OSTEP阅读笔记- Concurrency(二)
Chapter 26 并发介绍
本章介绍为单个运行进程提供的新抽象:thread。线程共享地址空间。
每个线程都有自己的PC与自己用于计算的register。如果有两个线程运行在同一个处理器上,发生context switch时,与进程不同的是,使用PCB保存进程状态,使用TCB保存线程状态。区别是:地址空间保持不变(不需要切换当前使用的页表)。
另一个主要区别在于栈,传统进程只有一个栈,如图26.1所示:
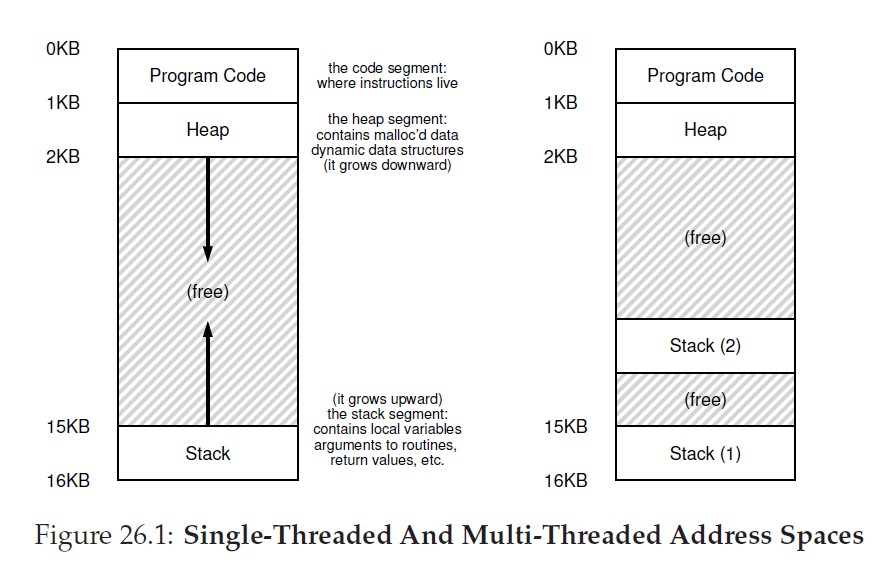
多线程中,每个线程拥有自己的栈,位于栈上的变量、参数、返回值是无法共享的。
26.1 实例:线程创建
示例:使用pthead_create()创建了两个线程,主程序调用pthread_join()等待指定线程执行完成。
线程的执行顺序取决于系统调度。

26.2 共享数据导致的问题
多线程对共享数据进行操作会导致非预期结果。
26.3 核心问题:不可控的调度
竞态条件(race condition):结果取决于代码的执行顺序。运气不好会导致错误的结果。
26.4 原子性
Q:如何构建有用的同步原语?需要从硬件中获取那些支持?
26.5 等待另一个线程
需要研究多线程中的wait/signal机制。
Chapter 27 线程API
Q:如何创建和控制线程?
27.1 pthread_create
在POSIX中:
#include <pthread.h>
int pthread_create( pthread_t * thread,
const pthread_attr_t * attr,
void * (*start_routine)(void*),
void * arg);参数:
- thread:指向pthread_t结构类型的指针,利用它与线程交互。
- attr:用于指定该线程可能具有的任何属性,包括设置栈大小、调度优先级。属性通过调用
pthread_attr_init()初始化。 - start_routine:一个函数指针,指示线程应该在哪个函数上运行。
- arg:传递给线程的参数
27.2 pthread_join
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);参数:
- thread:指定需要等待的线程
- retval:指向你希望得到的返回值,定义为一个指向void的指针。
27.3 锁
互斥进入临界区:
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);使用:
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&lock);
x = x + 1; // or whatever your critical section is
pthread_mutex_unlock(&lock);27.4 条件变量
当线程之间必须发生某种信号时,如果一个线程在等待另一个线程继续执行某些操作,条件变量就很有用。
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
int pthread_cond_signal(pthread_cond_t *cond);要使用条件变量,还需要一个与条件相关的锁。
- pthread_cond_wait:使调用线程进入休眠状态,等待其他线程发出信号。
- pthread_cond_signal:唤醒线程
补充:线程API使用指导
- 保持简洁
- 让线程交互减到最少
- 初始化锁和条件变量
- 检查返回值
- 注意传给线程的参数和返回指
- 每个线程都有自己的栈
- 线程之间通过条件变量发送信号
- 多查手册
Chapter 28 锁
并发编程的基本问题:希望原子式执行一系列指令,但是由于处理器中断,无法做到。
锁可以保证在临界区能够保证原子性。
28.1 锁的基本思想
锁就是一个变量,因此需要声明才能使用,锁变量保存了锁在某一时刻的状态,要么是可用的:表示没有线程持有锁,要么是被占用的:表示有线程持有锁。也可以访问其他信息:比如查询持有锁的线程,或请求获取锁的线程队列。
- lock:尝试获取锁,如果没有其他线程持有锁,该线程会获得锁,进入临界区,并成为锁的持有者。
- unlock:持有者一旦调用
unlock(),锁就会变成可用,如果没有其他等待线程。
28.4 评价锁
如何评价一种锁实现的效果?
标准:
- 第一:锁是否能实现互斥
- 第二:公平性
- 第三:性能
28.5 控制中断
最早提供的互斥解决方案之一就是在临界区关闭中断。这个解决方案是为单处理器系统开发的。优点是简单。
缺点:
- 不安全的操作,允许任何线程进行关中断
- 不支持多处理器,如果多个线程运行在不同的CPU上,每个线程都试图进入同一临界区。
- 关闭中断导致中断丢失,比如磁盘设备完成读取任务,但是CPU无法识别到中断
- 效率低
28.6 测试并设置指令 原子交换
由于关中断方式无法在多处理器上运行,所以需要让硬件支持,最简单的硬件支持是测试并设置(test-and-set),也称为原子交换(atomic exchange)。
通过自旋等待,直到持有锁的线程释放资源。

