Zookeeper论文阅读笔记
摘要
Zookeeper是一个带有事件驱动的分布式系统缓存,提供了强大的分布式协调能力,结合了组播消息、分布式锁等内容。
Zookeeper提供了高性能服务,保证了对客户端请求FIFO顺序执行和线性化写,在给出了在2:1到100:1的读/写比率下,ZooKeeper 每秒可以处理数万到数十万个事务。
1.简介
分布式系统需要不同形式的协调程序,配置是协调的最基本形式。
Zookeeper的API设计,移除了锁等阻塞原语来提高性能,使用wait-free的数据结构来实现对应的功能。
注:wait-free:他保证任何线程都能在有限的过程内执行完成。
Zookeeper可以用集群模式中的副本来实现高可用性和高性能,是西安了基于领导者的原子广播协议(ZAB:Zookeeper Atomic Broadcast),Zookeeper应用的主要负载是读操作,所以需要保证读吞吐量的可扩展。
Zookeeper使用watch机制使得客户端不需要直接管理客户端缓存,对于一个给定的数据对象,客户端可以监视到更新动作,当有更新的时候收到通知消息。而Chubby 直接操作客户端缓存,会阻塞更新直到所有的客户端缓存都被改变。如果任何客户端速度较慢或者故障,更新都会延迟。
本文主要讨论ZooKeeper的设计和实现,包括:
- 协调内核:提出了一种可用于分布式系统的无等待、具有宽松的一致性保证的协调服务。
- 协调示例
- 协调相关的思路
2.Zookeeper服务
2.1 概述
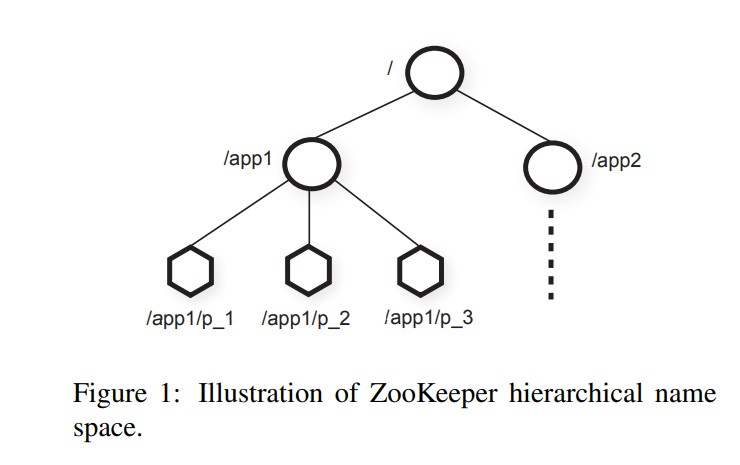
Zookeeper将客户端抽象为znodes,并将其构造为树形结构,客户端可以创建两种znode:
- 普通:client通过创建和删除显式操作普通节点。
- 临时:创建后可以显式删除或者系统在会话结束后自动删除。
watch机制使得客户端无须轮询就可以接收到状态变换的通知信息。与一个会话关联的 watches 只会触发一次;一旦触发或者会话结束,就会被注销。
设计znode不是用来保存通用数据,而是用来映射客户端应用的抽象,主要是对于协调用途的元数据。
2.2 客户端API
- create(path, data, flags):使用 path 名称创建一个 znode 节点,保存 data,返回新创建的 znode 名称。 flags 用于创建普通或者临时节点,也可以设置顺序标识。
- delete(path, version): 删除指定 path 和 version 的 znode 节点。
- exists(path, watch): 如果指定 path 的 znode 存在则返回真,如果不存在则返回假。watch 标识用于在 znode 上设置监视器。
- getData(path, watch):
返回数据和元数据,如版本信息。watch 标识与
exists()的 watch 标识一样,但如果 znode 不存在则不会设置监视器。 - setData(path, data, version): 根据 path 和 version 将数据写入到 znode。
- getChildren(path, watch): 返回 znode 所有子节点的名称集合。
