | 不支持 | 不支持 | 支持 | 支持 | 支持 |
| 集群支持 | 主备模式 | 复制模式 | 主备模式 | Leader-Slave 每台既是 master 也是 slave,集群可扩展性强 | 集群模式,broker 无状态,易迁移,支持跨数据中心 |
| 存算分离 | 不支持 | 不支持 | 支持 | 支持 | 支持 |
| AMQP 支持 | 支持 | 支持 | 支持 | 不完全支持 | 不完全支持 |
1.4. 相关术语介绍
- Kafka Broker:服务端由被称为
Broker的服务进程构成,Broker负责接受和处理客户端请求,以及对消息进行持久化。 - Kafka Controller:集群metadata的管理节点
- Producer:客户端节点,消息生产方。
- Customer:客户端节点,消息消费方。
- Customer Group:消费者组内每个消费者负责消费不同分区的数据。一个分区只能由组内一个消费者消费,不同消费组之间互不影响。
Zookeeper集群:负责元数据管理,集群选举。近期发布(2025.03)的4.0版本已经移除Zookeeper依赖,使用内置KRaft模式管理metadata。- Topic:Kafka中消息以topic为单位进行分类,生产者将消息发送到特定的topic,消费者订阅topic进行消费。
- Partition:针对Topic维度按照消息key的分区,均衡分布到Kafka集群中的各个节点,对数据存储做到均匀分布。
- Replica:针对Partition维度的副本数据,实现数据备份的功能。
2. Client
Kafka clients有5个核心API:
- Producer API:客户端发送消息到Kafka Topic。
- Consumer API:客户端从Kafka集群消费消息。
- Streams API:轻量级流式计算框架。
- Connect API:不断从源数据系统拉取数据到Kafka,或者从Kafka提交数据到目标系统。
- Admin API:用于检查和管理topic、broker等资源。
2.1. Producer
设计亮点:
- 负载均衡:Producer可以控制将消息发送到指定partition,并且消息直接发送到partition leader所在的broker(不会经过任意的route层),分区规则同样暴露了接口给用户用于自定义配置。
- 异步消息发送:Producer会在内存中积累一批数据,在一个请求中同时发送,减少多次小I/O,提升了系统吞吐量。
2.1.1. 核心API
send方法提供了以下两种异步方式:
/**
* See {@link KafkaProducer#send(ProducerRecord)}
*/Future<RecordMetadata> send(ProducerRecord<K, V> record);
/** 支持回调方法
* See {@link KafkaProducer#send(ProducerRecord, Callback)}
*/Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
案例:
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "172.28.203.172:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
Producer常用配置项:
- bootstrap.servers:Kafka集群的地址,集群地址使用逗号隔开。
- acks:指定分区中必须要有多少个副本收到这条消息,之后producer认为这条消息是成功写入的,通常与其他配置项共同使用,取值如下:
- 1:只要Leader副本成功写入,就会收到来自服务端的成功响应。
- 0:生产者发送消息之后不需要等待任何服务器的响应,可以得到最大吞吐量,但是消息丢失无法得知。
- 1/all:消息发送后,需要等待所有副本都写入消息后才能收到服务器的响应,可以达到最强的可靠性。
- retries:请求发送失败,生产者会重试,设置为0禁止重试。
- batch.size:等待发送的消息buffer大小。
- linger.ms:生产者发送请求前等待一段时间,希望更多消息进入buffer,并按批发送。
- buffer.memory:producer可用的缓存大小。
- key.serializer、value.serializer:序列化类
- max.request.size:限制producer能发送消息的最大值。默认值为1MB。
- connections.max.idle.ms:指定多久之后关闭限制的连接。
- compression.type:producer端压缩方式,默认为none,可选
gzip,lz4,snappy,zstd- 注意broker端有相同配置项,若broker端配置
compression.type=producer,则broker在进行消息写入时,直接使用producer传来的压缩数据。
- 注意broker端有相同配置项,若broker端配置
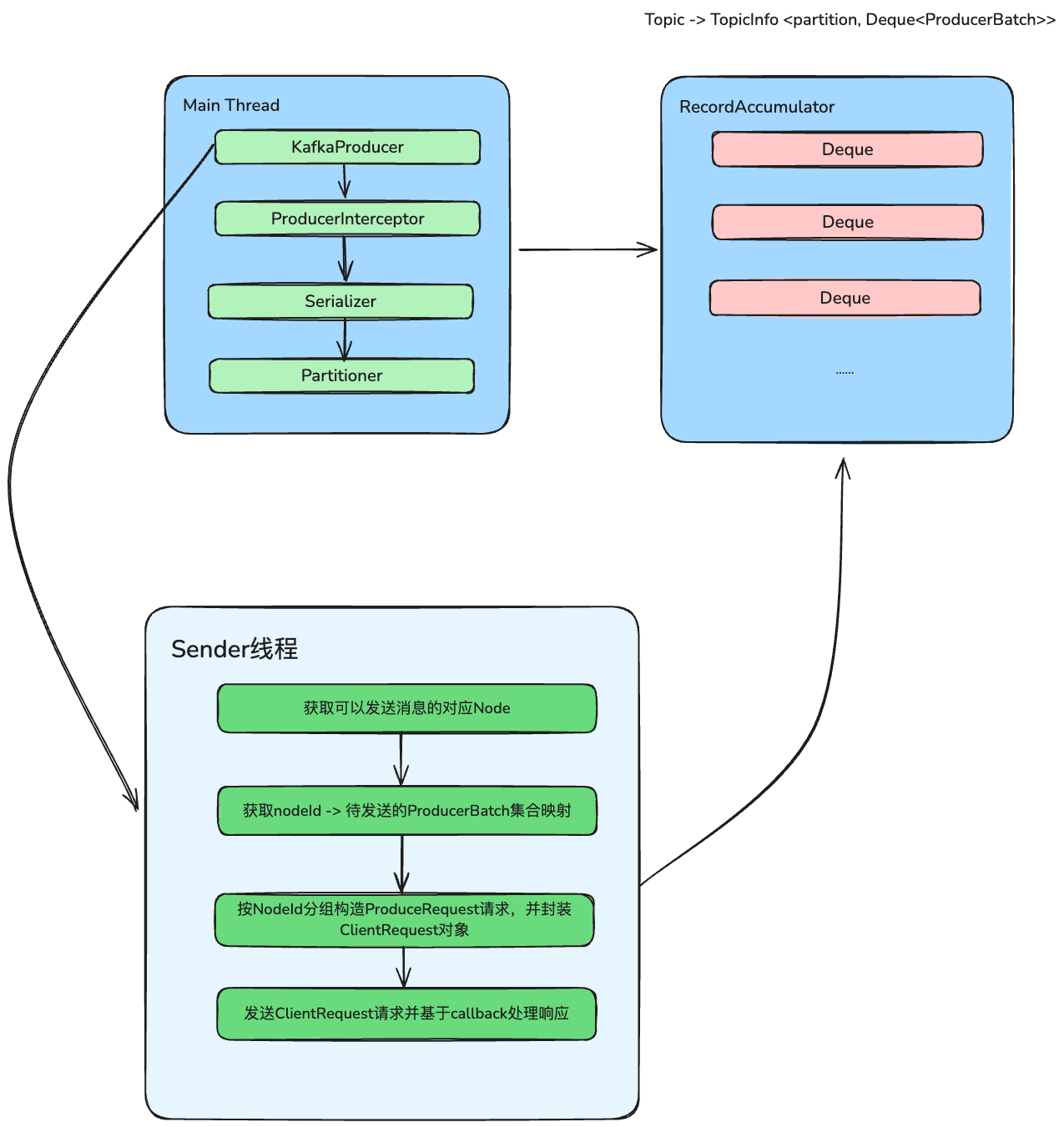
2.1.2. send流程
send流程:
- 执行前置interceptor逻辑
- 拉取topic相关的元数据
- key、value进行序列化
- 计算消息所属的partition
- 将消息追加到accumulator中,这一步会完成消息压缩、消息头转换等操作
- 检查是否满足条件,唤醒sender线程将攒批消息发送出去
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// 拦截器前置send动作
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
// 1.1 创建callback对象
AppendCallbacks appendCallbacks = new AppendCallbacks(callback, this.interceptors, record);
try {
//1.2 检查producer是否被close
throwIfProducerClosed();
// first make sure the metadata for the topic is available
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
//1.3 拉取指定topic、分区的元数据,和等待时间
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
//1.4 key value进行序列化
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 1.5 计算当前消息所属的partition
int partition = partition(record, serializedKey, serializedValue, cluster);
// 1.6 设置消息header为readOnly
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
//1.7 检查消息大小是否符合
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compression.type(), serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
// 自定义partitioner
boolean abortOnNewBatch = partitioner != null;
// 1.8 将消息追加到accumulator中
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
assert appendCallbacks.getPartition() != RecordMetadata.UNKNOWN_PARTITION;
// 1.9 消息入新batch的情况
if (result.abortForNewBatch) {
int prevPartition = partition;
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
// 2.1 开启事务的情况
if (transactionManager != null) {
transactionManager.maybeAddPartition(appendCallbacks.topicPartition());
}
// 2.2 如果batch满了,或者新batch被创建,唤醒后台sender线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future, // for other exceptions throw directly } catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null) {
TopicPartition tp = appendCallbacks.topicPartition();