上述代码有两个问题:
- 正确性
- 无法互斥
- 性能
- 自旋等待性能开销大
28.7 实现可用的自旋锁
没有硬件支持是无法实现的,因此产生了一些指令,在x86中,是xchg指令。其功能是返回旧值,更新为新值,C代码描述如下:
int testAndSet(int *old_ptr, int new){
int old = * old_ptr;
*old_ptr = new;
return old;
}可以利用这个指令完成一个简单的spin lock。

此方法与28.1中的实现区别在于:获取并更新两个操作是原子性的,并不会存在同时进入临界区的时机。
这也是此方法能完成互斥功能的关键。
28.8 评价自旋锁
- 正确性:能够互斥
- 公平性:自旋锁没有公平性,会导致线程饥饿
- 性能
- 单处理器:性能开销大
- 多处理器:性能不错
28.9 CAS
比较并交换指令(compare-and-set),C代码描述如下:
int compareAndSet(int * ptr, int expected, int new){
int actual = *ptr;
if(actual == expected)
*ptr = new;
return actual;
}可以使用该指令改写lock()。
void lock(lock_t *lock){
while(compareAndSet(&lock->flag,0,1) == 1)
;//spin
}X86的CAS指令如下:

28.10 链接的加载和条件式存储指令
链接的加载指令:从内存中取出值。
条件式存储指令:只有上一次加载的地址在期间都没有更新时,才会成功。

使用这两个指令如何实现一个锁?

28.11 获取并增加
获取并增加:它能原子性的返回特定地址的旧值,并将值自增1,C代码如下:
int fetchAndAdd(int * ptr){
int old = *ptr;
*ptr = old + 1;
return old;
}可以通过此指令完成一个ticket锁:
typedef struct lock_t{
int ticket;
int turn;
}
void lock_init(lock_t *lock){
lock->ticket = 0;
lock->turn = 0;
}
void lock(lock_t *lock){
int myturn = fetchAndAdd(&lock->ticket);
while(lock->turn!= myturn)
;//spin
}
void unlock(lock_t *lock){
fetchAndAdd(&lock->turn);
}通过检查turn字段与获取的ticket是否相等,判断是否可以进入临界区。
不同于之前的方法,本方法能保证所有线程都能获取锁,而不会导致某一个线程饥饿。
28.12 自旋过多:怎么办
Q:这样避免自旋浪费CPU时间?
28.13 简单方法:让出CPU
void lock(){
while(testAndSet(&flag, 1) == 1)
yield();
}调用yield()让线程主动放弃CPU。
但是如果线程数量多,采用此方法会导致context switch成本提高。
同时还会有线程饥饿问题,一个线程可能一直处在让出CPU的循环,而其他线程反复进入临界区。
28.14 使用队列:休眠代替自旋
如图28.9所示:

