Spark入门
简介
Apache Spark是一个分布式计算系统,具备以下特点:
- 使用RDD(Resilient Distributed Datasets),提供了比MapReduce更为丰富的模型
- 基于内存计算,性能比MapReduce模型高
- 集成离线计算、实时计算、机器学习、图计算等模块
核心模块:
- Spark Core:提供Spark核心功能,是SQL、Streaming等模块实现的基础。
- Spark SQL:提供SQL进行数据查询的组件
- Spark Streaming:提供流式计算的组件
- MLlib:Spark平台的机器学习算法库
- GraphX:面向图计算的组件
Spark名词解释:
| 名称 | 含义 |
|---|---|
| Application | 指用户提交的 Spark 应用程序 |
| Job | 指 Spark 作业,是 Application 的子集,由行动算子(action)触发 |
| Stage | 指 Spark 阶段,是 Job 的子集,以 RDD 的宽依赖为界 |
| Task | 指 Spark 任务,是 Stage 的子集,Spark 中最基本的任务执行单元,对应单个线程,会被封装成 TaskDescription 对象提交到 Executor 的线程池中执行 |
| Driver | 运行用户程序main()方法并创建SparkContext的实例 |
| Cluster Manager | 集群管理器,例如Yarn、Mesos、Kubernetes等 |

Spark运行过程:
- Driver执行用户程序的main方法,并创建SparkContext,与Cluster Manager建立连接。
- Cluster Manager为用户程序分配计算资源,返回可使用的Executor列表。
- 获取Executor资源后,Spark会将用户程序代码以及依赖包,发送给Executor
- SparkContext发送task到Executor,由executor执行计算任务。
Demo
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class WordCountDemo {
private static void wordCount(String fileName) {
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JD Word Counter");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> inputFile = sparkContext.textFile(fileName);
JavaRDD<String> wordsFromFile = inputFile.flatMap(content -> Arrays.asList(content.split(" ")).iterator());
JavaPairRDD countData = wordsFromFile.mapToPair(t -> new Tuple2(t, 1)).reduceByKey((x, y) -> (int) x + (int) y);
countData.saveAsTextFile("CountData");
}
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("No files provided.");
System.exit(0);
}
wordCount(args[0]);
}
}提交应用:
bin/spark-submit \
--class com.github.l1nker4.spark.WordCountDemo \
--master local \
spark-demo-1.0-SNAPSHOT.jar data/word.txt也可以通过spark-shell的方式,提交应用:
# 需要配置JAVA_HOME
bin/spark-shell
# data/word.txt提前创建
scala> sc.textFile("data/word.txt").flatMap(_.split("\n")).map((_,1)).reduceByKey(_+_).collect
res6: Array[(String, Int)] = Array((zhangsan,2), (wangwu,1), (lisi,1))
部署方式
- local模式:单机多线程模拟Spark分布式计算,通常用于开发调试。
- Standalone模式:以master-slave模式部署Spark集群。
- master参数指定为master节点地址,例如:
spark://master:7077
- master参数指定为master节点地址,例如:
- YARN模式:集群计算资源调度由YARN管理,无需部署启动Spark集群。
- master参数指定为yarn
local模式
Web UI:http://localhost:4040/jobs/
提交应用:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.1.2.jar \
10 # 入口参数参数说明:
- 本地模式下,master取值如下:
local:只启动一个Executorlocal[N]:启动N个Executorlocal[*]:启动CPU核数相同的Executor
RDD
RDD(Resilient Distributed Datasets)代表一个不可变、可分区、支持并行计算的数据集合。
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
RDD特性:
- 弹性
- 存储:内存不足时可以和磁盘进行数据交换
- 计算:计算出错时支持重试
- 容错:数据丢失可以自动恢复
- 分片:支持重新分片
- 不可变:RDD只读,只能通过transformer生成新的RDD
- 支持并行计算:不同分区可以调度到不同节点上进行计算。
五个核心方法:
| 名称 | 含义 |
|---|---|
| getPartitions | 由子类实现,返回一个分区列表,用于执行并行计算 |
| compute | 由子类实现,是一个用于 计算每一个分区 的 函数 |
| getDependencies | 由子类实现,获取当前 RDD 的依赖关系 |
| partitioner | 由子类实现(可选),可设置分区器对数据集进行分区(仅适用于 KV 类型的 RDD) |
| getPreferredLocations | 由子类实现(可选),可在分区计算时指定 优先起始位置,有助于“移动计算”的实现 |
# 创建RDD
val array: Array[Int] = Array(1, 2, 3, 4, 5)
val rdd: RDD[Int] = sc.parallelize(array)
# 文件读取
val lines: RDD[String] = sc.textFile("data/my.txt")RDD Partition