RecordMetadata nullMetadata = new RecordMetadata(tp, -1, -1, RecordBatch.NO_TIMESTAMP, -1, -1);
callback.onCompletion(nullMetadata, e);
}
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
if (transactionManager != null) {
transactionManager.maybeTransitionToErrorState(e);
}
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
}
}
2.1.3. Sender线程
sender在KafkaProducer构造方法中初始化:
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
Sender是一个Runnable对象,核心逻辑如下:
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
runOnce()通过sendProducerData()执行实际的发送逻辑,最后通过poll()方法处理网络IO请求
void runOnce() {
……
//省略事务处理
//创建发送给broker的请求并发送
long currentTimeMs = time.milliseconds();
long pollTimeout = sendProducerData(currentTimeMs);
//处理实际网络IO socket的入口,负责发送请求、接收响应
client.poll(pollTimeout, currentTimeMs);
}
sendProducerData方法主干逻辑如下:
- 调用RecordAccumulator的ready()方法获取可以发送的Node消息
- 调用RecordAccumulator的drain(),获取nodeId -> 待发送的ProducerBatch集合映射
- 调用sendProduceRequests()按Node分组发送请求
2.1.4. interceptor机制
send方法中首先会检查用户是否自定义interceptor实现,用于处理send前置逻辑。
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// 拦截器前置send动作
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
其中ProducerInterceptor提供了以下接口:
- ProducerRecord<K, V> onSend(ProducerRecord<K, V> record):send前置处理逻辑
- onAcknowledgement(RecordMetadata metadata, Exception exception):消息被应答之后或发送消息失败时调用。
- close():用于关闭interceptor资源。
自定义interceptor需要考虑线程安全问题。
2.1.5. partition机制
Producer中计算消息partition的流程较为简单:
- 若record指定partition,则直接使用传入partition。
- 若配置了partitioner则使用对应partitioner的分区计算方式
- 若指定了key并未配置
partitioner.ignore.keys,则使用murmur2算法得出partition - 否则将partition设置为UNKNOWN_PARTITION,这会在org.apache.kafka.clients.producer.internals.RecordAccumulator#append方法中进行处理。
消息partition计算逻辑:
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
if (record.partition() != null)
return record.partition();
if (partitioner != null) {
int customPartition = partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
if (customPartition < 0) {
throw new IllegalArgumentException(String.format(
"The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition));
}
return customPartition;
}
if (serializedKey != null && !partitionerIgnoreKeys) {
// hash the keyBytes to choose a partition
return BuiltInPartitioner.partitionForKey(serializedKey, cluster.partitionsForTopic(record.topic()).size());
} else {
return RecordMetadata.UNKNOWN_PARTITION;
}
}
Kafka同样提供了自定义partitioner的方式,Partitioner接口包含以下三个方法:
- int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster):自定义分区计算方法。
- void close():用于partitioner关闭资源的方法。
- void onNewBatch(String topic, Cluster cluster, int prevPartition):从3.3.0开始废弃,用于通知partitioner新分区被创建,sticky分区方式可以改变新分区的黏性分区。
需要注意的是, KIP-794中指出,sticky分区方式会将消息发送给响应更慢的broker,慢broker因此收到更多的消息,逐渐变得更慢,因此在该提案中,做了如下更新:
- 移除配置项
partitioner.class,partitioner默认配置设置为null,并且DefaultPartitioner和UniformStickyPartitioner都被废弃 - 添加新配置用于分区计算逻辑中
2.1.6. Producer端压缩
消息压缩对于Kafka这类重网络、文件I/O的系统在性能上有显著提升,提升了系统吞吐量,在实现上同时支持producer端和broker端,producer端可通过修改compression.type配置项项完成客户端压缩,可选配置: none, gzip, lz4, snappy, and zstd。
broker端同样提供了compression.type配置项,默认为producer,若为默认配置,则broker端直接写入。

2.2. Consumer
Consumer包继承关系如下图所示:
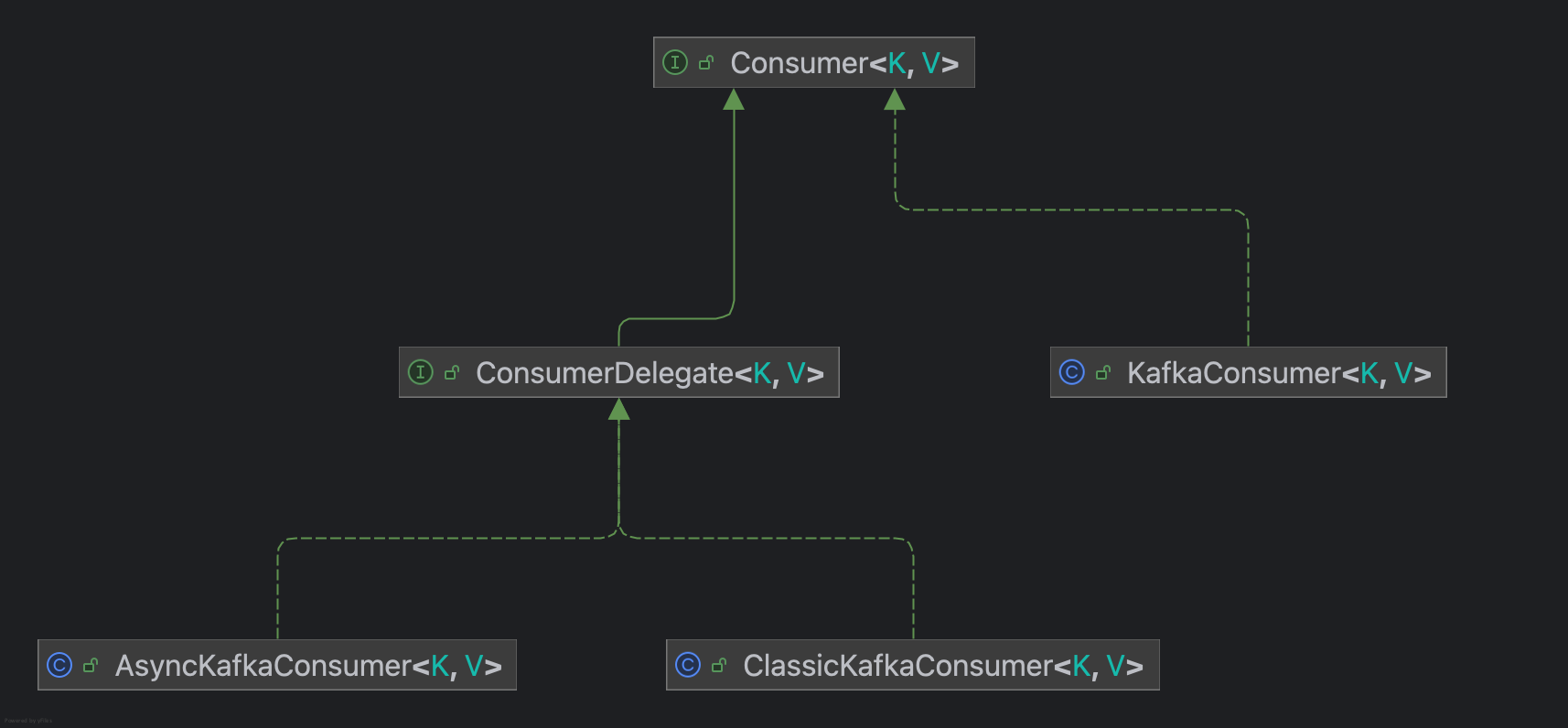
KafkaConsumer使用了委派模式(Delegate Pattern),提供API供clients使用,而ConsumerDelegate作为Delegate接口,提供了两种实现方式,通过配置group.protocol进行控制,其中ClassicKafkaConsumer所有的线程都会处理网络IO请求,AsyncKafkaConsumer则是基于Reactor模式,使用单独线程处理网络IO,以事件驱动模式处理任务,下文以AsyncKafkaConsumer为例,具体细节见 Consumer threading refactor design。
2.2.1. Consumer事件处理逻辑
AsyncKafkaConsumer的核心使用事件驱动模式来处理各类事件,事件类型见org.apache.kafka.clients.consumer.internals.events.ApplicationEvent
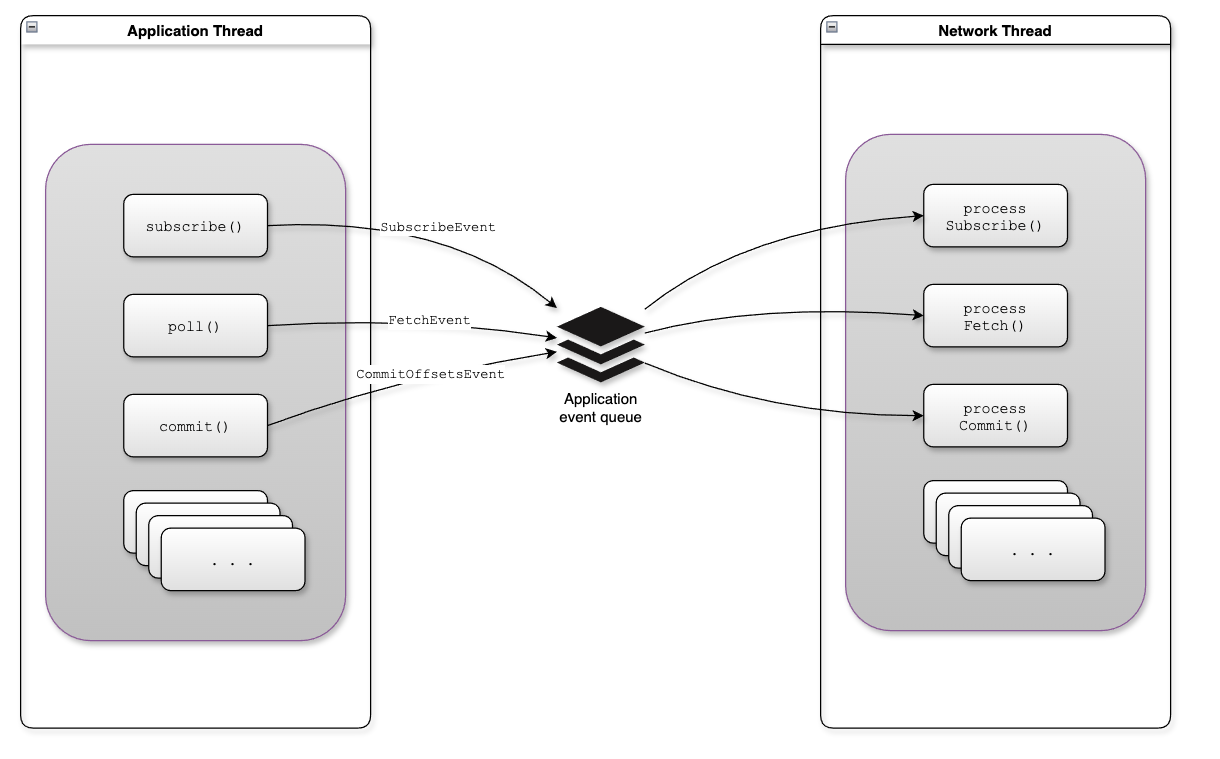
ConsumerNetworkThread是用于后台处理event的线程,并负责处理broker的网络IO。
线程的run()方法通过while循环循环调用runOnce(),runOnce()方法主要处理以下几个任务:
- 提取event并使用ApplicationEventProcessor处理application event
- 遍历RequestManager并调用poll()方法
- 调用NetworkClientDelegate. addAll(List)将request添加到unsentRequests队列中
- 调用KafkaClient. poll(long, long)向broker发送请求
public void run() {
try {
log.debug("Consumer network thread started");
// Wait until we're securely in the background network thread to initialize these objects...
