OSDI'10 《Finding a needle in Haystack Facebook’s photo storage》
业务量级
FaceBook存储超过2600亿张图片,20PB,一周存储10亿张,峰值每秒100W图片。一次性写、不修改、很少删除的图片数据。
原始设计的挑战
访问webserver,获取图片URL,先去CDN获取,cache hit则返回,miss则去Storage加载到CDN再返回。
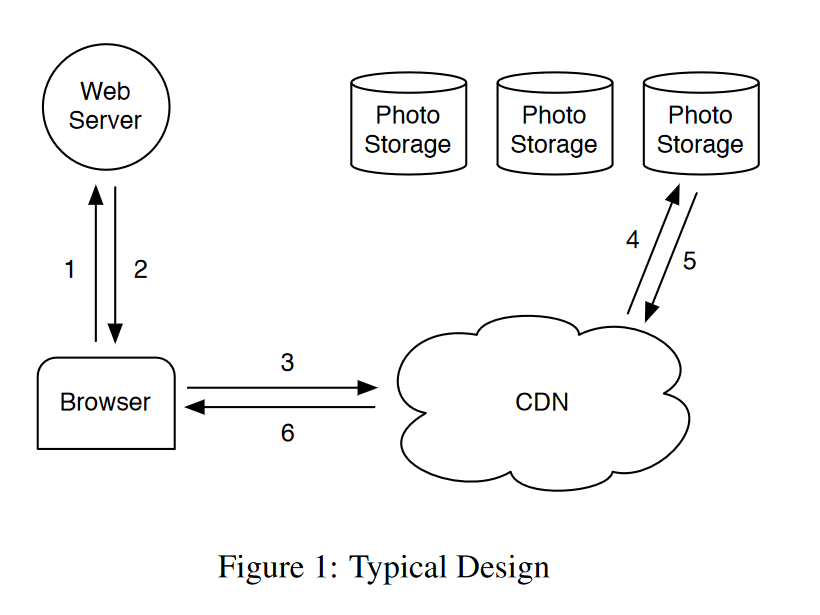
当文件存储NAS的文件夹存储数千个文件时,请求单个图片的请求会产生多于10次的磁盘IO,即使文件夹内文件数量下降到几百时,还是会产生三次磁盘IO。
可以看出,原始架构的性能瓶颈:读操作存在多次磁盘IO。
传统POSIX filesystem缺点:文件元信息,例如权限等信息占用较多存储成本。对于巨量数据的情况,成本极大,对于NAS,一个文件读写需要三次磁盘IO:
- 根据filename获取inode number
- 读取指定inode
- 读取文件信息本身
设计目标
Haystack结构实现的四个目标:
- 高吞吐量与低延迟:所有metadata都存储在内存,最多执行一次磁盘IO
- 容错:异地容灾
- 低成本
- 简单
新设计
Haystack主要解决上述架构的瓶颈问题:多次磁盘IO,关键方法:将多个图片存储为单个大文件,由此仅需要保存大文件的文件元信息。
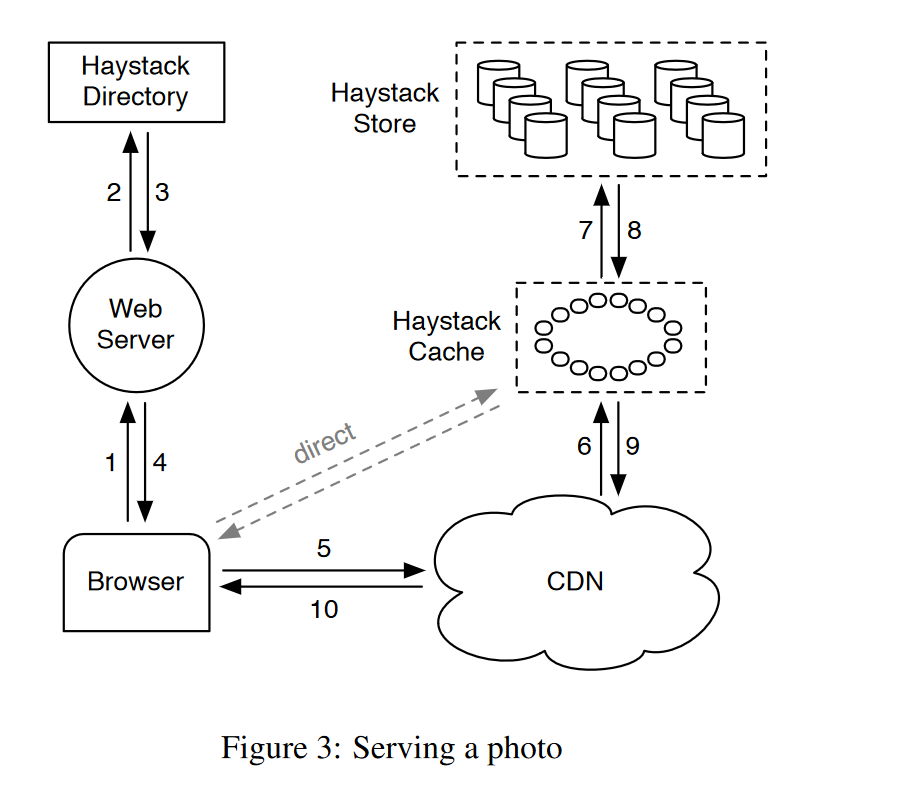
Haystack架构包括以下三部分:
- Haystack Store:真正存储文件的组件,管理文件系统元信息。使用物理volume进行管理,可以将不同主机上的某些物理volume组成一个逻辑volume,这样就可以产生多份副本,进行容错或分流。
- Haystack Directory:管理逻辑到物理volume的映射关系,以及一些应用元信息,例如图片到逻辑volume的映射,逻辑volume的空闲空间等信息。
- Haystack Cache:内部缓存CDN,减少对外部CDN的依赖。
浏览器从Haystack Directory组件获取到的URL如下:
http://〈CDN〉/〈Cache〉/〈Machine id〉/〈Logical volume, Photo〉CDN,Haystack Cache层如果hit cache就返回,否则去掉该层地址,请求转发到下一层。
Haystack Directory
四个功能:
- 逻辑volume到物理volume的映射。
- 跨逻辑卷读写的负载均衡能力。
- 决定一个请求是由CDN处理还是Cache处理。
- 检查逻辑卷是否因为操作原因或达到存储容量导致read-only
Haystack Cache
从浏览器或CDN接收HTTP请求。该组件使用图片id定位数据,将其组织成了分布式hash table,如果cache miss,则去Haystack Store服务器获取图片信息。
对图片进行cache的两个必要条件:
- 请求直接来自浏览器而非CDN
- 图片从可写服务器获取的
Haystack Store
每台存储服务器都维护了多个逻辑volume,每个volume都可以理解为一个大文件(100
GB ),文件名为/hay/haystack_
具体的物理结构如下图所示:
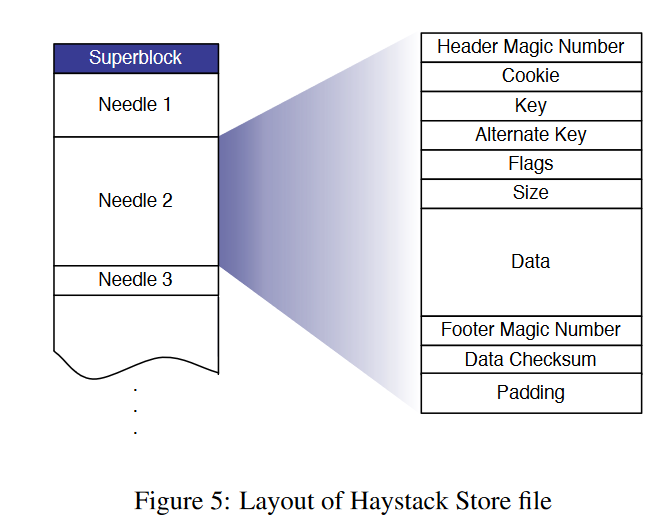
每台存储服务器代表着一个物理卷,同时也称为superblock,其中包括多个needle,每个needle存储着图片元信息和图片数据。

Read
来自Cache服务器的读请求会有以下参数:逻辑volume id、key、alternate key、cookie,Store服务器首先从内存中查找对应元信息,然后读取图片数据,使用checksum进行校验后返回。
Write
写请求会包括以下参数:逻辑volume id、key、alternate key、cookie、data,Store服务器将数据组装成needle结构并追加到volume file中。如果(key, alternate key)唯一二元组存在重复问题,有两种情况:
- 不同逻辑volume:Directory更新图片到逻辑volume的映射关系
- 相同逻辑volume:通过offset区分,最新版本的数据为offset大的needle
Delete
同步设置内存和volume file中对应元信息的delFlag,如果请求到被删除的图片信息,抛出异常。在定期compact时,会清理被删除的数据。