- sync(path): 在操作开始时,等待所有挂起的更新操作发送到客户端连接的服务器。path 当前未使用。
所有API都提供同步异步两个版本,无论同步异步,都会保证执行顺序按照FIFO进行。
2.3 保证
Zookeeper有两个顺序保证:
- 线性化写入:所有更新请求都是序列化并且遵循优先级。
- 这里的线性化称为异步线性化,一个客户端有多个未完成的操作,因此需要FIFO顺序。
- FIFO客户端顺序:对于客户端的所有请求,都会按客户端发送的顺序执行。
两个活性和持久性保证:
- Zookeeper的大部分节点存活,则服务可用
- Zookeeper响应了更新请求,只要多数节点恢复,更新则可以持久化
2.4 原语的例子
配置管理
配置信息存放在znode中,进程读取znode的值,将watch设置为true。
信息汇合
系统的最终的配置信息并不能提前知道。
主进程可创建一个znode来存储配置信息,工作进程读取znode,并设置watch为true。
群组关系
利用临时节点以及树形结构,可以动态管理群组成员的关系。
锁
Zookeeper可用于实现分布式锁。
3.Zookeeper应用
- 爬虫应用FS:存储爬虫服务的配置信息,选举主进程。
- Katta(分布式索引):注册节点,保存群组关系,提供领导者选举和配置管理服务。
- YMB(分布式发布订阅系统):配置管理、故障探测、群组关系
4.Zookeeper实现
Zookeeper的组件如下图所示:
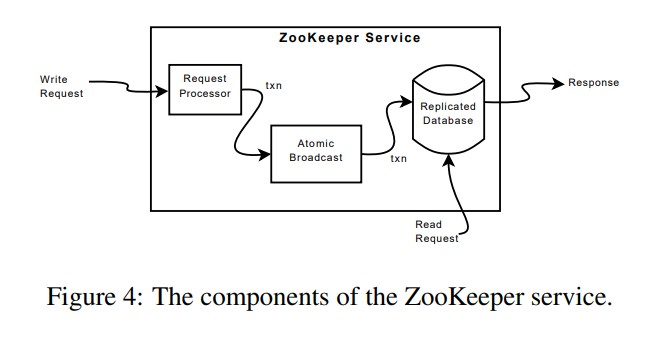
复制的数据库是一个内存级数据库,使用WAL日志保证一致性,并且会生成快照进行持久化。对于写请求只有leader进行处理,并且使用ZAB协议进行一致性的保证,读请求所有节点都可以处理。
4.1 请求处理器
由于事务是幂等的,当leader收到写请求后,会计算写入后的状态,并将请求转化为一个包含这个新状态的entry。
例如setData的写操作,执行成功则会生成包含新数据、版本号、时间戳的setDataTXN,执行异常,则会生成errorTXN。
4.2 ZAB
所有的写请求都会被转发到leader节点进行处理,并使用ZAB协议广播更新信息,ZAB默认采用简单的多数服从原则,大部分服务器(2n+1,可以允许n个节点故障)正常时,Zookeeper正常工作。
- ZAB是强一致性的共识算法,是Paxos的一种
- 提供了高性能,使用TCP传输,消息顺序由网络保证
- ZAB按顺序发送所有消息。
4.3 复制数据库
每个节点在内存中都有一份Zookeeper状态的拷贝,为了防止节点故障恢复影响效率,故采用周期性的快照来提高恢复效率。使用DFS遍历节点树,读取znode数据和元数据并写入磁盘。在生成快照过程中可能存在状态变化,但只要顺序写入状态变更信息,由于消息幂等,可以保证数据一致性。
4.4 C/S交互
读请求:
- 请求在各个节点的本地执行
- 每个读请求附加上zxid,等于最后一个服务端见到的事务。
写请求:
- 将更新相关的通知发出去,并将对应的watch清空。
- 写请求不会和任何请求并发执行,保证了数据的严格一致
- 通知在各个节点本地执行