initializeResources();
while (running) {
try {
runOnce();
} catch (final Throwable e) {
// Swallow the exception and continue
log.error("Unexpected error caught in consumer network thread", e);
}
}
} finally {
cleanup();
}
}
2.2.2. API使用案例
@Test
public void testConsumer() {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("client.id","consumer.client.id.demo");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
2.2.3. 订阅主题
subscribe方法来订阅主题,若多次调用,以最后一次作为消费的主题。
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
if (listener == null)
throw new IllegalArgumentException("RebalanceListener cannot be null");
subscribeInternal(topics, Optional.of(listener));
}
subscribeInternal()方法用于处理实际的subscribe逻辑。
private void subscribeInternal(Collection<String> topics, Optional<ConsumerRebalanceListener> listener) {
//1.1 获取lock,并且判断是否已经close
acquireAndEnsureOpen();
try {
//1.2 判断group id是否有效
maybeThrowInvalidGroupIdException();
//1.3 校验参数
if (topics == null)
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
//1.4 若为空,则unsubscribe
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
unsubscribe();
} else {
for (String topic : topics) {
if (isBlank(topic))
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
// 1.5 更新buffer中不再指定的partition
final Set<TopicPartition> currentTopicPartitions = new HashSet<>();
for (TopicPartition tp : subscriptions.assignedPartitions()) {
if (topics.contains(tp.topic()))
currentTopicPartitions.add(tp);
}
fetchBuffer.retainAll(currentTopicPartitions);
log.info("Subscribed to topic(s): {}", String.join(", ", topics));
// 1.6 调用SubscriptionState.subscribe 更新订阅topic
if (subscriptions.subscribe(new HashSet<>(topics), listener))
//若请求成功,更新metadata
this.metadataVersionSnapshot = metadata.requestUpdateForNewTopics();
// 1.7 向handler添加event
applicationEventHandler.add(new SubscriptionChangeEvent());
}
} finally {
//1.8 释放lock
release();
}
}
2.2.4. 位移提交
位移提交的动作是消费完所有拉取到的信息之后执行的,如果消费过程中出现了异常,在故障恢复之后,会发生重复消费的现象,consumer需要做幂等性保障。
Kafka中消费位移的提交方式是自动提交,由消费者客户端参数enable.auto.commit控制,默认为true,定期提交的周期时间由auto.commit.interval.ms控制,默认为5s。
消费者每隔5秒会将拉取到的每个分区中最大的消息位移进行提交。自动位移提交的动作是在poll()方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。
服务端将commited offset保存在__consumer_offsets,它是由Kafka自动创建的,和普通的Topic存储格式相同。
3. Server
3.1. 架构简析
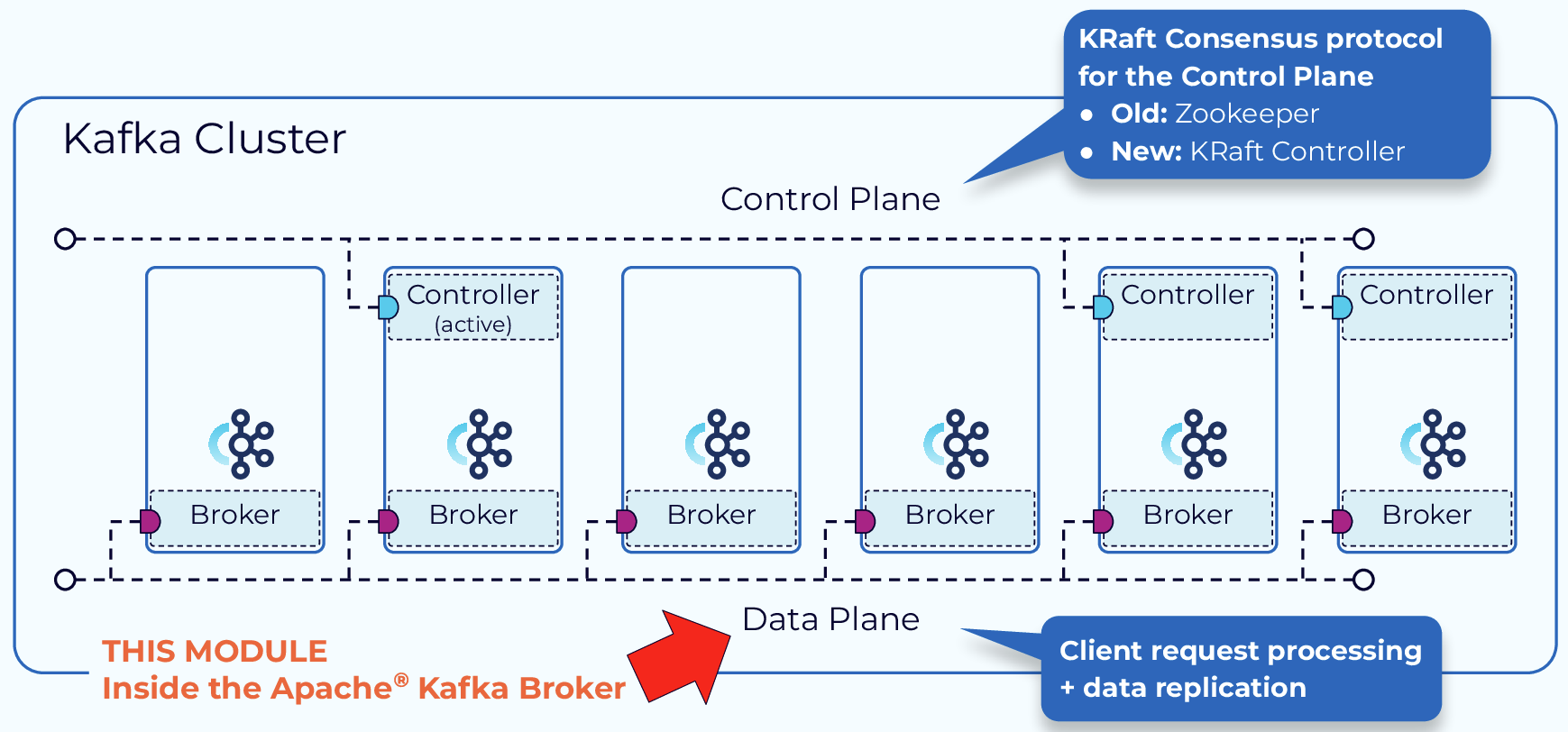
Kafka属于单Master多Worker架构,Zookeeper主要提供了metadata存储、分布式同步、集群Leader选举等功能。
至于为何当下Kafka抛弃Zookeeper组建转而选择自建Raft代替metadata管理,也是一个老生常谈的问题:
- Zookeeper作为单独的分布式系统,加大了Kafka集群的部署、运维成本。
- Zookeeper存在性能瓶颈,无法支撑更大的集群规模,而自建KRaft支持更大数据量级的分区元数据管理。
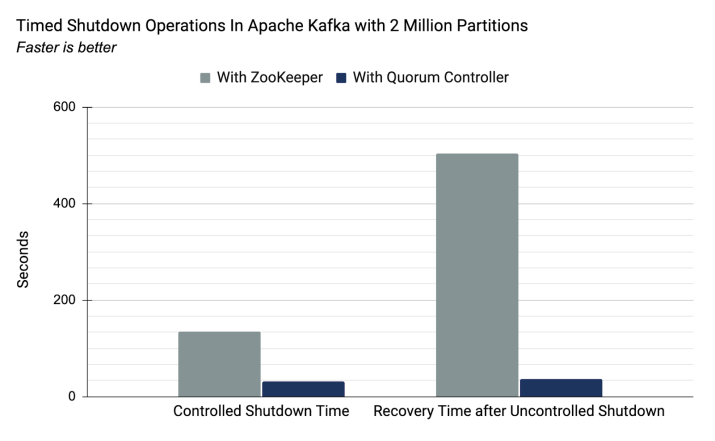
3.2. 存储设计
Kafka是为了解决大数据量的实时日志流而产生的,日志流主要特点包括:
- 数据实时写入/读取
- 海量数据存储与处理
Kafka中消息以Topic为分类,各个Topic下面分为多个分区,分区中每条消息都会被分配一个唯一的序列号(offset)。Kafka使用的存储方案是:磁盘顺序写 + 稀疏哈希索引。
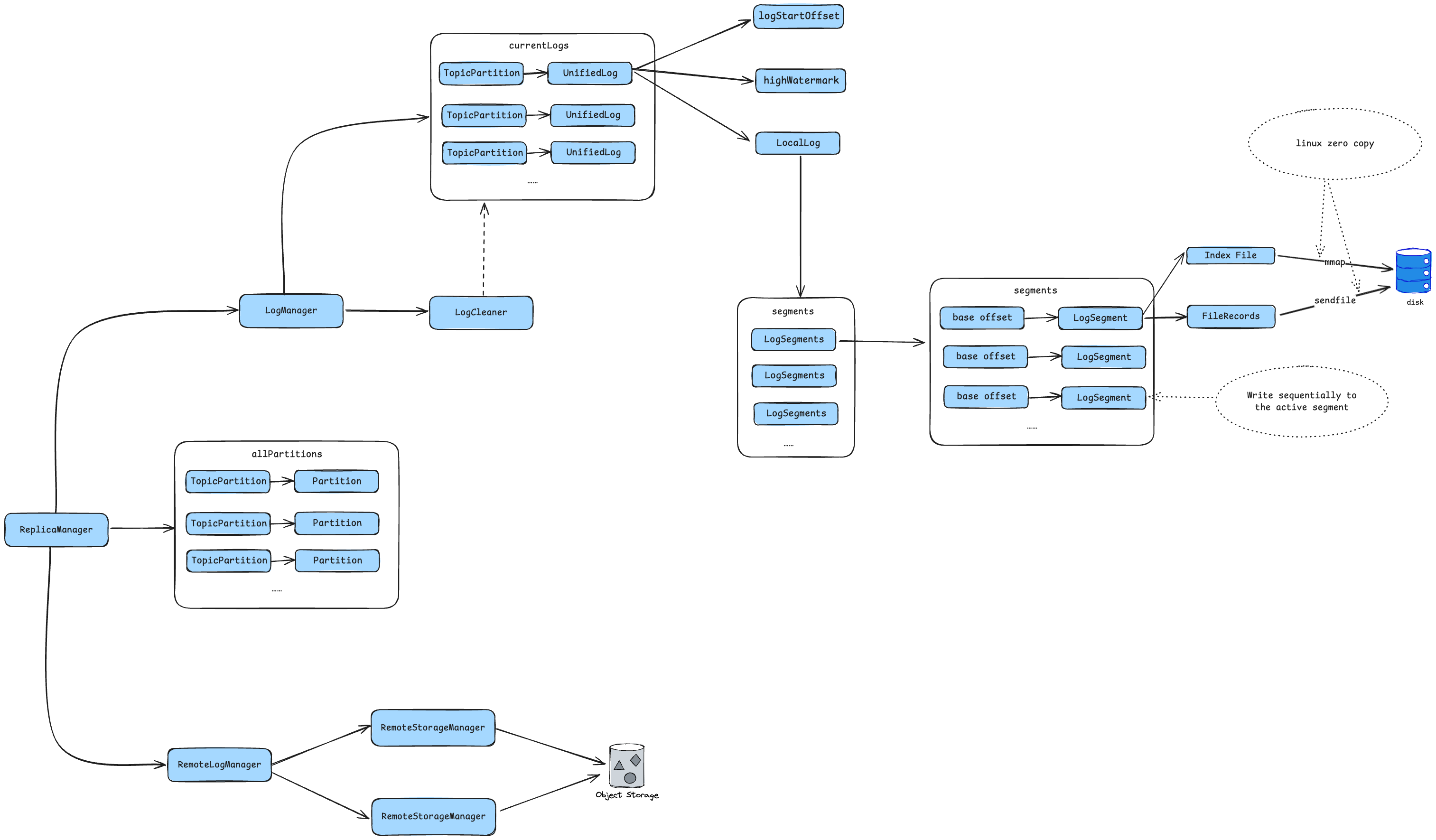
3.2.1. 分层存储设计
Kafka在KIP-405: Kafka Tiered Storage - Apache Kafka - Apache Software Foundation中提出分层存储的概念,将冷热数据同时存储在本地磁盘和云服务中,用以达到降低数据存储成本的目的。
在这种存储模式下,老数据可以在低成本云存储服务上存储更长时间,并削减数据存储成本,分层存储将一个topicPartition划分为两个逻辑存储组件,分别为:local log和remote log,下图中的offset呈降序排列。
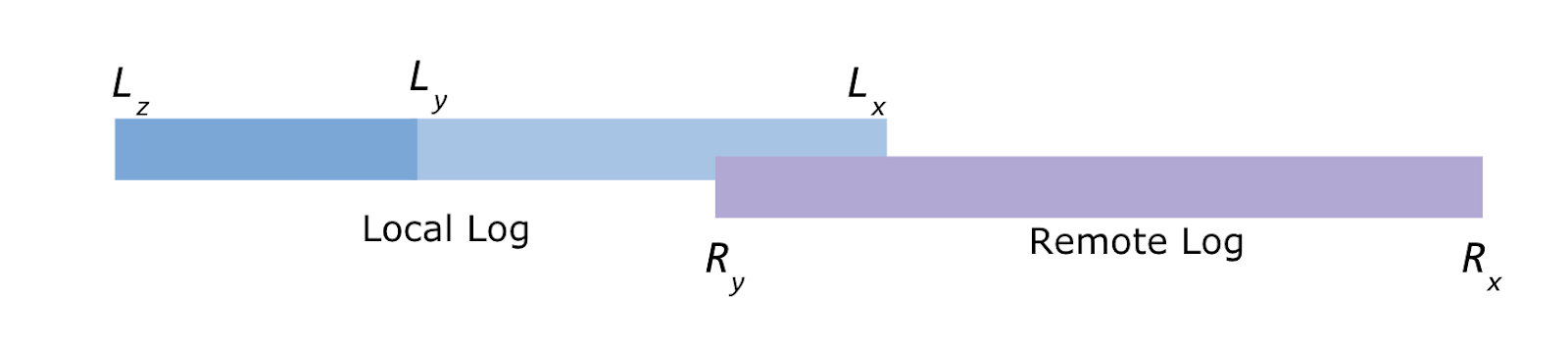
从存储架构可以看出,远程存储模块包含以下组件:
- RemoteStorageManager
- RemoteLogMetadataManager:负责管理metadata生命周期,使用内部topic进行存储,用户可通过接口实现自定义存储。
- RemoteLogManager:用于管理remote log segments生命周期的逻辑层组件,指责包括:
- 拷贝本地segments至远程存储服务
- 清理远程存储服务中过期segments数据
- 从远程存储服务拉取log数据
3.2.2. LogSegment
Kafka Log由多个LogSegment构成,每个LogSegment对应一个分区,每个LogSegment对象都会在磁盘中创建一组文件:
- 日志消息文件(.log)
- 位移索引文件(.index)
- 时间戳索引文件(.timeindex)
- 已中止事务的索引文件(.txnindex)
org.apache.kafka.storage.internals.log.LogSegment中存在以下属性:
// 日志消息文件对象,FileRecords是文件关联对象
private final FileRecords log;
//三个索引文件对象
private final LazyIndex<OffsetIndex> lazyOffsetIndex;
private final LazyIndex<TimeIndex> lazyTimeIndex;
