使用Prometheus + Grafana 构建监控可视化系统
监控系统简介
业务监控系统通常包含以下一些组件:
- 采集:信息源来自log、metrics等。
- 可以通过定期外围探测、AOP手动织入、字节码自动织入
- 上报:通过http或者tcp
- 聚合
- 存储
- 可视化、告警
业务监控系统解决了什么问题?
趋势分析:收集长期监控数据,对监控指标进行趋势分析,例如:分析磁盘空间增长率,预测何时进行磁盘扩容。
对照分析:分析不同版本在运行时资源使用情况差异。
告警:当服务出现故障时,监控可以迅速反应并告警。
故障分析与定位:故障发生时,可以通过分析历史数据去定位问题。
数据可视化:通过采集的数据,生成可视化仪表盘。
对于运维:监控CPU、内存、硬盘等使用情况。
对于研发:监控某个异常指标的变化情况,来保证业务的稳定性。
对于产品或运营:关注产品层面:某个活动参加人数的增长情况等
监控系统分为以下五层:
- 端监控:对网站、APP、小程序等进行端监控,采集页面打开速度、稳定性、外部服务调用成功率等参数。
- 业务层监控:对业务模块进行监控,采集QPS、DAU、业务接口访问数量等。
- 应用层监控:对分布式应用进行管理和监控
- 中间件监控:对中间件进行监控,主要判断组件是否存活。
- 系统层监控:对操作系统监控,主要包括:CPU、磁盘I/O、网络连接等参数。
Prometheus简介
当前监控系统主要有集中式日志解决方案(ELK)和时序数据库解决方案。监控三要素如下:
- Metrics:可聚合,带有时间戳的数据。
- Logging:离散日志,分为有结构和无结构。
- Tracing:请求域内的调用链。
Prometheus架构
Prometheus的架构图如下所示:
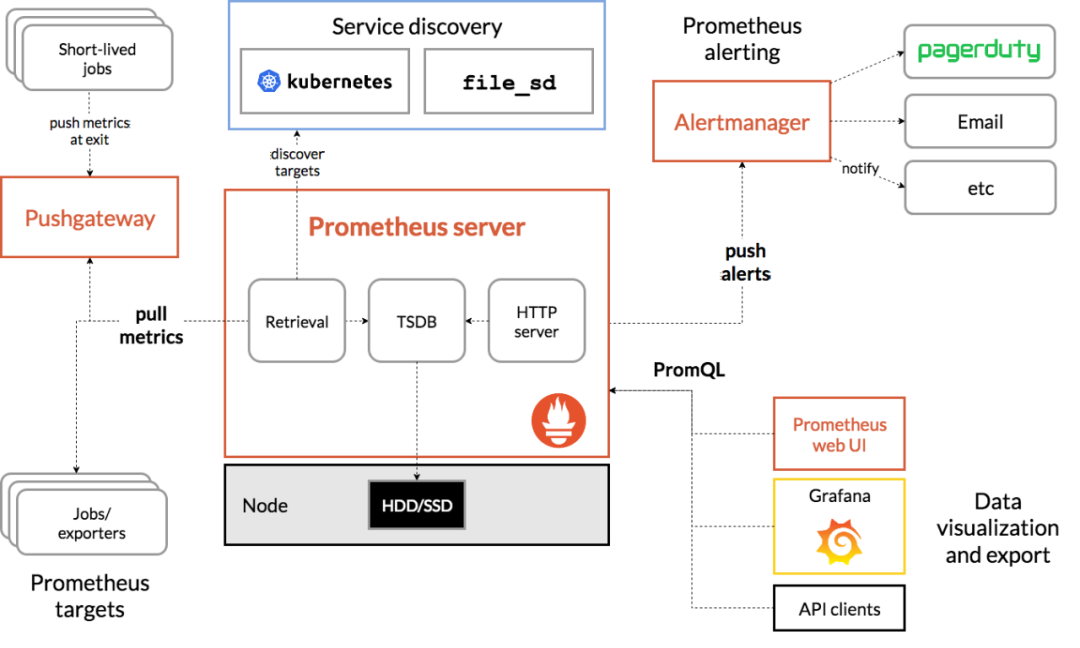
其中各组件功能如下:
- Prometheus
Server:核心部分,负责实现对监控数据的获取,存储以及查询。
- Retrieval:定时去配置文件中指定target抓取指标数据。(Pull)
- TSDB:Prometheus内置了时序数据库,存储抓取的指标数据。
- HTTP Server:提供了HTTP接口进行操作。
- Jobs/exporters:exporter将监控数据通过HTTP服务的形式暴露给Prometheus Server,其定时进行Pull。
- Pushgateway:临时性的Job可以将监控数据push到这,Prometheus从Pushgateway拉取数据。
- AlertManager:告警处理中心。Prometheus支持基于PromQL创建告警规则。
- Data Visualization:数据可视化,其中Prometheus自带的web UI可以通过PromQL进行查询,通过Grafana可以展示丰富的图表数据。
从上述组件可以看出:Prometheus提供了收集数据->存储数据->处理数据->展示数据这一系列功能,完全适用上述的应用场景。
获取监控数据的两种方式
- Pull:从监控的target通过轮询获取监控信息。主要是HTTP API。
- 告警可以按照策略分片,可以做到数据的冷热分离。
主要流程如下:
- Prometheus根据配置定期去targets拉取数据。
- 当拉取数据大于配置的内存缓冲区时,Prometheus会将数据持久化到磁盘或云端。
- Prometheus通过PromQL、API等方式获取数据,同时可以配置rules,当触发条件时,将alert推送到配置的alertmanager。
- alertmanager收到告警时,会执行相应的策略。
- Push:程序主动将数据推送到监控系统中,Prometheus采用gateway实现该方式。
- 实时性好
- 由于推送时机的不可预知性,监控系统无法掌握主动性,可能会导致对监控进程产生影响。
- 增加gateway组件,增加了系统的复杂度。
优缺点
优点:
- Golang编写,支持云原生,二进制文件直接启动,也支持容器化部署。
- 支持多种语言的客户端。
- 支持本地存储和云端存储,单机性能强。
- 可扩展,使用联邦集群启动多个Prometheus实例来分布式处理。
- 支持静态文件配置和动态发现等机制。
缺点:
- 不适用Logging、Tracing等监控。
- Prometheus数据默认保留15天,适用于追踪近期数据。
- 本地存储有限,需要考虑第三方存储。
- 联邦集群没有提供统一的全局视图。
Grafana简介
Grafana是一个可以通过各种图形方式对数据进行可视化的一个开源软件,官网简介如下:
Query, visualize, alert on, and understand your data no matter where it’s stored. With Grafana you can create, explore and share all of your data through beautiful, flexible dashboards.
部署
安装Prometheus Server
cd /opt
wget https://github.com/prometheus/prometheus/releases/download/v2.36.1/prometheus-2.36.1.linux-amd64.tar.gz
# 解压后进入目录,运行时指定配置文件和data路径
./prometheus --config.file=prometheus.yml --storage.tsdb.path=/data/prometheus运行成功后,浏览器访问http://localhost:9090可以看到Prometheus自带的Web
UI。可以在此界面通过PormQL查询数据。
注意:在配置prometheus.yml的过程中,可能会出错,可以通过下面的指令检查配置文件的正确性。
./promtool check config prometheus.yml
配置web认证
安装bcrypt:apt install python3-bcrypt,创建gen-pass.py,文件内容如下:
import getpass
import bcrypt
password = getpass.getpass("password: ")
hashed_password = bcrypt.hashpw(password.encode("utf-8"), bcrypt.gensalt())
print(hashed_password.decode())执行python3 gen-pass.py生成加密的password,创建web.yml并填入下述配置。
basic_auth_users:
admin: xxx可以使用./promtool check web-config web.yml对其进行验证。
最后,在运行时,指定web.yml即可。
./prometheus --config.file=prometheus.yml --storage.tsdb.path=/data/prometheus --web.config.file=web.yml安装Node Exporter
Exporter主要是采集数据的组件,Node Exporter是Prometheus官方提供用于采集主机运行指标,例如CPU、内存、硬盘等信息。
wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
# 解压后进入文件夹
./node_exporter运行成功后,访问http://47.102.201.28:9100/metrics可以看到监控信息。
返回Prometheus,在prometheus.yml中加入如下配置,相当于将node
exporter监控数据纳入Prometheus定时抓取任务中。
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']上面的metrics会符合一定的格式,可以通过curl -s http://localhost:9090/metrics | promtool check metrics来对metrics进行检查,这对于自定义Exporter时,检查报错十分有用。
# HELP node_filesystem_size_bytes Filesystem size in bytes.
# TYPE node_filesystem_size_bytes gauge
node_filesystem_size_bytes{device="/dev/vda1",fstype="ext4",mountpoint="/"} 4.2140479488e+10
node_filesystem_size_bytes{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 2.07937536e+08
node_filesystem_size_bytes{device="tmpfs",fstype="tmpfs",mountpoint="/run/lock"} 5.24288e+06
node_filesystem_size_bytes{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/0"} 2.0793344e+08