28.15 Linux的fulex锁
利用一个整数,同时利记录锁是否被持有(整数的最高位),以及等待者的个数(整数的其它位)。
因此整数如果是负数,则处于被持有状态(有符号整数,高位为1为负数)。

28.16 两阶段锁
两阶段锁的第一阶段会先自旋一段时间,希望可以获得锁。但是如果自旋阶段没有获得锁,第二阶段调用者会睡眠,直到锁可用。
Chapter 29 基于锁的并发数据结构
Q:如何给数据结构加锁,能够保证高性能,并实现线程安全?
29.1 并发计数器
如何实现一个线程安全的计数器?

但是通过锁保护线程安全影响性能。
如果多线程运行下的速率和单线程下一样,就将其称为完美扩展(perfect scaling)。
注:下文的扩展性是指,程序在并发环境下的性能优劣。
人们提出了懒惰计数器(sloopy counter),懒惰计数器通过多个局部计数器和一个全局计数器来实现一个逻辑计数器,其中每个CPU核心都有一个局部计数器,每个计数器都有一个锁保护线程安全。
基本思想:如果一个CPU上的线程想增加计数器,增加自己的局部计数器,访问局部计数器通过对应的局部锁同步的。全局计数器的值会定期更新,通过获取全局锁,然后加上局部计数器的值,并将其清空。
更新的频率取决去阈值$S$,$S$越小,懒惰计数器越趋向于非扩展的计数器,$S$越大,扩展性越强,但是全局计数器和局部计数器的偏差较大。图29.5是懒惰计数器的基本实现:

29.2 并发List

插入时检查是否发生内存分配错误,但是异常控制流容易产生错误。如何重写插入和查找函数?

上述的写法,在插入时,缩小了锁的粒度。但是扩展性不好。
hand-over-hand locking。:每个节点都有一个锁,代替了原来整个链表共享一个锁。遍历链表时,首先抢占下一个节点的锁,然后释放当前节点的锁。
但是这种方法的性能并不比单锁快。
29.3 并发Queue

特点:
- 入队只获取tail锁
- 出队只获取head锁
29.4 并发Hash
并发Hash中,每个桶都有一个锁。

Chapter 30 条件变量
很多情况下,线程需要检查某一condition满足之后,才会继续运行。
Q:线程应该如何等待一个条件?
30.1 定义和程序
线程可以使用condition variable,来等待一个条件变为真,条件变量是一个显式队列,当条件不满足时,线程把自己加入阻塞队列,进入阻塞状态,另外某个线程,当它改变了上述状态时,就可以唤醒一个或多个等待线程。
POSIX调用如图30.3所示:

那么done变量是否需要,下面的代码是否正确?

假设子线程立即运行,并且调用thr_exit(),在这种情况下,子线程发送信号,但是没有在条件变量上等待的线程,父线程运行时,就会调用wait()进入阻塞状态,并且没有其它线程唤醒它。
30.2 生产者/消费者问题
假设有一个或多个生产者线程和一个或多个消费者线程,生产者把生产的数据项放入缓冲区;消费者从缓冲区取走数据项,以某种方式进行消费。

30.3 覆盖条件
下面是一个多线程内存分配库的覆盖条件的例子:

当线程进入内存分配中时,它可能会因为内存不足而等待。线程释放内存后,会发出信号通知会有更多的内存空间,但是有一个问题:应该唤醒那个等待线程?
场景:线程$Ta$申请100 bytes内存,线程$Tb$申请10 bytes内存,但是当前无空闲内存可分配,$Ta$和$Tb$都等待在条件变量上。此时线程$Tc$调用了free(50),但是$Tc$如果唤醒$Ta$,那么$Ta$会因为内存不够继续等待。
因此可以使用pthread_cond_broadcast()代替上面的pthread_cond_signal()唤醒所有的等待线程。当然也有缺点:影响性能,不必要地唤醒了其他等待的线程。
这种条件变量称为覆盖条件(covering condition)。
Chapter 31 信号量
Q:如何使用信号量代替锁和条件变量?信号量的概念,不用锁和条件变量,如何实现信号量?
31.1 信号量的定义
信号量是一个整数型的对象,可以用两个函数来操作它,在POSIX标准中,分别是sem_wait()和sem_post()。含义分别如下:
- sem_wait:
- decrement the value of semaphore s by one
- wait it value of semaphore s is negative
- sem_post:
- increment the value of semphore s by one
- if there are one or more threads waiting, wake one
信号量如果为负数,那么绝对值就是等待线程的个数。
31.2 二值信号量
二值信号量就是锁。
31.3 信号量用作条件变量
信号量也可以用在一个线程暂停执行,等待某一条件成立的场景。例如:一个线程要等待一个链表非空,才能删除一个元素。此时可以将信号量作为条件变量。
31.4 生产者消费者问题