private final TransactionIndex txnIndex;
//起始offset
private final long baseOffset;
//broker端参数log.index.interval.bytes值,用于控制LogSegment新增索引项的频率,默认写入4KB时新增一条索引项
private final int indexIntervalBytes;
//LogSegment新增数据的扰动值,打散磁盘IO
private final long rollJitterMs;
//写入日志的最新时间戳
private volatile OptionalLong rollingBasedTimestamp = OptionalLong.empty();
//最后一次更新索引至今,写入的字节数
private int bytesSinceLastIndexEntry = 0;
3.2.3. FileRecords
log字段是FileRecords,该对象内部包括File对象、文件开始结束位置、文件大小、FileChannel,append方法通过FileChannel完成消息写入:
/**
* Append a set of records to the file. This method is not thread-safe and must be * protected with a lock. * * @param records The records to append
* @return the number of bytes written to the underlying file
*/public int append(MemoryRecords records) throws IOException {
if (records.sizeInBytes() > Integer.MAX_VALUE - size.get())
throw new IllegalArgumentException("Append of size " + records.sizeInBytes() +
" bytes is too large for segment with current file position at " + size.get());
int written = records.writeFullyTo(channel);
size.getAndAdd(written);
return written;
}
/**
* Commit all written data to the physical disk */public void flush() throws IOException {
channel.force(true);
}
/**
* Close this record set */public void close() throws IOException {
flush();
trim();
channel.close();
}
在初始化LogSegment时,会调用FileRecords的open方法完成内部log字段的初始化:
public static FileRecords open(File file,
boolean mutable,
boolean fileAlreadyExists,
int initFileSize,
boolean preallocate) throws IOException {
FileChannel channel = openChannel(file, mutable, fileAlreadyExists, initFileSize, preallocate);
int end = (!fileAlreadyExists && preallocate) ? 0 : Integer.MAX_VALUE;
return new FileRecords(file, channel, 0, end, false);
}
3.3. 索引设计
3.3.1. 索引基础
索引通常用于加速数据查找的场景,在实现上,Kafka采取稀疏索引的方式,通过配置项index.interval.bytes进行控制,默认值为4096KB,每隔4KB日志进行写入一次索引。
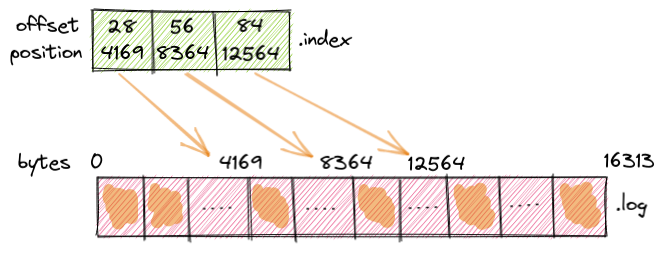
LogSegment日志对象管理以下三种Index:
- 位移索引文件(.index):索引key为offset,value为日志文件position
- 时间戳索引文件(.timeindex):索引key为timestamp,value为offset
- 已中止事物的索引文件(.txnindex)
public class LogSegment implements Closeable {
private final LazyIndex<OffsetIndex> lazyOffsetIndex;
private final LazyIndex<TimeIndex> lazyTimeIndex;
private final TransactionIndex txnIndex;
}
3.3.2. 懒加载
在Kafka Server初始化时并不会直接读取磁盘中的索引文件并将其加载到内存中,它使用了lazy-load机制,在首次读取索引时完成文件加载,提升了Broker启动初始化的速度。
public T get() throws IOException {
IndexWrapper wrapper = indexWrapper;
if (wrapper instanceof IndexValue<?>)
return ((IndexValue<T>) wrapper).index;
else {
lock.lock();
try {
if (indexWrapper instanceof IndexValue<?>)
return ((IndexValue<T>) indexWrapper).index;
else if (indexWrapper instanceof IndexFile) {
IndexFile indexFile = (IndexFile) indexWrapper;
IndexValue<T> indexValue = new IndexValue<>(loadIndex(indexFile.file));
indexWrapper = indexValue;
return indexValue.index;
} else
throw new IllegalStateException("Unexpected type for indexWrapper " + indexWrapper.getClass());
} finally {
lock.unlock();
}
}
}
loadIndex方法使用mmap方式完成索引文件的加载,减少内存拷贝的开销:
private T loadIndex(File file) throws IOException {
switch (indexType) {
case OFFSET:
return (T) new OffsetIndex(file, baseOffset, maxIndexSize, true);
case TIME:
return (T) new TimeIndex(file, baseOffset, maxIndexSize, true);
default:
throw new IllegalStateException("Unexpected indexType " + indexType);
}
}
3.3.3. 索引查找逻辑
对于Kafka而言,索引都是在文件末尾追加的顺序写入,因此二分查找具备天然优势,但是在具体实现上,做了如下优化:通常Kafka写入的数据在短期内通常会被读取,数据热点大都集中在尾部,如果使用常规的二分查找,会发生不必要的文件I/O动作(缺页中断)。
However, when looking up index, the standard binary search algorithm is not cache friendly, and can cause unnecessary page faults (the thread is blocked to wait for reading some index entries from hard disk, as those entries are not cached in the page cache).