# HELP node_forks_total Total number of forks.
# TYPE node_forks_total counter
node_forks_total 279283上面是一段metrics数据,下面简单解释一下:
HELP:解释当前指标的含义
TYPE:说明当前指标的数据类型。分别有以下几种类型(后续详细介绍)
node_filesystem_size_bytes:指标名称。
大括号内部为label,负责对指标做进一步说明。
安装Grafana
- DashBoard:看板,其中包含多个panel。
- Panel:图表,每个图表展示
- 预览区:预览设置的图表。
- 数据设置区:设置数据源、数据指标等。
- 查询:设置查询数据的数据源、指标等。
- 转换:对查询出来的数据进行过滤。
- 告警:对指标设置告警规则。
- 图表设置区:设置图表等信息。
监控告警
Prometheus提供了AlertManager来管理告警,我在构建监控系统过程中,使用Grafana配置告警规则,Grafana中的告警,可以结合图表展示出来。
添加邮件配置
Grafana的默认配置文件为conf/default.ini,在其中添加如下配置:
[smtp]
enabled = true
host = smtp.exmail.qq.com:465
user = xxx@qq.com
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password = xxxx
cert_file =
key_file =
skip_verify = false
from_address = xxx@qq.com //必须与上面的 user 属性一致
from_name = Grafana
ehlo_identity =配置完成后,重启Grafana。
在Alerting-Notification channels添加告警频道填写后可以测试发送。
PormQL
基本概念
时间序列
时间序列(time
series)通过metrics name和一组label set来命名的。
样本
Prometheus将所有采集的数据以时间序列保存在内存中的时序数据库(TSDB)中,并定时存储到磁盘上。存储单位是:时间序列(time-series),时间序列按照时间戳和值顺序排放,每条时间序列通过metrics name和label set唯一指定。
时间序列中的值称为样本(sample),样本基于BigTable设计的格式存储,其由以下三部分组成:
- 指标(metrics):
metrics name和label set组成。- 指标名和标签名必须符合正则
[a-zA-Z_:][a-zA-Z0-9_:]*
- 指标名和标签名必须符合正则
- 时间戳(timestamp):64bit
- 样本值:64bit,float64格式。
数据类型
- 瞬时向量:一组时间序列,每个序列包含单个样本,共享相同的时间戳。
- 区间向量:一组时间序列,每个事件序列包含一段时间范围内的样本数据。
- 标量:一个浮点型的数据值,没有时序。
- 字符串
Metrics类型
- Counter:计数器,只增不减,例如:HTTP请求量。
- Gauge:可增可减的数据,例如:空闲内存情况。
- Histogram:直方图,对监控指标进行抽样,展示数据分布频率情况。
- Summary:和直方图类似,区别是summary在客户端完成聚合,Histogram在服务端完成。
基础语法
PormQL是Prometheus内置的数据查询语言,提供了对时间序列数据查询、聚合、运算等支持。
直接输入metrics name可以查询该指标的所有时间序列。
http_requests_total匹配模式
- =
- !=
- ~=
分别是完全匹配、完全不匹配、正则匹配。
http_requests_total{instance="localhost:9090"}
http_requests_total{environment=~"development",method!="GET"}范围查询
上述查询的数据都被称为瞬时向量,如果查询过去一段时间范围内的数据,需要使用范围查询,使用时间范围选择器进行定义。
# 查询最近五分钟的指标数据
http_requests_total{}[5m]时间选择器支持以下的时间单位:
- s-秒
- m-分
- h-小时
- d-天
- w-周
- y-年
使用offset可以实现时间偏移,如下:
# 查询昨天一天的数据
http_request_total{}[1d] offset 1d运算
支持以下运算:
数学运算:
+ - * / % ^
布尔运算:
== != > < >= <=
# bool修饰符将结果返回true or false
# 判断http请求量是否超过1000
http_requests_total > bool 1000
集合运算:
- vector1 and vector2:产生一个新向量,两者交集。
- vector1 or vector2:两者并集。
- vector1 unless vector2:vector1中没有vector2的元素。
聚合操作
提供了以下的聚合函数:
sum()、min()、max()、avg()、stddev(标准差)、stdvar(标准方差)、count()、count_values(对value进行计数)、bottomk(后n条时序)、topk(前n条时序)、quantile(分位数)without用于从结果中移除指定标签,by则是只保留列出的标签,其他全部移除。
sum(http_requests_total) without (instance)Exporter
Exporter是Prometheus中提供监控数据的程序,每个exporter的实例被称为target,Prometheus通过轮询的方式定期从target中获取数据。
Prometheus官方提供了主流产品的Exporter程序,同时可以基于其提供的Client Library创建自己的Exporter。官方支持语言有:Go、Java、Python、Ruby。
Java自定义Exporter
TODO
存储
Prometheus 2.x使用字定义的存储格式将数据存储在磁盘中,两小时内的数据存储在一个block中,每个block包含该时间段内所有chunks(样本数据)、metadata(元数据)、index(索引)。
收集的样本数据首先保存在内存,使用WAL机制防止丢失数据。