31.5 读写锁
如果某个线程需要进行更新操作,需要调用rwlock_acquire_lock()获得写锁,调用rwlock_release_writelock()释放锁,内部通过一个信号量保证只有一个写者能进入临界区。
读锁会通过reader变量追踪当前有多少个读者在访问该数据结构。
一旦一个读者获得了读锁,其他的读者也可以获得这个读锁。当时想要获取写锁的线程,必须等待所有的读者都结束。

31.6 哲学家就餐问题
基本问题:假设又五位哲学家围着一个圆桌,每两位哲学家之间有一把叉子,一位哲学家只有同时拿到了左手边和右手边的两把叉子才能吃到东西。如何解决同步问题。
每位哲学家的基本操作:
while(1) {
think();
getforks();
eat();
putforks();
}如何保证没有死锁,并且不会有哲学家饿死?
需要一些辅助函数:例如哲学家P希望用左手边的叉子,他会调用left(p),右手边的叉子调用right(p)。
int left(int p){return p};
int right(int p){return (p + 1) % 5 ;}第一次尝试
将每个信号量都设置为1
void getforks(){
sem_wait(forks[left(p)]);
sem_wait(forks[right(p)]);
}
void putforks() {
sem_post(forks[left(p)]);
sem_post(forks[right(p)]);
}步骤是依次获取每把叉子的锁,先获取左手边的。
这个方案是有问题的,如果每个哲学家都拿到了左手边的叉子,他们会被阻塞,并一直等待另一只叉子。
破除依赖
如何解决? 修改某个哲学家的取叉子顺序。
void getforks() {
if(p == 4){
sem_wait(forks[right(p)]);
sem_wait(forks[left(p)]);
}else{
sem_wait(forks[left(p)]);
sem_wait(forks[right(p)]);
}
}31.7 如何实现信号量

Chapter 32 常见并发问题
Q:如何处理常见的并发缺陷?
32.1 有哪些类型的缺陷
死锁和非死锁。
32.2 非死锁缺陷
- 反原子性
- 错误顺序缺陷
违反原子性缺陷

这是MySQL中出现的例子,两个线程都要访问thd中的proc_info,第一个线程检查proc_info非空,然后打印值,第二个线程设置其为空,当第一个线程恢复执行时,会由于空指针而报错。
解决方案很简单,将共享变量的访问加锁,确保串行化访问变量。
违反顺序缺陷