因此Kafka在实现上,将索引项数据分为热区和冷区,在查询时,如果offset在热区范围,那么二分查找时直接将范围固定在热区中,并且能直接使用page cache中的索引数据。若是冷区范围则进行全量查找。
private int indexSlotRangeFor(ByteBuffer idx, long target, IndexSearchType searchEntity,
SearchResultType searchResultType) {
// check if the index is empty
if (entries == 0)
return -1;
//1.1 获取当前第一个热区entry offset
int firstHotEntry = Math.max(0, entries - 1 - warmEntries());
// 1.2 检查目标offset,是否在热区范围内
if (compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0) {
//1.3 缩减二分查找范围在热区范围内
return binarySearch(idx, target, searchEntity,
searchResultType, firstHotEntry, entries - 1);
}
//1.4 全量查找前检查offset是否小于最小offset
// check if the target offset is smaller than the least offset if (compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0) {
switch (searchResultType) {
case LARGEST_LOWER_BOUND:
return -1;
case SMALLEST_UPPER_BOUND:
return 0;
}
}
return binarySearch(idx, target, searchEntity, searchResultType, 0, firstHotEntry);
}
冷热区域划分规则:
protected final int warmEntries() {
return 8192 / entrySize();
}
至于选取8192的原因,注释中也做了详细说明:
- 4096几乎是所有CPU架构的page cache大小,如果再小无法保证覆盖更多的热数据。
- 8KB索引信息大约对应4MB的日志信息(offset index)或2.7MB(time index),这已经满足热区需求。
3.4. 日志清理策略
Kafka在存储一批消息后,会定期执行日志清理动作,通过配置项log.cleanup.policy选择日志清理策略,当前提供了两种配置:
- delete:所有用户topic的默认配置,broker会定期检查并清理配置的时间节点之前的日志数据,时间节点可通过
log.retention.hours进行控制,默认为一周。 - compact:对topic按照key进行compact压缩,最终保留的日志是每个key的最新数据,Kafka用于存储用户topic消费进度的
__consumer_offsets默认采用的该策略。
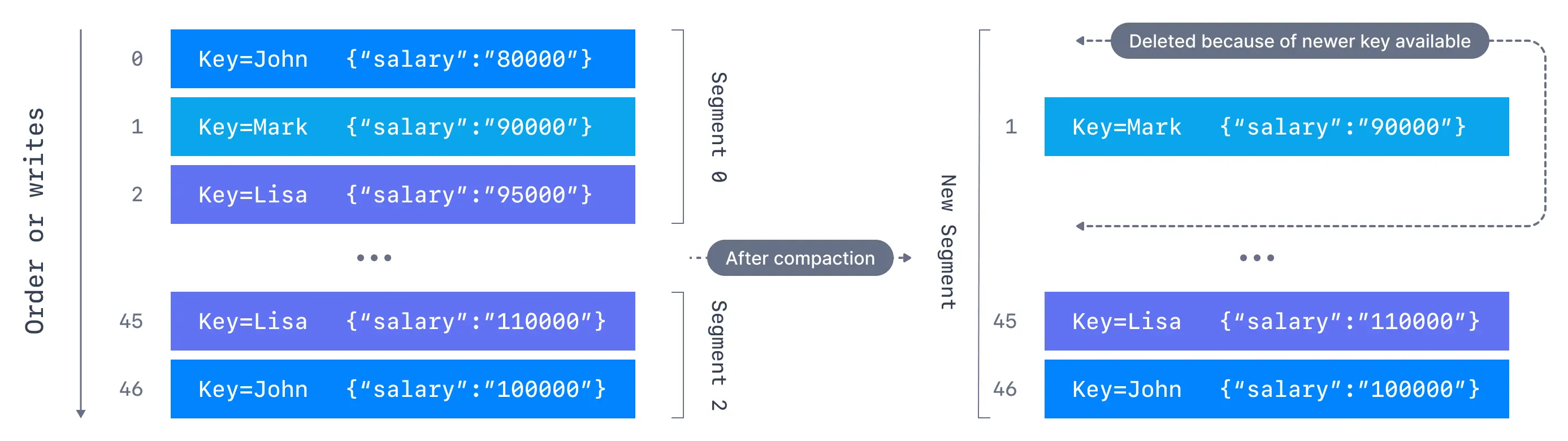
3.5. 网络通信设计
Kafka Server端网络通信设计如图所示(图片引用自AutoMQ):
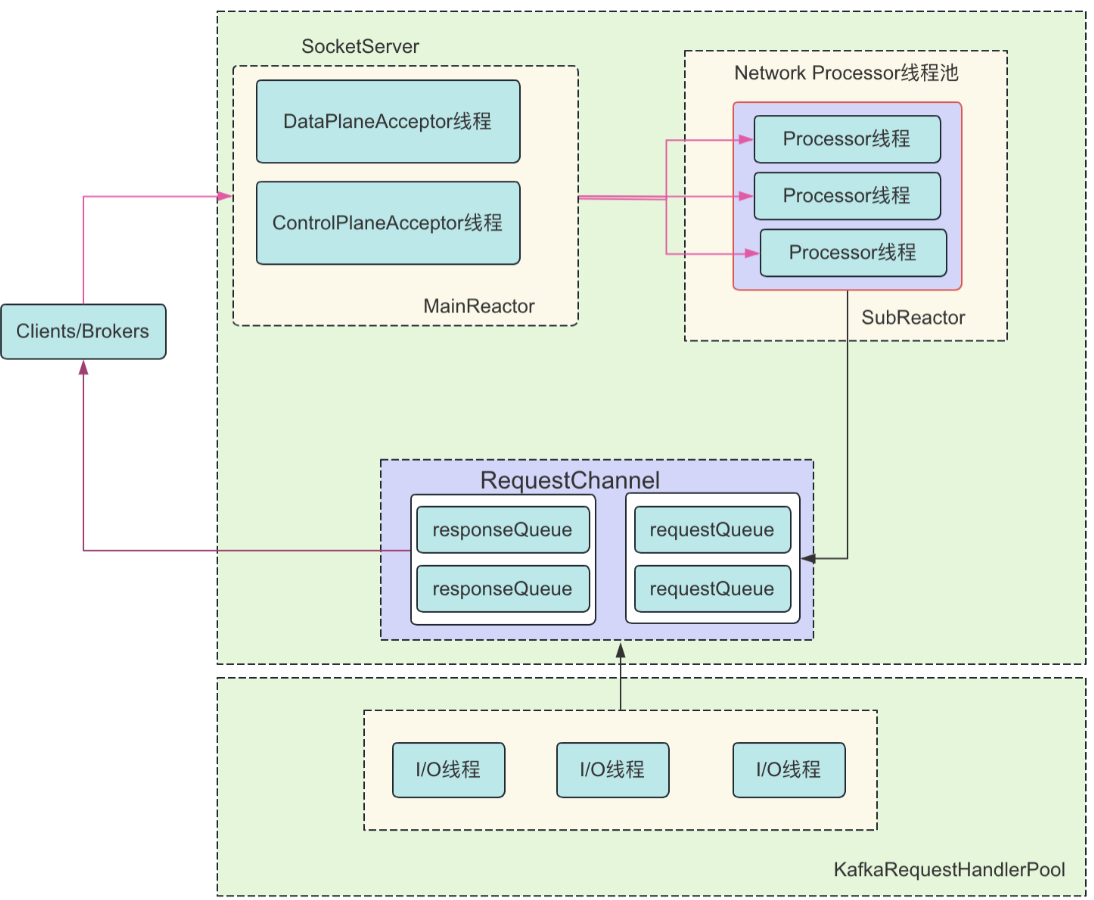
SocketServer负责处理各个Broker之间的通信channel,采用Reactor处理模型,Acceptor负责从socket接受request,Handler负责处理接收来的request,这也是Kafka中的设计亮点之一。
具体实现上,划分为data-plane和control-plane,防止数据类请求阻塞控制类请求:
// data-plane
private[network] val dataPlaneAcceptors = new ConcurrentHashMap[EndPoint, DataPlaneAcceptor]()
val dataPlaneRequestChannel = new RequestChannel(maxQueuedRequests, DataPlaneAcceptor.MetricPrefix, time, apiVersionManager.newRequestMetrics)
// control-plane
private[network] var controlPlaneAcceptorOpt: Option[ControlPlaneAcceptor] = None
val controlPlaneRequestChannelOpt: Option[RequestChannel] = config.controlPlaneListenerName.map(_ =>