RDD Partition是数据源的部分片段,由InputFormat实现类按一定规则切分数据集之后的结果
RDD算子
转换算子(transformations)
转换算子会基于已有的RDD,按照一定规则创建新的RDD,仅记录RDD转换逻辑,不会触发计算。
| 操作 | 含义 |
|---|---|
| filter(func) | 筛选出满足条件的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数 func 中,返回一个新的数据集,每个输入元素会映射到 1 个输出结果 |
| flatMap(func) | 与 map 相似,但每个输入元素都可以映射到 0 或多个输出结果 |
| mapPartitions(func) | 与 map 相似,但是传递给函数 func 的是每个分区数据集对应的迭代器 |
| distinct(func) | 对原数据集进行去重,并返回新的数据集 |
| groupByKey([numPartitions]) | 应用于 (K, V) 形式的数据集,返回一个新的 (K, Iterable |
| reduceByKey(func, [numPartitions]) | 应用于 (K, V) 形式的数据集,返回一个新的 (K, V) 形式的数据集,新数据集中的 V 是原有数据集中每个 K 对应的 V 传递到 func 中进行聚合后的结果 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | 应用于 (K, V) 形式的数据集,返回一个新的 (K, U) 形式的数据集,新数据集中的 U 是原有数据集中每个 K 对应的 V 传递到 seqOp 与 combOp 的联合函数且与 zeroValue 聚合后的结果 |
| sortByKey([ascending], [numPartitions]) | 应用于 (K, V) 形式的数据集,返回一个根据 K 排序的数据集,K 按升序或降序排序由 ascending 指定 |
| union(func) | 将两个数据集中的元素合并到一个新的数据集 |
| join(func) | 表示内连接,对于给定的两个形式分别为 (K, V) 和 (K, W) 的数据集,只有在两个数据集中都存在的 K 才会被输出,最终得到一个 (K, (V, W)) 类型的数据集 |
| repartition(numPartitions) | 对数据集进行重分区,新的分区数由 numPartitions 指定,包含shuffle操作,扩大/缩小分区都可用,性能较coaleace差 |
| coaleace(numPartitions) | 对数据集进行重分区,新的分区数由 numPartitions 指定,不包含shuffle操作,缩小分区可用coaleace |
行动算子(actions)
不会返回新的RDD,但是会触发任务执行,算子执行后,会向Spark发起job,Spark按照前置转换算子生成DAG并执行。
| 操作 | 含义 |
|---|---|
| count() | 返回数据集中的元素个数 |
| countByKey() | 仅适用于 (K, V) 形式的数据集,以 (K, Int) 形式的 Map 返回每个 K 的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前 n 个元素 |
| reduce(func) | 通过函数 _func_(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数 func 中运行 |
| saveAsTextFile(path) | 将数据集以文本格式写到本地磁盘或 HDFS 的指定目录下 |
| saveAsSequenceFile(path) | 将数据集以 SequenceFile 格式写到本地磁盘或 HDFS 的指定目录下,仅适用于 (K, V) 形式且 K 和 V 均实现了 Hadoop Writable 接口的数据集 |
| saveAsObjectFile(path) | 将数据集序列化成对象保存至本地磁盘或 HDFS 的指定目录下 |
RDD依赖关系
转换算子生成的新RDD,与原始RDD存在依赖关系,代码层面使用Dependency关联。
依赖类型:
- 宽依赖:父RDD每个分区对应子RDD的多个分区,通常存在于groupByKey、reduceByKey等操作,需要对RDD分区做shuffle。
- ShuffleDependency
- 窄依赖:父RDD的每个分区,最多被子RDD的一个分区使用。通常存在于map、filter、union等操作,一个输入分区对应一个输出分区。
- OneToOneDependency、RangeDependency
部分RDD数据丢失时,可以通过依赖关系重新计算,进而恢复丢失数据的分区。
RDD持久化
Spark会将RDD持久化到磁盘,当actions算子需要使用时,从磁盘读取,避免重新计算。
可以使用persist()方法来指定持久化。
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 将 RDD 以反序列化 Java 对象的形式存储在 JVM 中,如果大小超过可用内存,则超出部分不会缓存,需重新计算 |
| MEMORY_AND_DISK | 将 RDD 以反序列化 Java 对象的形式存储在 JVM 中,如果大小超过可用内存,则超出部分会存在在磁盘上,当需要时从磁盘读取 |
| DISK_ONLY | 将所有 RDD 分区存储到磁盘上 |
| MEMORY_ONLY_SER | 将 RDD 以序列化 Java 对象的形式存储在 JVM 中,具有更好的空间利用率,但是需要占用更多的 CPU 资源 |
| MEMORY_AND_DISK_SER | 将 RDD 以序列化 Java 对象的形式存储在 JVM 中,如果大小超过可用内存,则超出部分会存在在磁盘上,无需重新计算 |
| MEMORY_ONLY_2 | 与 MEMORY_ONLY 级别相同,存在副本 |
| MEMORY_AND_DISK_2 | 与 MEMORY_AND_DISK 级别相同,存在副本 |
RDD Checkpoint
RDD Checkpoint是一种容错保障机制,由checkpoint()触发,主要执行:
- 重新计算调用了
checkpoint()的RDD,并将结果保存到存储系统,可以通过sc.setCheckpointDir("checkpoint")修改存储地址 - 切断原有的依赖血缘关系
与持久化有所区别:
| 区别项 | RDD 持久化 | RDD 检查点 |
|---|---|---|
| 生命周期 | 应用结束便删除 | 永久保存 |
| 血缘关系 | 不切断 | 切断 |
| 使用场景 | 支持在同一个应用中复用计算结果 | 支持在多个应用中复用计算结果 |
checkpoint在任务执行结束后触发:
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
// ...