线程2假定已经初始化了,然而如果线程1没有首先执行,线程2则会因为空指针报错。
如何解决? 保证执行顺序不被打破。
可以使用条件变量解决。
32.3 死锁缺陷
线程1持有锁L1,线程2持有锁L2,线程1请求L2,线程2请求L1。
Q:如何应对死锁?
发生的原因
- 大型项目中,组件之间有复杂的依赖。
- 封装会隐藏实现细节,会让人忽视。
产生死锁的条件
- 互斥:线程对于需要的资源进行互斥访问。
- 持有并等待:线程持有了资源。
- 非抢占:线程获得的资源,不能被抢占。
- 循环等待:线程之间存在一个环路,环路上的每个线程都额外持有一个资源,而这个资源又是下一个线程要申请的。
预防
从循环等待条件解决:让代码不会产生循环等待,最直接的方法就是获取锁时提供一个全序,偏序也是一种有用的方法,Linux中内存映射就是一个偏序锁的好例子。
从持有并等待条件解决:通过原子性地抢锁来避免。
从非抢占条件解决:可以通过
tryLock()解决问题。从互斥条件解决:方法是完全避免互斥,但是代码总会存在临界区,因此很难避免互斥。
- 可以使用lock-free,通过强大地硬件指令,可以构造出不需要锁的数据结构。
通过调度避免死锁
检查和恢复
允许死锁偶尔发生,检查到死锁时再采取行动。
很多数据库系统使用了死锁检测和恢复技术,死锁检测器会定期运行,通过构建资源图来检查循环。
Chapter 33 基于事件的并发
Q:不用线程,同时保证对并发的控制,如何构建并发服务器?
33.1 基本想法:事件循环
使用的基本的方法是基于事件的并发。该方法很简单:等待某事发生。当它发生时,检查事件类型,然后做少量的相应工作。
想看一个典型的基于事件的服务器,这种应用被称为事件循环:
while(1) {
events = getEvents();
for(e in events)
processEvent(e);
}这也带来了问题:基于事件的服务器如何决定哪个事件发生,尤其是对于网络和磁盘IO?时间服务器如何确定是否有它的消息已经到达?
33.2 重要API:select()
大多数OS提供了基本的API决定如何接收事件。即通过select()或poll()系统调用。
这些接口对程序的支持很简单:检查是否有任何应该关注的进入I/O。假定网络程序希望检查是否有网络数据包已到达,以便为它们提供服务,
int select(int nfds,
fd_set *restrict readfds,
fd_set *restrict writefds,
fd_set *restrict errorfds,
struct timeval *restrict timeout);select()检查I/O描述符集合,它们的地址通过readfds、writefds、errorfds传入,分别查看它们中的某些描述符是否已准备好读取,是否准备好写入,或者异常情况待处理。在每个集合中检查前nfds个描述符,返回时,select()用给定请求操作准备好的描述符组成的子集替换给定的描述符集合。select()返回所有集合中就绪描述符的总数。
- 阻塞接口:在返回给调用者之前完成所有工作。
- 非阻塞接口:开始一些工作后立即返回,从而让所有需要完成的工作都在后台完成。
33.3 使用select()

- 使用
FD_ZERO()宏首先清除文件描述符集合。 - 使用
FD_SET()将所有从minFD到maxFD的文件描述符包含到集合中。- 例如,这组描述符可能表示服务器正在关注的所有网络套接字。
- 最后,服务器调用
select()来查看哪些连接有可用的数据。 - 然后通过在循环中使用
FD_ISSET(),事件服务器可以查看哪些描述符已准备好数据并处理传入的数据。
33.4 无需锁
使用单个CPU和基于事件的应用程序,也就不存在并发问题。具体来说,因为一次只处理一个事件,所以不需要锁来保护指定对象。
33.5 阻塞系统调用
如果某个事件要求你发出可能会阻塞的系统调用,该怎么办?
例如:一个请求进入服务器,要求磁盘读取文件并将内容返回到客户端。为了处理这样的请求,需要发出open()系统调用打开文件,read()读取文件。
由于IO操作远慢于CPU,因此需要很长时间才能提供服务。
在基于事件的方法中,事件循环阻塞时,系统会处于闲置状态,并不会读取新事件。曹诚资源浪费。
因此,在基于事件的系统中必须:不允许阻塞调用。
33.6 解决方案:异步I/O
异步I/O(asynchronous I/O):发出I/O请求后,在I/O完成之前立即将控制权返回给调用者,另外的接口让应用程序能够确定各种I/O是否已完成。
macOS中提供了AIO的接口,这些API围绕着一个基本结构:
struct aiocb{
int aio_fildes;
off_t aio_offset;
volatile void *aio_buf;
size_t aio_nbytes;
}要发起AIO请求,应用程序首先用相关信息填充此结构:
- aio_fildes:要读取文件的文件描述符
- aio_offset:文件内的偏移量
- aio_buf:复制读取结果的目标内存位置
- aio_nbytes:读取长度
通过aio_read()进行异步读取。
int aio_read(struct aiocb * aiocbp);如何知道IO何时完成,并且缓冲区现在有了请求的数据?
aio_error()检查aiocbp应用的请求是否已完成。
int aio_error(const struct aiocb * aiocbp);因此,检查AIO是否已经完成需要轮询。为了解决这个问题,一些系统提供了基于中断的方法,此方法使用UNIX信号(signal)在异步IO完成时通知应用程序,从而消除了轮询的需要。
33.7 另一个问题:状态管理
基于事件的方法存在另一个问题:代码比传统的基于线程的复杂。
原因在于:需要手动的管理事件IO状态,基于线程的程序不需要,因为时线程栈自动管理。