new RequestChannel(20, ControlPlaneAcceptor.MetricPrefix, time, apiVersionManager.newRequestMetrics))
private[network] val processors = new ArrayBuffer[Processor]()
从上述定义可以看出control-plane的线程数只有一个,这是因为控制类的请求数量较数据类请求少。
Acceptor线程通过Selector + Channel轮询获取acceptable connection,将接收的连接信息传递给下游Processor处理,作为Runnable任务,每个endpoint指定一个acceptor。
KafkaRequestHandlerPool是请求I/O处理线程池,负责创建、维护、销毁KafkaRequestHandler,KafkaRequestHandler作为请求I/O处理线程类,负责从SocketServer的RequestChannel的请求队列中获取请求对象,并处理。
3.6. Kafka事务处理
Kafka事务主要适用于以下两种场景:
- multi-produce场景:Producer需要将多批次消息进行原子性提交。
- consume-transform-produce场景:消费上游数据后,经过处理,生产下游数据。该场景实现可以参考
kafka.examples.ExactlyOnceMessageProcessor,事务可以保证消费和生产的原子性。
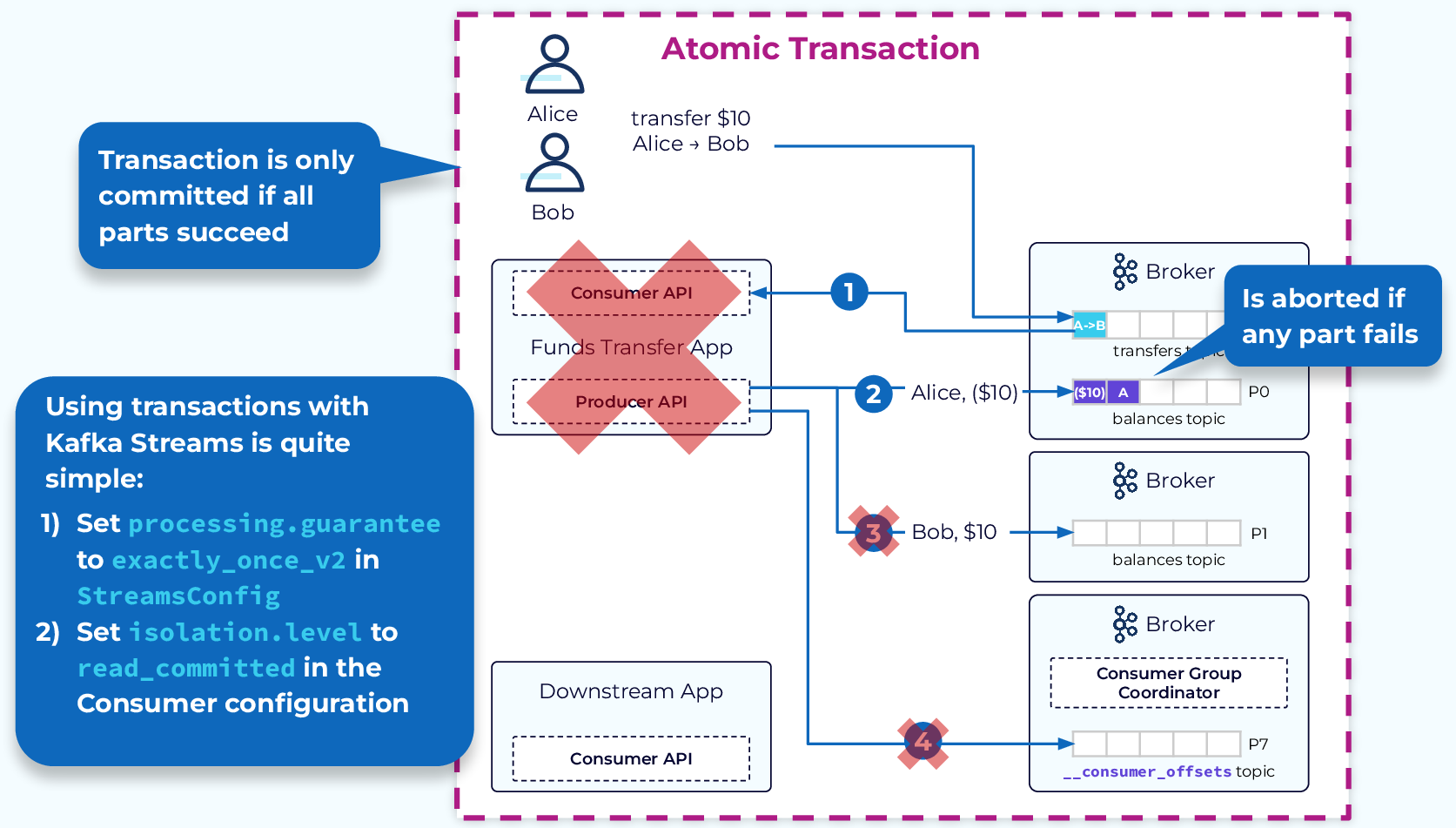
consume-transform-produce场景案例:
@Override
public void run() {
int retries = 0;
int processedRecords = 0;
long remainingRecords = Long.MAX_VALUE;
// it is recommended to have a relatively short txn timeout in order to clear pending offsets faster
int transactionTimeoutMs = 10_000;
// consumer must be in read_committed mode, which means it won't be able to read uncommitted data
boolean readCommitted = true;
try (KafkaProducer<Integer, String> producer = new Producer("processor-producer", bootstrapServers, outputTopic,
true, transactionalId, true, -1, transactionTimeoutMs, null).createKafkaProducer();
KafkaConsumer<Integer, String> consumer = new Consumer("processor-consumer", bootstrapServers, inputTopic,
"processor-group", Optional.of(groupInstanceId), readCommitted, -1, null).createKafkaConsumer()) {
// called first and once to fence zombies and abort any pending transaction
producer.initTransactions();
consumer.subscribe(singleton(inputTopic), this);
Utils.printOut("Processing new records");
while (!closed && remainingRecords > 0) {
try {
ConsumerRecords<Integer, String> records = consumer.poll(ofMillis(200));
if (!records.isEmpty()) {
// begin a new transaction session
producer.beginTransaction();
for (ConsumerRecord<Integer, String> record : records) {
// process the record and send downstream
ProducerRecord<Integer, String> newRecord =