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
**rdd.doCheckpoint()**
}共享变量
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
var sum: Int = 0
rdd.foreach(num => {
sum += num
})
println("sum => " + sum)上述代码提交到Spark执行,sum最终结果为0,这是因为计算逻辑是分发到Executor执行的,Executor将计算结果返回给Driver时,不会将非RDD内部数据的普通变量返回,也就是sum并没有参与计算。
为了解决上述问题,Spark引入了累加器和广播变量。
累加器(Accumulators)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val sumAccumulator: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(num => {
sumAccumulator.add(num)
})
println("sum => " + sumAccumulator.value)广播变量
多个Task需要共享同一个大型变量时,可以使用广播变量优化。广播变量会通过Driver分发到每一个Executor中。
// 创建单词列表list
val list: List[String] = List("Apache", "Spark")
// 创建广播变量bc
val bc = sc.broadcast(list)Spark调度模块
| 关键步骤 | 所在进程 | 核心组件 |
|---|---|---|
| 将DAG拆分为不同的Stages,根据Stages创建分布式任务Tasks和任务组TaskSets | Driver | DAGScheduler |
| 获取集群内可用计算资源 | Driver | SchedulerBackend |
| 根据调度规则决定任务优先级,完成任务调度 | Driver | TaskScheduler |
| 依次将分布式任务发送到Executors | Driver | SchedulerBackend |
| 执行收到的分布式任务 | Executors | ExecutorBackend |
内存管理
Spark Executor会将内存划分成四个区域:
- Reserved Memory:固定为300MB,Spark预留空间,用于存储Spark内部对象,
- User Memory:存储程序自定义的数据对象。
- Execution Memory:用于执行任务计算,包括数据转换、过滤、排序、聚合等。
- Storage Memory:用于缓存分布式数据集,比如RDD Cache(持久化内存),广播变量等。
Execution Memory和Storage Memory可以相互抢占空间(对方内存有空闲即可),若被抢占方有内存需求时,需要归还。Execution Memory抢占的空间需要等分布式任务执行完毕后才能归还。
内存配置项

- spark.executor.memory(绝对值):指定了Executor进程的JVM堆内存大小
- spark.memory.fraction(比例):Execution Memory和Storage Memory两部分区域
- spark.memory.storageFraction(比例):区分Execution Memory和Storage Memory的初始大小
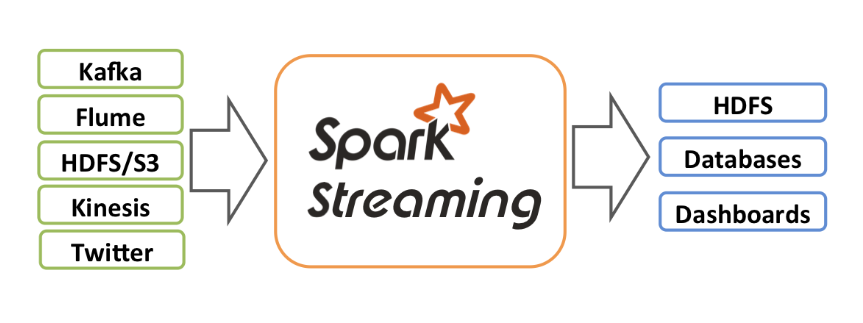
Spark Streaming
Spark Streaming是基于Spark Core实现的流式计算框架。
从实现上来看,并不是真正的流式计算,而是将数据包装成一批数据(Mirco Batch),从而达到类似流式计算的效果。
object WordCountStream {
def main(args: Array[String]): Unit = {
// 1. 设置运行模式为 local,线程数为 3
val conf: SparkConf = new SparkConf().setMaster("local[3]").setAppName("Word Count Streaming App")
// 2. 创建批次周期为 10s 的 StreamingContext
val ssc: StreamingContext = new StreamingContext(conf, Seconds(10))
// 3. 创建来自于本地 9999 端口的 Dtream 对象
val inputStream: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
// 4. 定义 DStream 转换算子
val wcStream: DStream[(String, Int)] = inputStream
.flatMap(_.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
// 5. 定义 DStream 输出算子
wcStream.print()
// 6. 启动计算作业
ssc.start()
// 7. 进行阻塞,防止 Driver 进程退出
ssc.awaitTermination()
}
}