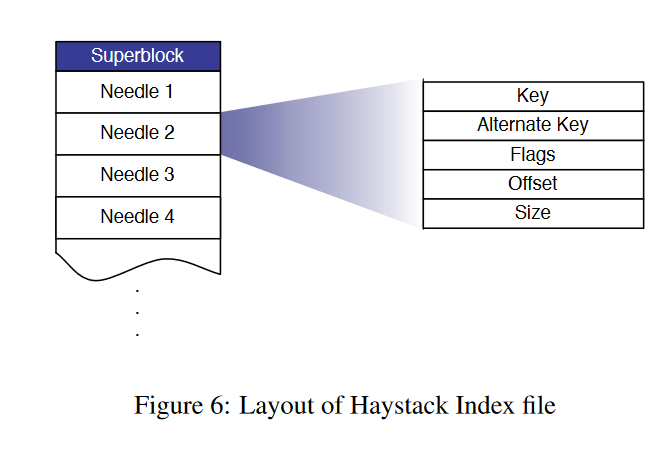
Index File
系统宕机后,重建内存中的索引是较为耗时的操作,因此使用index file存储了内存的映射关系,以便机器重启时能更快的重建映射关系。Store服务器每个volume都会维护一个index file。
当前存在以下问题: 1. 新文件写入到磁盘volume和内存映射后,还没写入到index file就宕机。 2. 删除文件后,同步设置volume和内存中的delflag后,还没写入index file就宕机。
解法: 1. 读取index file时,将needle中不符合索引记录的,构建成新记录并追加到index file末尾(Q:为什么读取needles?) 2. 每次读取文件时,检查删除标记,并同步到内存和index file。
文件系统
Haystack并不需要使用很多内存来支持大文件的随机IO,因此Store服务器都使用XFS,它有两个有点: 1. 对于多个相邻的大文件的块映射可以足够小到存储到内存中。 2. XFS提供了搞笑的文件预分配、减少了碎片并控制了块映射的增长。
不能保证每一个读请求都只有一次磁盘IO,因为存在数据跨界的情况。
错误恢复
Store服务器避免不了硬件故障,应对方法主要是:定期检测、适时恢复。
- 定期检测:启动一个后台任务(称为pitchfork),定期检查每台Store服务器的联通情况和volume file的可用性,如果检查出问题,该任务会标记Store服务器所有volume只读。
- 恢复:存在问题后会尽快修复,无法修复的使用bulk sync从备份节点全量同步数据过来。
优化
Compaction
compacttion是一个在线操作,实现思路:生成一个新文件,将needle逐个拷贝到新文件,其中会跳过被删除和重复的needle,一旦完成,它会阻塞任意打到该volume file的请求并原子性交换文件和内存映射关系。
实际业务中,大约25%的图片被删除。
节约内存
当前系统的flag字段仅用作于删除标志,设置删除标记的同时,可以将offset设为0。同时将cookie从内存中删除,改为从磁盘中读取(needle header),上述两个优化点节约了20%的内存。
批量上传
磁盘的顺序写性能优于随机写,同时用户都是同时上传一批图片,该应用场景也契合于磁盘特点。