new ProducerRecord<>(outputTopic, record.key(), record.value() + "-ok");
producer.send(newRecord);
}
// checkpoint the progress by sending offsets to group coordinator broker
// note that this API is only available for broker >= 2.5
producer.sendOffsetsToTransaction(getOffsetsToCommit(consumer), consumer.groupMetadata());
// commit the transaction including offsets
producer.commitTransaction();
processedRecords += records.count();
retries = 0;
}
} catch (AuthorizationException | UnsupportedVersionException | ProducerFencedException
| FencedInstanceIdException | OutOfOrderSequenceException | SerializationException e) {
// we can't recover from these exceptions
Utils.printErr(e.getMessage());
shutdown();
} catch (OffsetOutOfRangeException | NoOffsetForPartitionException e) {
// invalid or no offset found without auto.reset.policy
Utils.printOut("Invalid or no offset found, using latest");
consumer.seekToEnd(emptyList());
consumer.commitSync();
retries = 0;
} catch (KafkaException e) {
// abort the transaction
Utils.printOut("Aborting transaction: %s", e.getMessage());
producer.abortTransaction();
retries = maybeRetry(retries, consumer);
}
remainingRecords = getRemainingRecords(consumer);
if (remainingRecords != Long.MAX_VALUE) {
Utils.printOut("Remaining records: %d", remainingRecords);
}
}
} catch (Throwable e) {
Utils.printErr("Unhandled exception");
e.printStackTrace();
}
Utils.printOut("Processed %d records", processedRecords);
shutdown();
}
3.6.1. 客户端配置项
Producer配置项:
enable.idempotence:默认false,开启后会设置acks=all, retries=Integer.MAX_VALUE,max.inflight.requests.per.connection=1transactional.id:事务ID,用于标识事务,允许跨多个client
Consumer配置项:
isolation.level:默认值为read_uncommitted- read_uncommitted:允许消费暂未提交事务的message
- read_commited:允许消费除未提交事务以外的message
3.6.2. 事务流程
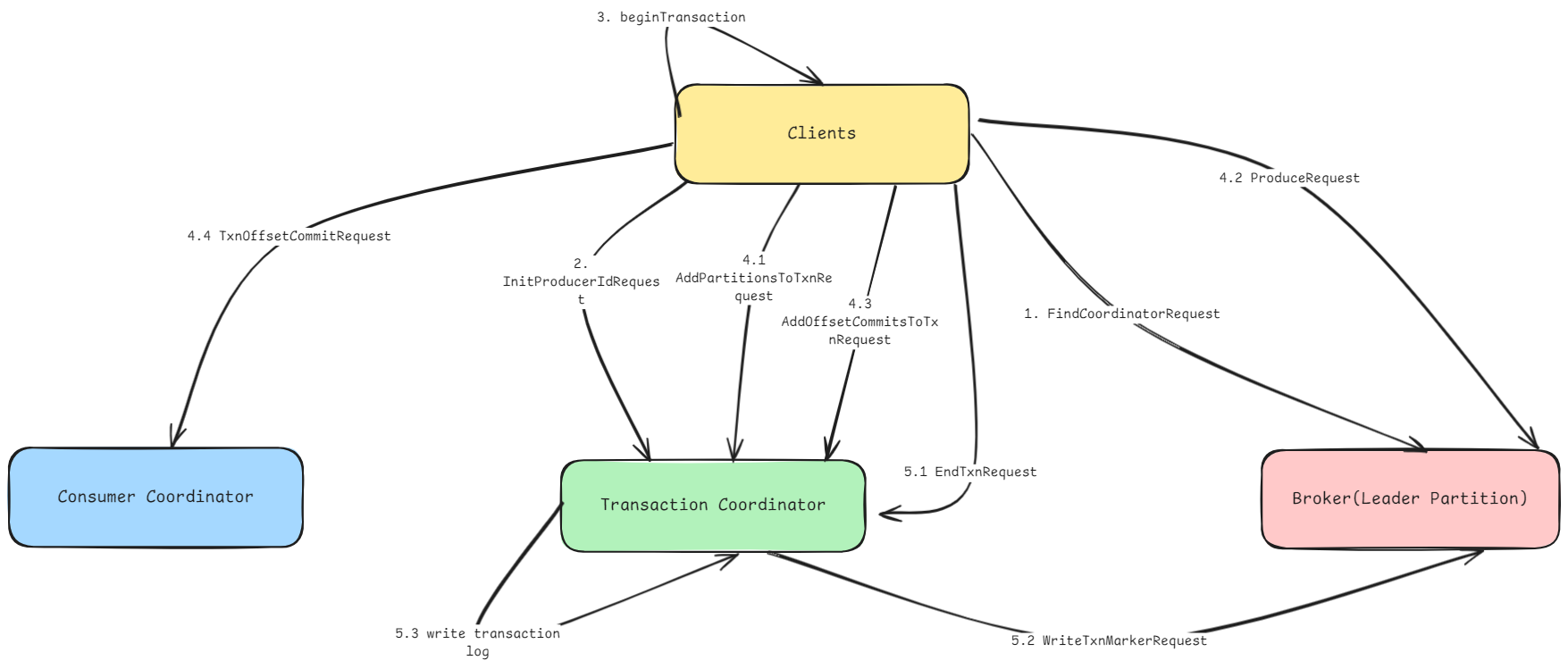
- client发送FindCoordinatorRequest请求给broker端,获取Transaction Coordinator服务地址。
- client调用initializeTransactions方法发送InitProducerIdRequest请求给Transaction Coordinator,用以获取producerId。
- client调用beginTransaction方法,开启一次事务,client本地会改变事务状态,并不会影响Transaction Coordinator服务。
- 事务过程:
- client开启事务后,当新的TopicPartition写入数据时,Producer会向Transaction Coordinator发送AddPartitionsToTxnRequest,Transaction Coordinator记录对应的事务分区
- client向TopicPartition的leader endpoint发送ProduceRequest
- client调用sendOffsetsToTransaction方法向Transaction Coordinator发送AddOffsetsToTxnRequest,TC会将对应的消费记录存储到事务日志中。
- client完成向Transaction Coordinator发送消费记录后,client将会发送TxnOffsetCommitRequest给consumer coordinator
- 事务提交 or 事务回滚
- 调用commitTransaction/abortTransaction方法,向Transaction Coordinator发送EndTxnRequest
- Transaction Coordinator向TopicPartition的leader endpoint发送WriteTxnMarkerRequest,Broker端会根据情况选择commit或rollback
- Transaction Coordinator将事务结果写入事务日志中
3.7. Coordinator && Consumer Group
3.7.1. 消费者组工作流程
Kafka采用发布订阅模式执行生产消费模式,它会按照group.id将多个consumer划分到同一个Group中,并由Broker端的Group Coordinator对topic partition做数据分发,并管理consumer的消费进度。
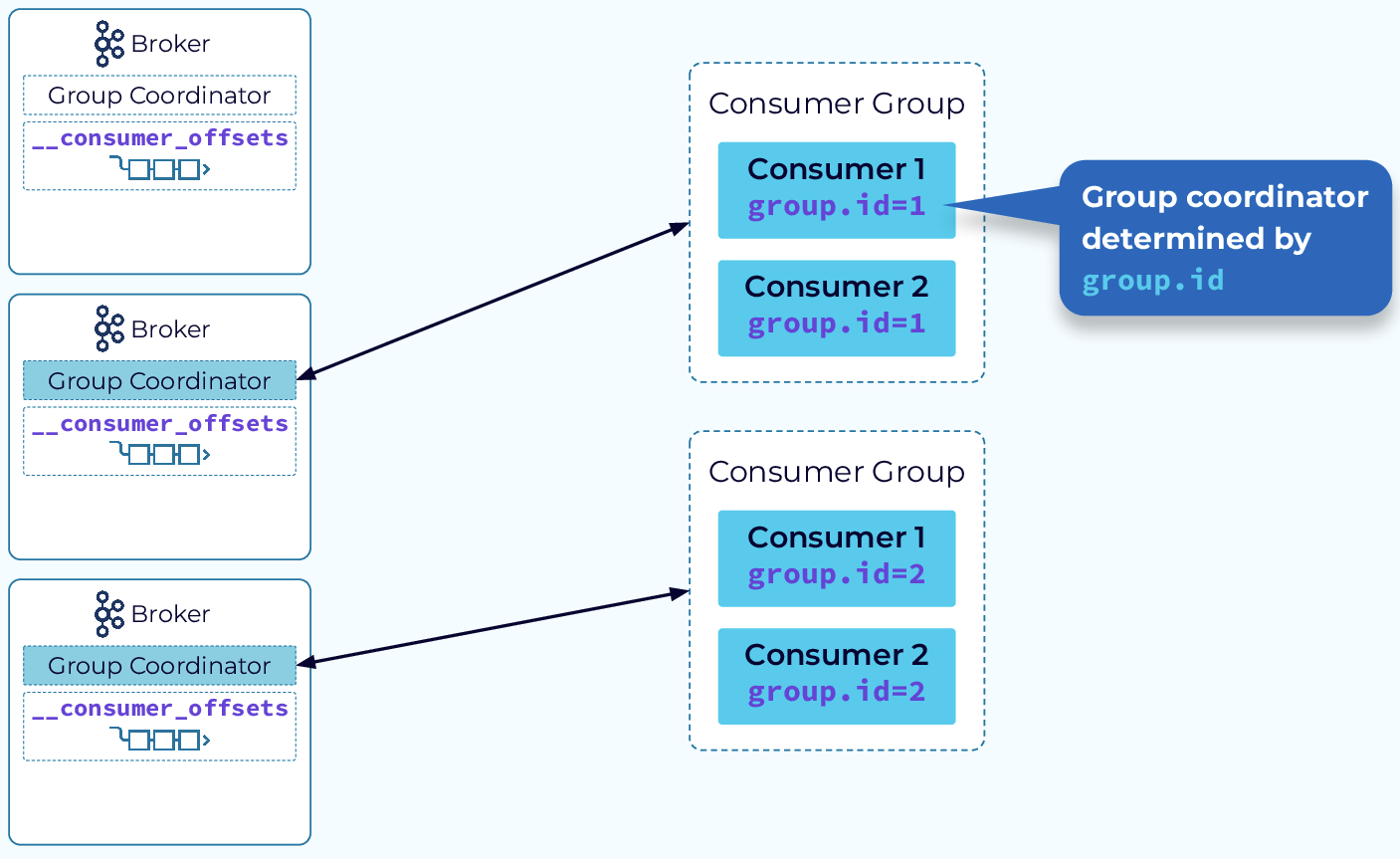
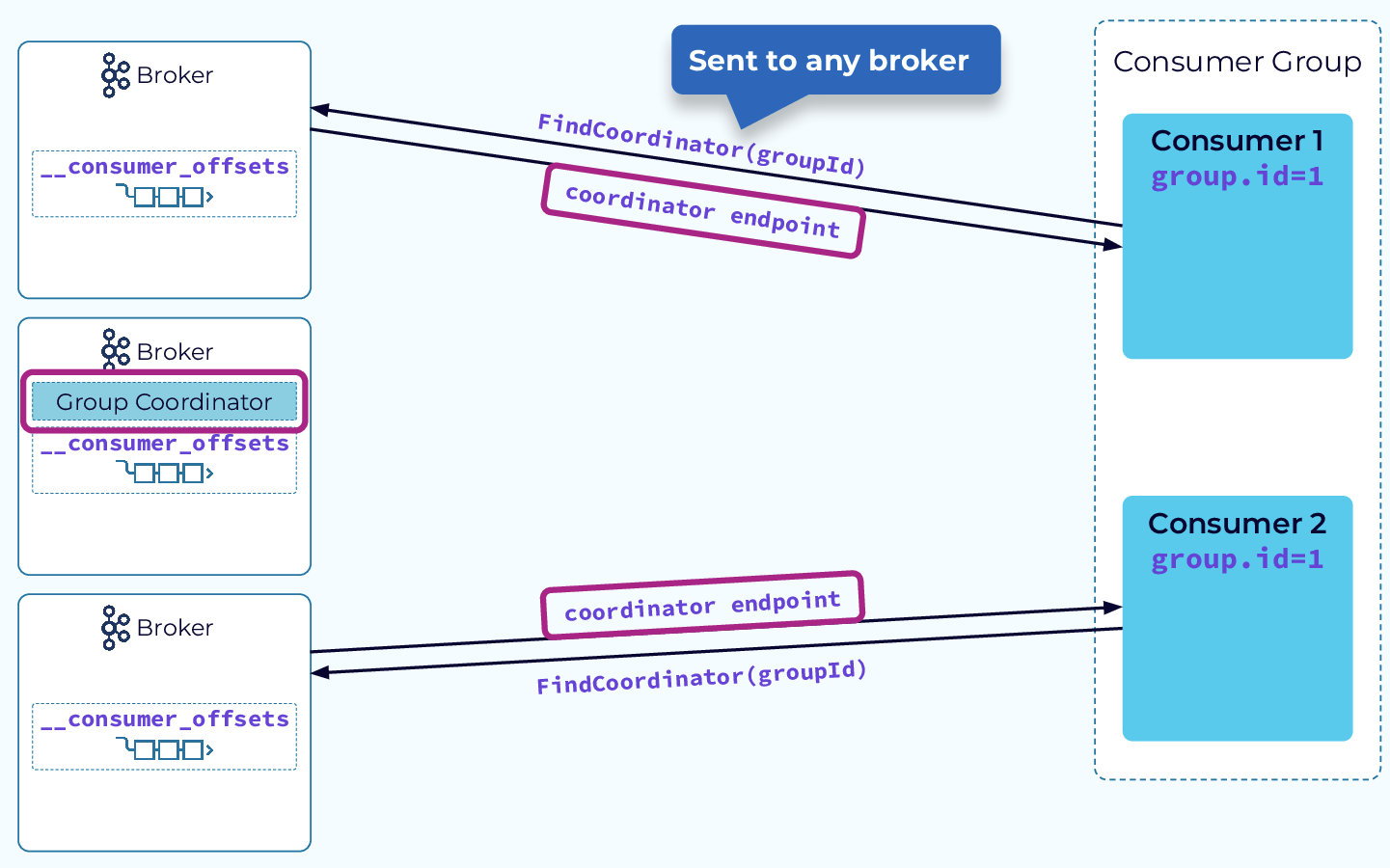
当新consumer加入Group时,会向任一Broker发送FindCoordinator请求,该Broker会将对应topicPartition的leader副本对应的endpoint返回给consumer。
consumer继续向group coordinator发送JoinGroup请求,group coordinator将会返回一个memberId(通常加入组的第一个member会成为leader),当前组所有member信息将会返回给leader consumer,并由leader consumer做实际的partition分配。
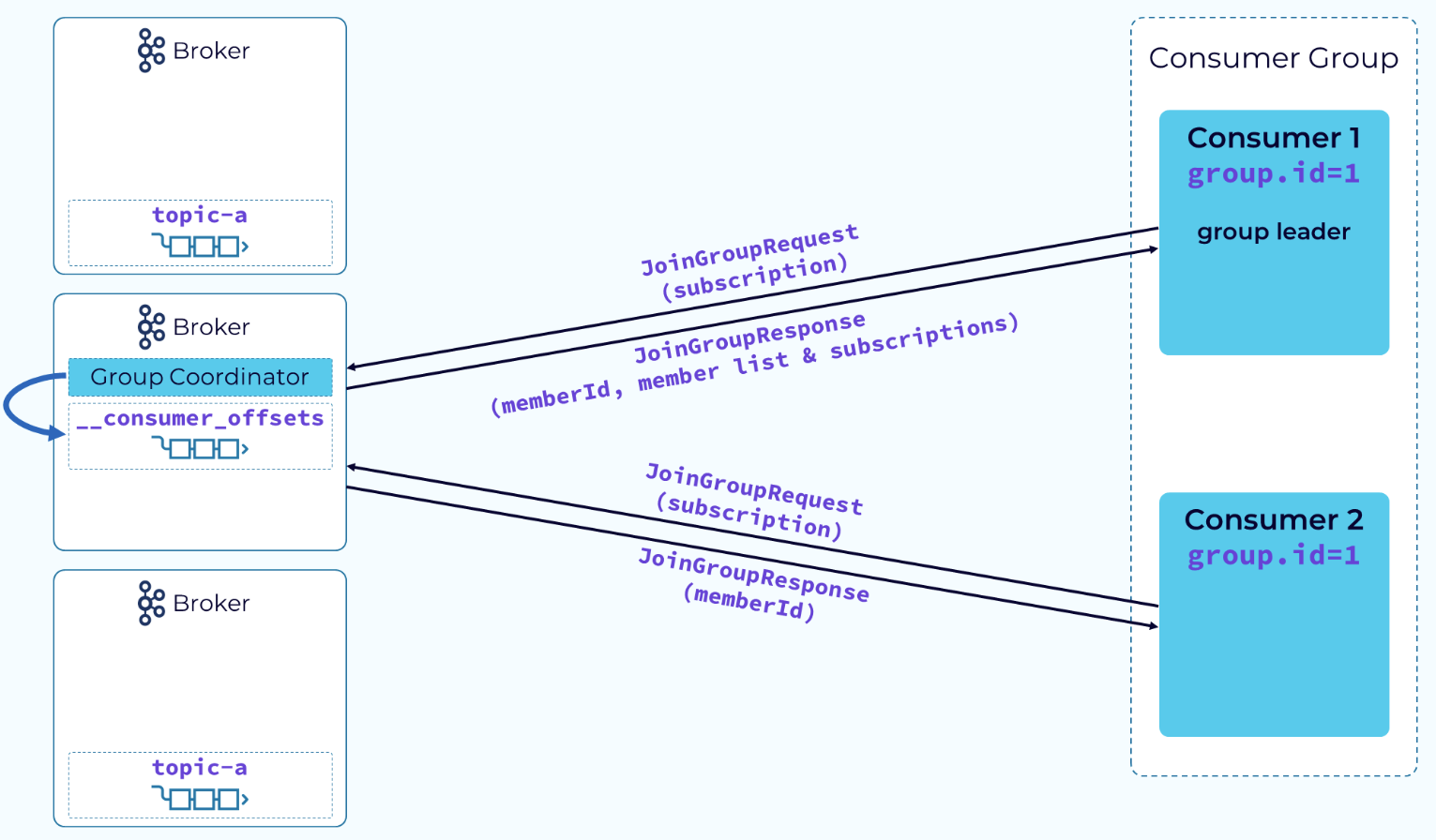
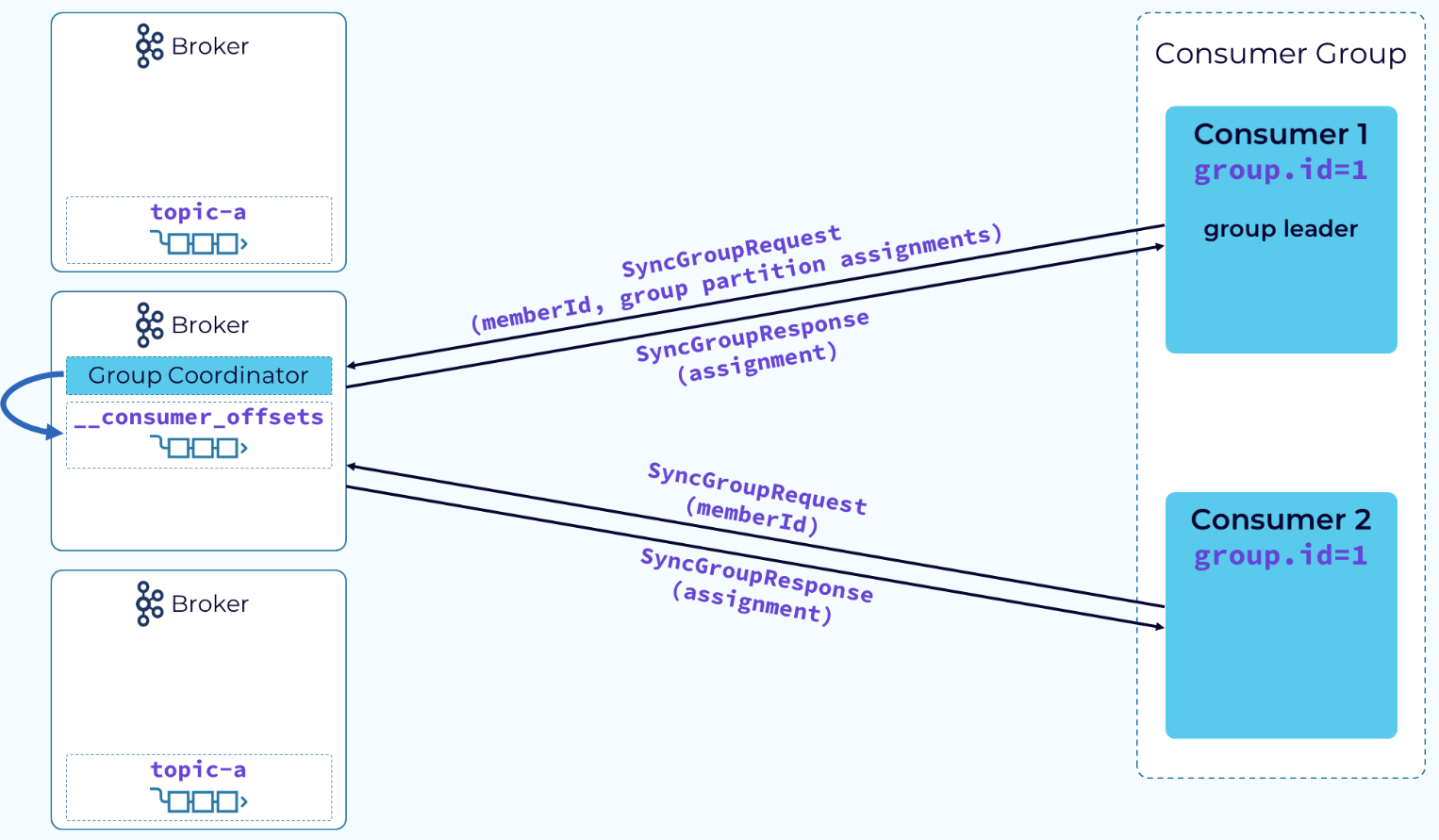
当consumer leader接收到完整的member信息和分区分配策略后,它会按照分配策略将partition分给各个consumer,当上述操作完成后,consumer leader会发送SyncGroupRequest请求给Group Coordinator,组内其他consumer同样会将leaderId包装在SyncGroupRequest中进行发送,Coordinator会将consumer leader发送的分配计划发给各个consumer。
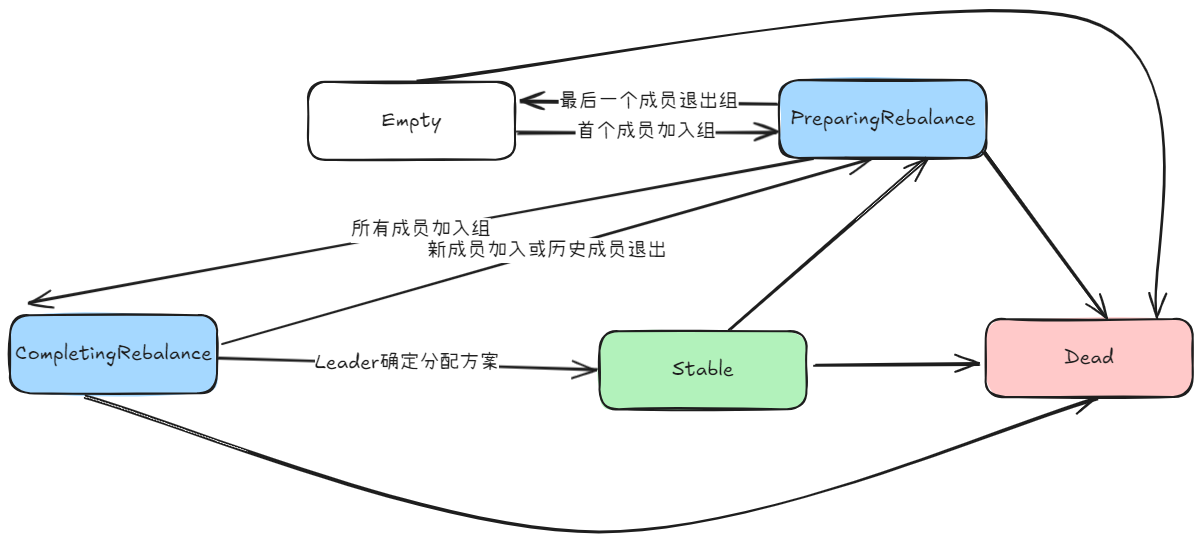
消费者组状态转换:
4. Kafka最佳实践
Kafka 客户端性能提升-优化配置与最佳实践 | AutoMQ Apache Kafka 客户端的最佳实践 - Amazon Managed Streaming for Apache Kafka 最佳实践_云消息队列 Kafka 版(Kafka)-阿里云帮助中心
5. Reference
使用 AutoMQ 实现 Kafka 大规模成本及效率优化 | 亚马逊AWS官方博客
KIP-595: A Raft Protocol for the Metadata Quorum - Apache Kafka - Apache Software Foundation
KIP-405: Kafka Tiered Storage - Apache Kafka - Apache Software Foundation
Introduction to Kafka Tiered Storage at Uber | Uber Blog
Deep dive into Apache Kafka storage internals: segments, rolling and retention
https://tech.meituan.com/2022/08/04/the-practice-of-kafka-in-the-meituan-data-platform.html
Kafka Design Overview | Confluent Documentation
深入 Kafka Core 的设计(基础理论篇) – K’s Blog